 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Sufficient Goal Representations
Jan 30, 2026Hierarchical policies in offline goal-conditioned reinforcement learning (GCRL) addresses long-horizon tasks by decomposing control into high-level subgoal planning and low-level action execution. A critical design choice in such architectures is the goal representation-the compressed encoding of goals that serves as the interface between these levels. Existing approaches commonly derive goal representations while learning value functions, implicitly assuming that preserving information sufficient for value estimation is adequate for optimal control. We show that this assumption can fail, even when the value estimation is exact, as such representations may collapse goal states that need to be differentiated for action learning. To address this, we introduce an information-theoretic framework that defines action sufficiency, a condition on goal representations necessary for optimal action selection. We prove that value sufficiency does not imply action sufficiency and empirically verify that the latter is more strongly associated with control success in a discrete environment. We further demonstrate that standard log-loss training of low-level policies naturally induces action-sufficient representations. Our experimental results a popular benchmark demonstrate that our actor-derived representations consistently outperform representations learned via value estimation.
Reset & Distill: A Recipe for Overcoming Negative Transfer in Continual Reinforcement Learning
Mar 08, 2024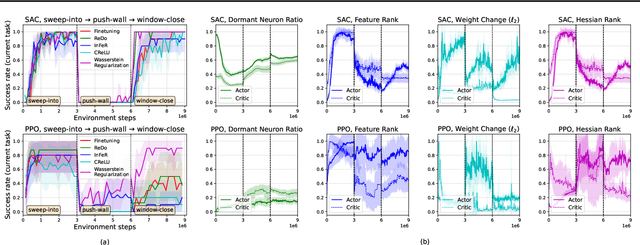
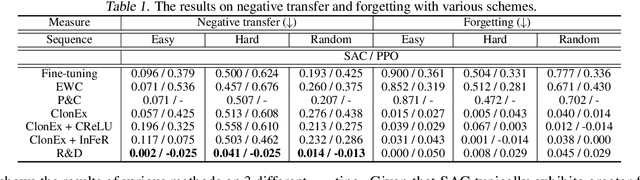
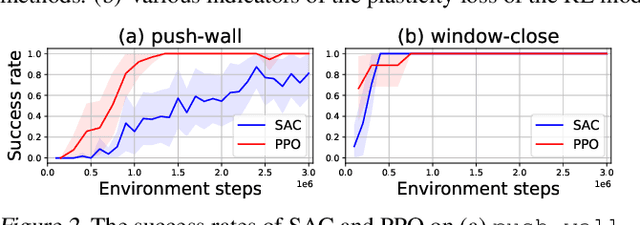
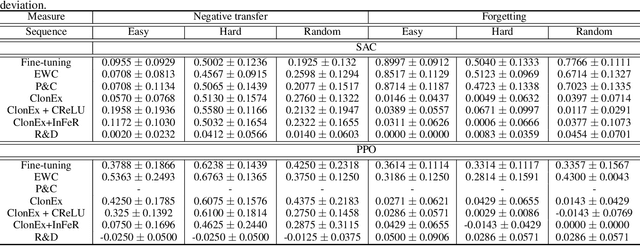
We argue that one of the main obstacles for developing effective Continual Reinforcement Learning (CRL) algorithms is the negative transfer issue occurring when the new task to learn arrives. Through comprehensive experimental validation, we demonstrate that such issue frequently exists in CRL and cannot be effectively addressed by several recent work on mitigating plasticity loss of RL agents. To that end, we develop Reset & Distill (R&D), a simple yet highly effective method, to overcome the negative transfer problem in CRL. R&D combines a strategy of resetting the agent's online actor and critic networks to learn a new task and an offline learning step for distilling the knowledge from the online actor and previous expert's action probabilities. We carried out extensive experiments on long sequence of Meta-World tasks and show that our method consistently outperforms recent baselines, achieving significantly higher success rates across a range of tasks. Our findings highlight the importance of considering negative transfer in CRL and emphasize the need for robust strategies like R&D to mitigate its detrimental effects.