 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Linear Dueling Bandits with Post-serving Context under Unknown Delays and Adversarial Corruptions
May 03, 2026We study linear dueling bandits in volatile environments characterized by the simultaneous presence of post-serving contexts, delayed feedback, and adversarial corruption. Feedback is subject to unknown stochastic or adversarial delays and a cumulative corruption budget $\mathcal{C}$. To address these challenges, we propose \term, which integrates a learned approximator that predicts post-serving contexts from pre-serving information. It further employs an adaptive weighting strategy that clips feature vectors to mitigate the impact of corrupted and delayed observations simultaneously. Under standard regularity conditions and a parametric post-serving mapping, we rigorously establish that our algorithm is delay-regime-agnostic, achieving a regret upper bound of $\widetilde{\mathcal{O}}(d(\sqrt{T} + \mathcal{C} + \mathcal{D}))$, where $d$ is the total feature dimension and $\mathcal{D}$ encapsulates the delay complexity. Crucially, our analysis reveals an additive cost structure between corruption and delay, avoiding the multiplicative degradation typical of prior works. We further establish lower bounds that nearly match our upper bounds up to a $\sqrt{d}$ factor for adversarial delays in the absence of post-serving contexts.
Task Prototype-Based Knowledge Retrieval for Multi-Task Learning from Partially Annotated Data
Jan 12, 2026Multi-task learning (MTL) is critical in real-world applications such as autonomous driving and robotics, enabling simultaneous handling of diverse tasks. However, obtaining fully annotated data for all tasks is impractical due to labeling costs. Existing methods for partially labeled MTL typically rely on predictions from unlabeled tasks, making it difficult to establish reliable task associations and potentially leading to negative transfer and suboptimal performance. To address these issues, we propose a prototype-based knowledge retrieval framework that achieves robust MTL instead of relying on predictions from unlabeled tasks. Our framework consists of two key components: (1) a task prototype embedding task-specific characteristics and quantifying task associations, and (2) a knowledge retrieval transformer that adaptively refines feature representations based on these associations. To achieve this, we introduce an association knowledge generating (AKG) loss to ensure the task prototype consistently captures task-specific characteristics. Extensive experiments demonstrate the effectiveness of our framework, highlighting its potential for robust multi-task learning, even when only a subset of tasks is annotated.
GrowTAS: Progressive Expansion from Small to Large Subnets for Efficient ViT Architecture Search
Dec 13, 2025Transformer architecture search (TAS) aims to automatically discover efficient vision transformers (ViTs), reducing the need for manual design. Existing TAS methods typically train an over-parameterized network (i.e., a supernet) that encompasses all candidate architectures (i.e., subnets). However, all subnets share the same set of weights, which leads to interference that degrades the smaller subnets severely. We have found that well-trained small subnets can serve as a good foundation for training larger ones. Motivated by this, we propose a progressive training framework, dubbed GrowTAS, that begins with training small subnets and incorporate larger ones gradually. This enables reducing the interference and stabilizing a training process. We also introduce GrowTAS+ that fine-tunes a subset of weights only to further enhance the performance of large subnets. Extensive experiments on ImageNet and several transfer learning benchmarks, including CIFAR-10/100, Flowers, CARS, and INAT-19, demonstrate the effectiveness of our approach over current TAS methods
PPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Jul 22, 2025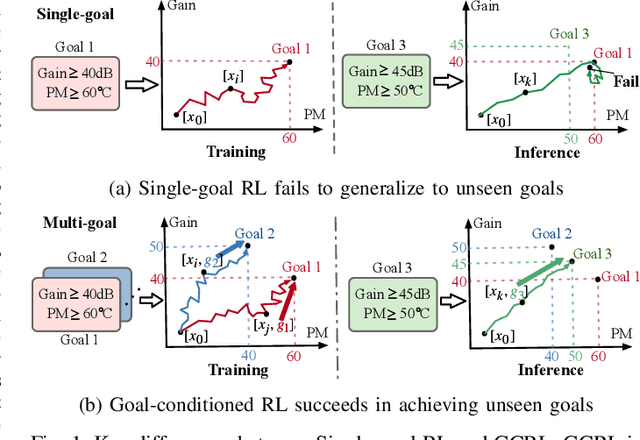
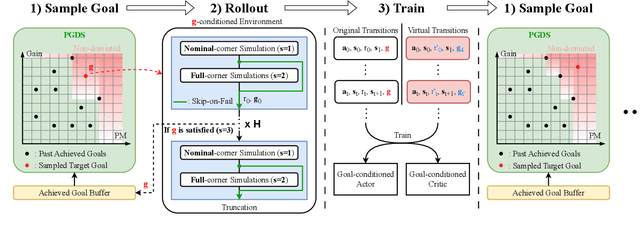
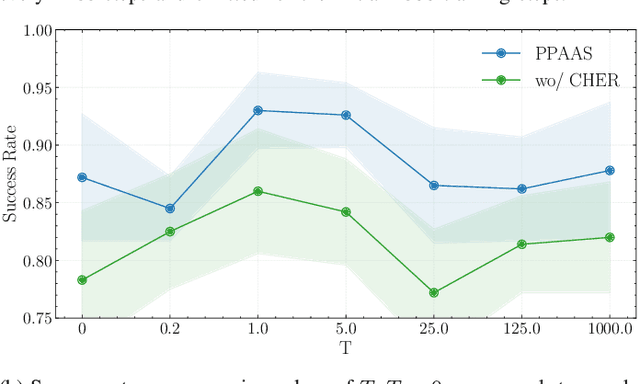
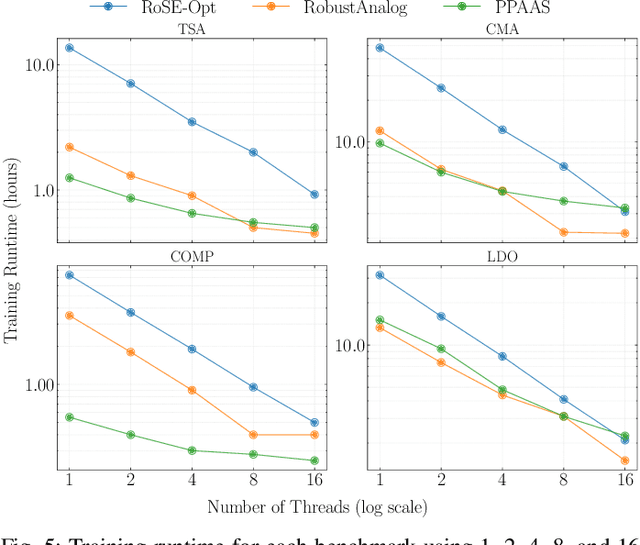
Device sizing is a critical yet challenging step in analog and mixed-signal circuit design, requiring careful optimization to meet diverse performance specifications. This challenge is further amplified under process, voltage, and temperature (PVT) variations, which cause circuit behavior to shift across different corners. While reinforcement learning (RL) has shown promise in automating sizing for fixed targets, training a generalized policy that can adapt to a wide range of design specifications under PVT variations requires much more training samples and resources. To address these challenges, we propose a \textbf{Goal-conditioned RL framework} that enables efficient policy training for analog device sizing across PVT corners, with strong generalization capability. To improve sample efficiency, we introduce Pareto-front Dominance Goal Sampling, which constructs an automatic curriculum by sampling goals from the Pareto frontier of previously achieved goals. This strategy is further enhanced by integrating Conservative Hindsight Experience Replay, which assigns relabeled goals with conservative virtual rewards to stabilize training and accelerate convergence. To reduce simulation overhead, our framework incorporates a Skip-on-Fail simulation strategy, which skips full-corner simulations when nominal-corner simulation fails to meet target specifications. Experiments on benchmark circuits demonstrate $\sim$1.6$\times$ improvement in sample efficiency and $\sim$4.1$\times$ improvement in simulation efficiency compared to existing sizing methods. Code and benchmarks are publicly available at https://github.com/SeunggeunKimkr/PPAAS
Subnet-Aware Dynamic Supernet Training for Neural Architecture Search
Mar 13, 2025N-shot neural architecture search (NAS) exploits a supernet containing all candidate subnets for a given search space. The subnets are typically trained with a static training strategy (e.g., using the same learning rate (LR) scheduler and optimizer for all subnets). This, however, does not consider that individual subnets have distinct characteristics, leading to two problems: (1) The supernet training is biased towards the low-complexity subnets (unfairness); (2) the momentum update in the supernet is noisy (noisy momentum). We present a dynamic supernet training technique to address these problems by adjusting the training strategy adaptive to the subnets. Specifically, we introduce a complexity-aware LR scheduler (CaLR) that controls the decay ratio of LR adaptive to the complexities of subnets, which alleviates the unfairness problem. We also present a momentum separation technique (MS). It groups the subnets with similar structural characteristics and uses a separate momentum for each group, avoiding the noisy momentum problem. Our approach can be applicable to various N-shot NAS methods with marginal cost, while improving the search performance drastically. We validate the effectiveness of our approach on various search spaces (e.g., NAS-Bench-201, Mobilenet spaces) and datasets (e.g., CIFAR-10/100, ImageNet).
Efficient Few-Shot Neural Architecture Search by Counting the Number of Nonlinear Functions
Dec 19, 2024Neural architecture search (NAS) enables finding the best-performing architecture from a search space automatically. Most NAS methods exploit an over-parameterized network (i.e., a supernet) containing all possible architectures (i.e., subnets) in the search space. However, the subnets that share the same set of parameters are likely to have different characteristics, interfering with each other during training. To address this, few-shot NAS methods have been proposed that divide the space into a few subspaces and employ a separate supernet for each subspace to limit the extent of weight sharing. They achieve state-of-the-art performance, but the computational cost increases accordingly. We introduce in this paper a novel few-shot NAS method that exploits the number of nonlinear functions to split the search space. To be specific, our method divides the space such that each subspace consists of subnets with the same number of nonlinear functions. Our splitting criterion is efficient, since it does not require comparing gradients of a supernet to split the space. In addition, we have found that dividing the space allows us to reduce the channel dimensions required for each supernet, which enables training multiple supernets in an efficient manner. We also introduce a supernet-balanced sampling (SBS) technique, sampling several subnets at each training step, to train different supernets evenly within a limited number of training steps. Extensive experiments on standard NAS benchmarks demonstrate the effectiveness of our approach. Our code is available at https://cvlab.yonsei.ac.kr/projects/EFS-NAS.
M3: Mamba-assisted Multi-Circuit Optimization via MBRL with Effective Scheduling
Nov 25, 2024



Recent advancements in reinforcement learning (RL) for analog circuit optimization have demonstrated significant potential for improving sample efficiency and generalization across diverse circuit topologies and target specifications. However, there are challenges such as high computational overhead, the need for bespoke models for each circuit. To address them, we propose M3, a novel Model-based RL (MBRL) method employing the Mamba architecture and effective scheduling. The Mamba architecture, known as a strong alternative to the transformer architecture, enables multi-circuit optimization with distinct parameters and target specifications. The effective scheduling strategy enhances sample efficiency by adjusting crucial MBRL training parameters. To the best of our knowledge, M3 is the first method for multi-circuit optimization by leveraging both the Mamba architecture and a MBRL with effective scheduling. As a result, it significantly improves sample efficiency compared to existing RL methods.
MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection
Jul 23, 2024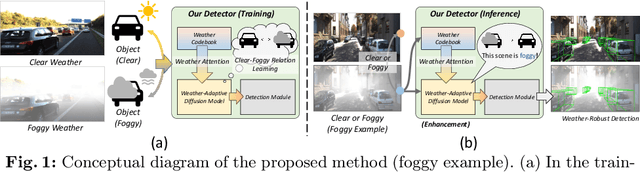
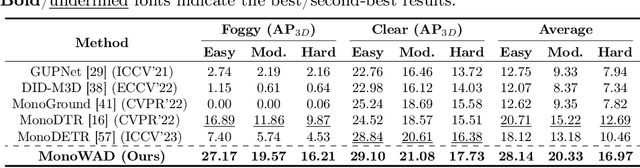
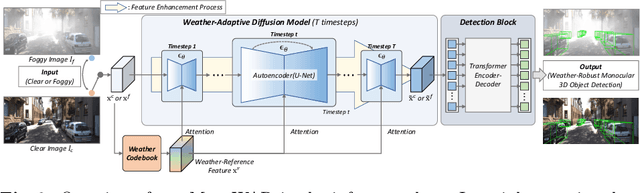
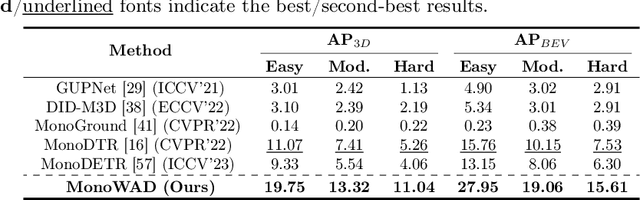
Monocular 3D object detection is an important challenging task in autonomous driving. Existing methods mainly focus on performing 3D detection in ideal weather conditions, characterized by scenarios with clear and optimal visibility. However, the challenge of autonomous driving requires the ability to handle changes in weather conditions, such as foggy weather, not just clear weather. We introduce MonoWAD, a novel weather-robust monocular 3D object detector with a weather-adaptive diffusion model. It contains two components: (1) the weather codebook to memorize the knowledge of the clear weather and generate a weather-reference feature for any input, and (2) the weather-adaptive diffusion model to enhance the feature representation of the input feature by incorporating a weather-reference feature. This serves an attention role in indicating how much improvement is needed for the input feature according to the weather conditions. To achieve this goal, we introduce a weather-adaptive enhancement loss to enhance the feature representation under both clear and foggy weather conditions. Extensive experiments under various weather conditions demonstrate that MonoWAD achieves weather-robust monocular 3D object detection. The code and dataset are released at https://github.com/VisualAIKHU/MonoWAD.
FYI: Flip Your Images for Dataset Distillation
Jul 11, 2024
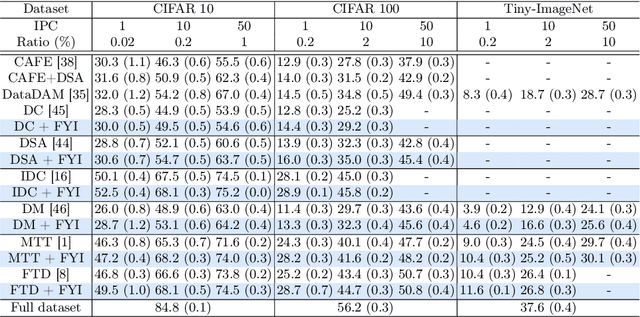


Dataset distillation synthesizes a small set of images from a large-scale real dataset such that synthetic and real images share similar behavioral properties (e.g, distributions of gradients or features) during a training process. Through extensive analyses on current methods and real datasets, together with empirical observations, we provide in this paper two important things to share for dataset distillation. First, object parts that appear on one side of a real image are highly likely to appear on the opposite side of another image within a dataset, which we call the bilateral equivalence. Second, the bilateral equivalence enforces synthetic images to duplicate discriminative parts of objects on both the left and right sides of the images, limiting the recognition of subtle differences between objects. To address this problem, we introduce a surprisingly simple yet effective technique for dataset distillation, dubbed FYI, that enables distilling rich semantics of real images into synthetic ones. To this end, FYI embeds a horizontal flipping technique into distillation processes, mitigating the influence of the bilateral equivalence, while capturing more details of objects. Experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet demonstrate that FYI can be seamlessly integrated into several state-of-the-art methods, without modifying training objectives and network architectures, and it improves the performance remarkably.
INSIGHT: Universal Neural Simulator for Analog Circuits Harnessing Autoregressive Transformers
Jul 10, 2024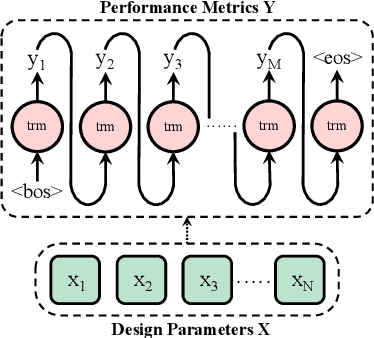



Analog front-end design heavily relies on specialized human expertise and costly trial-and-error simulations, which motivated many prior works on analog design automation. However, efficient and effective exploration of the vast and complex design space remains constrained by the time-consuming nature of CPU-based SPICE simulations, making effective design automation a challenging endeavor. In this paper, we introduce INSIGHT, a GPU-powered, technology-independent, effective universal neural simulator in the analog front-end design automation loop. INSIGHT accurately predicts the performance metrics of analog circuits across various technology nodes, significantly reducing inference time. Notably, its autoregressive capabilities enable INSIGHT to accurately predict simulation-costly critical transient specifications leveraging less expensive performance metric information. The low cost and high fidelity feature make INSIGHT a good substitute for standard simulators in analog front-end optimization frameworks. INSIGHT is compatible with any optimization framework, facilitating enhanced design space exploration for sample efficiency through sophisticated offline learning and adaptation techniques. Our experiments demonstrate that INSIGHT-M, a model-based batch reinforcement learning framework that leverages INSIGHT for analog sizing, achieves at least 50X improvement in sample efficiency across circuits. To the best of our knowledge, this marks the first use of autoregressive transformers in analog front-end design.