 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDAP: Domain-Aware Prototype Learning for Federated Learning under Domain Shift
Apr 08, 2026Federated Learning (FL) enables decentralized model training across multiple clients without exposing private data, making it ideal for privacy-sensitive applications. However, in real-world FL scenarios, clients often hold data from distinct domains, leading to severe domain shift and degraded global model performance. To address this, prototype learning has been emerged as a promising solution, which leverages class-wise feature representations. Yet, existing methods face two key limitations: (1) Existing prototype-based FL methods typically construct a $\textit{single global prototype}$ per class by aggregating local prototypes from all clients without preserving domain information. (2) Current feature-prototype alignment is $\textit{domain-agnostic}$, forcing clients to align with global prototypes regardless of domain origin. To address these challenges, we propose Federated Domain-Aware Prototypes (FedDAP) to construct domain-specific global prototypes by aggregating local client prototypes within the same domain using a similarity-weighted fusion mechanism. These global domain-specific prototypes are then used to guide local training by aligning local features with prototypes from the same domain, while encouraging separation from prototypes of different domains. This dual alignment enhances domain-specific learning at the local level and enables the global model to generalize across diverse domains. Finally, we conduct extensive experiments on three different datasets: DomainNet, Office-10, and PACS to demonstrate the effectiveness of our proposed framework to address the domain shift challenges. The code is available at https://github.com/quanghuy6997/FedDAP.
Disentangled Concepts Speak Louder Than Words:Explainable Video Action Recognition
Nov 05, 2025Effective explanations of video action recognition models should disentangle how movements unfold over time from the surrounding spatial context. However, existing methods based on saliency produce entangled explanations, making it unclear whether predictions rely on motion or spatial context. Language-based approaches offer structure but often fail to explain motions due to their tacit nature -- intuitively understood but difficult to verbalize. To address these challenges, we propose Disentangled Action aNd Context concept-based Explainable (DANCE) video action recognition, a framework that predicts actions through disentangled concept types: motion dynamics, objects, and scenes. We define motion dynamics concepts as human pose sequences. We employ a large language model to automatically extract object and scene concepts. Built on an ante-hoc concept bottleneck design, DANCE enforces prediction through these concepts. Experiments on four datasets -- KTH, Penn Action, HAA500, and UCF-101 -- demonstrate that DANCE significantly improves explanation clarity with competitive performance. We validate the superior interpretability of DANCE through a user study. Experimental results also show that DANCE is beneficial for model debugging, editing, and failure analysis.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
PCBEAR: Pose Concept Bottleneck for Explainable Action Recognition
Apr 17, 2025Human action recognition (HAR) has achieved impressive results with deep learning models, but their decision-making process remains opaque due to their black-box nature. Ensuring interpretability is crucial, especially for real-world applications requiring transparency and accountability. Existing video XAI methods primarily rely on feature attribution or static textual concepts, both of which struggle to capture motion dynamics and temporal dependencies essential for action understanding. To address these challenges, we propose Pose Concept Bottleneck for Explainable Action Recognition (PCBEAR), a novel concept bottleneck framework that introduces human pose sequences as motion-aware, structured concepts for video action recognition. Unlike methods based on pixel-level features or static textual descriptions, PCBEAR leverages human skeleton poses, which focus solely on body movements, providing robust and interpretable explanations of motion dynamics. We define two types of pose-based concepts: static pose concepts for spatial configurations at individual frames, and dynamic pose concepts for motion patterns across multiple frames. To construct these concepts, PCBEAR applies clustering to video pose sequences, allowing for automatic discovery of meaningful concepts without manual annotation. We validate PCBEAR on KTH, Penn-Action, and HAA500, showing that it achieves high classification performance while offering interpretable, motion-driven explanations. Our method provides both strong predictive performance and human-understandable insights into the model's reasoning process, enabling test-time interventions for debugging and improving model behavior.
Adversarial Wear and Tear: Exploiting Natural Damage for Generating Physical-World Adversarial Examples
Mar 27, 2025



The presence of adversarial examples in the physical world poses significant challenges to the deployment of Deep Neural Networks in safety-critical applications such as autonomous driving. Most existing methods for crafting physical-world adversarial examples are ad-hoc, relying on temporary modifications like shadows, laser beams, or stickers that are tailored to specific scenarios. In this paper, we introduce a new class of physical-world adversarial examples, AdvWT, which draws inspiration from the naturally occurring phenomenon of `wear and tear', an inherent property of physical objects. Unlike manually crafted perturbations, `wear and tear' emerges organically over time due to environmental degradation, as seen in the gradual deterioration of outdoor signboards. To achieve this, AdvWT follows a two-step approach. First, a GAN-based, unsupervised image-to-image translation network is employed to model these naturally occurring damages, particularly in the context of outdoor signboards. The translation network encodes the characteristics of damaged signs into a latent `damage style code'. In the second step, we introduce adversarial perturbations into the style code, strategically optimizing its transformation process. This manipulation subtly alters the damage style representation, guiding the network to generate adversarial images where the appearance of damages remains perceptually realistic, while simultaneously ensuring their effectiveness in misleading neural networks. Through comprehensive experiments on two traffic sign datasets, we show that AdvWT effectively misleads DNNs in both digital and physical domains. AdvWT achieves an effective attack success rate, greater robustness, and a more natural appearance compared to existing physical-world adversarial examples. Additionally, integrating AdvWT into training enhances a model's generalizability to real-world damaged signs.
HiCM$^2$: Hierarchical Compact Memory Modeling for Dense Video Captioning
Dec 19, 2024



With the growing demand for solutions to real-world video challenges, interest in dense video captioning (DVC) has been on the rise. DVC involves the automatic captioning and localization of untrimmed videos. Several studies highlight the challenges of DVC and introduce improved methods utilizing prior knowledge, such as pre-training and external memory. In this research, we propose a model that leverages the prior knowledge of human-oriented hierarchical compact memory inspired by human memory hierarchy and cognition. To mimic human-like memory recall, we construct a hierarchical memory and a hierarchical memory reading module. We build an efficient hierarchical compact memory by employing clustering of memory events and summarization using large language models. Comparative experiments demonstrate that this hierarchical memory recall process improves the performance of DVC by achieving state-of-the-art performance on YouCook2 and ViTT datasets.
Resource-Efficient Medical Report Generation using Large Language Models
Oct 21, 2024



Medical report generation is the task of automatically writing radiology reports for chest X-ray images. Manually composing these reports is a time-consuming process that is also prone to human errors. Generating medical reports can therefore help reduce the burden on radiologists. In other words, we can promote greater clinical automation in the medical domain. In this work, we propose a new framework leveraging vision-enabled Large Language Models (LLM) for the task of medical report generation. We introduce a lightweight solution that achieves better or comparative performance as compared to previous solutions on the task of medical report generation. We conduct extensive experiments exploring different model sizes and enhancement approaches, such as prefix tuning to improve the text generation abilities of the LLMs. We evaluate our approach on a prominent large-scale radiology report dataset - MIMIC-CXR. Our results demonstrate the capability of our resource-efficient framework to generate patient-specific reports with strong medical contextual understanding and high precision.
LLaVA Needs More Knowledge: Retrieval Augmented Natural Language Generation with Knowledge Graph for Explaining Thoracic Pathologies
Oct 07, 2024



Generating Natural Language Explanations (NLEs) for model predictions on medical images, particularly those depicting thoracic pathologies, remains a critical and challenging task. Existing methodologies often struggle due to general models' insufficient domain-specific medical knowledge and privacy concerns associated with retrieval-based augmentation techniques. To address these issues, we propose a novel Vision-Language framework augmented with a Knowledge Graph (KG)-based datastore, which enhances the model's understanding by incorporating additional domain-specific medical knowledge essential for generating accurate and informative NLEs. Our framework employs a KG-based retrieval mechanism that not only improves the precision of the generated explanations but also preserves data privacy by avoiding direct data retrieval. The KG datastore is designed as a plug-and-play module, allowing for seamless integration with various model architectures. We introduce and evaluate three distinct frameworks within this paradigm: KG-LLaVA, which integrates the pre-trained LLaVA model with KG-RAG; Med-XPT, a custom framework combining MedCLIP, a transformer-based projector, and GPT-2; and Bio-LLaVA, which adapts LLaVA by incorporating the Bio-ViT-L vision model. These frameworks are validated on the MIMIC-NLE dataset, where they achieve state-of-the-art results, underscoring the effectiveness of KG augmentation in generating high-quality NLEs for thoracic pathologies.
Retrieval-Augmented Natural Language Reasoning for Explainable Visual Question Answering
Aug 30, 2024
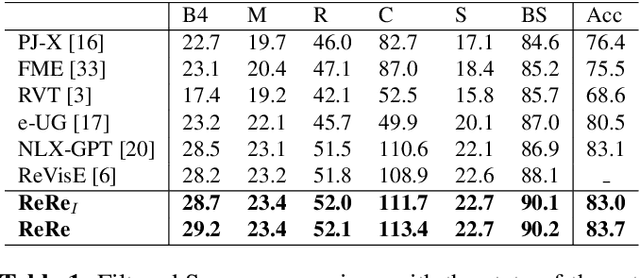


Visual Question Answering with Natural Language Explanation (VQA-NLE) task is challenging due to its high demand for reasoning-based inference. Recent VQA-NLE studies focus on enhancing model networks to amplify the model's reasoning capability but this approach is resource-consuming and unstable. In this work, we introduce a new VQA-NLE model, ReRe (Retrieval-augmented natural language Reasoning), using leverage retrieval information from the memory to aid in generating accurate answers and persuasive explanations without relying on complex networks and extra datasets. ReRe is an encoder-decoder architecture model using a pre-trained clip vision encoder and a pre-trained GPT-2 language model as a decoder. Cross-attention layers are added in the GPT-2 for processing retrieval features. ReRe outperforms previous methods in VQA accuracy and explanation score and shows improvement in NLE with more persuasive, reliability.
MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection
Jul 23, 2024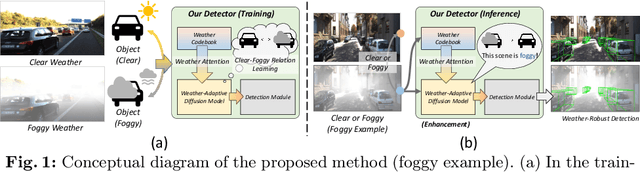
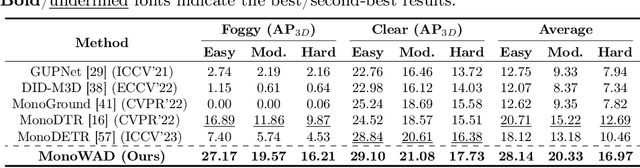
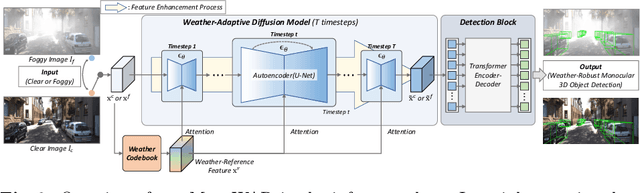
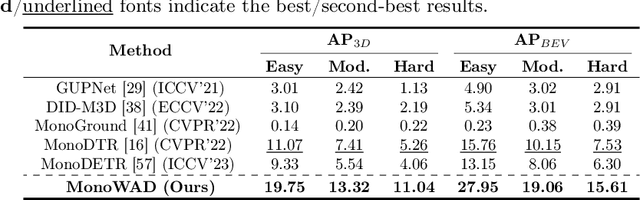
Monocular 3D object detection is an important challenging task in autonomous driving. Existing methods mainly focus on performing 3D detection in ideal weather conditions, characterized by scenarios with clear and optimal visibility. However, the challenge of autonomous driving requires the ability to handle changes in weather conditions, such as foggy weather, not just clear weather. We introduce MonoWAD, a novel weather-robust monocular 3D object detector with a weather-adaptive diffusion model. It contains two components: (1) the weather codebook to memorize the knowledge of the clear weather and generate a weather-reference feature for any input, and (2) the weather-adaptive diffusion model to enhance the feature representation of the input feature by incorporating a weather-reference feature. This serves an attention role in indicating how much improvement is needed for the input feature according to the weather conditions. To achieve this goal, we introduce a weather-adaptive enhancement loss to enhance the feature representation under both clear and foggy weather conditions. Extensive experiments under various weather conditions demonstrate that MonoWAD achieves weather-robust monocular 3D object detection. The code and dataset are released at https://github.com/VisualAIKHU/MonoWAD.