 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
HiCM$^2$: Hierarchical Compact Memory Modeling for Dense Video Captioning
Dec 19, 2024



With the growing demand for solutions to real-world video challenges, interest in dense video captioning (DVC) has been on the rise. DVC involves the automatic captioning and localization of untrimmed videos. Several studies highlight the challenges of DVC and introduce improved methods utilizing prior knowledge, such as pre-training and external memory. In this research, we propose a model that leverages the prior knowledge of human-oriented hierarchical compact memory inspired by human memory hierarchy and cognition. To mimic human-like memory recall, we construct a hierarchical memory and a hierarchical memory reading module. We build an efficient hierarchical compact memory by employing clustering of memory events and summarization using large language models. Comparative experiments demonstrate that this hierarchical memory recall process improves the performance of DVC by achieving state-of-the-art performance on YouCook2 and ViTT datasets.
Retrieval-Augmented Natural Language Reasoning for Explainable Visual Question Answering
Aug 30, 2024Visual Question Answering with Natural Language Explanation (VQA-NLE) task is challenging due to its high demand for reasoning-based inference. Recent VQA-NLE studies focus on enhancing model networks to amplify the model's reasoning capability but this approach is resource-consuming and unstable. In this work, we introduce a new VQA-NLE model, ReRe (Retrieval-augmented natural language Reasoning), using leverage retrieval information from the memory to aid in generating accurate answers and persuasive explanations without relying on complex networks and extra datasets. ReRe is an encoder-decoder architecture model using a pre-trained clip vision encoder and a pre-trained GPT-2 language model as a decoder. Cross-attention layers are added in the GPT-2 for processing retrieval features. ReRe outperforms previous methods in VQA accuracy and explanation score and shows improvement in NLE with more persuasive, reliability.
Mask-Free Neuron Concept Annotation for Interpreting Neural Networks in Medical Domain
Jul 16, 2024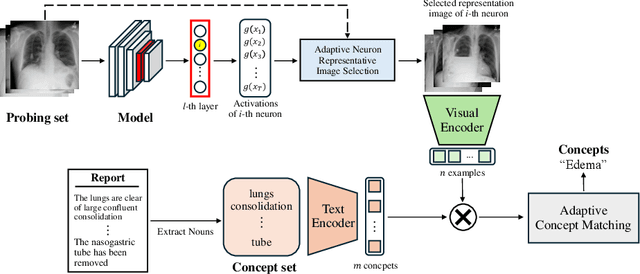


Recent advancements in deep neural networks have shown promise in aiding disease diagnosis and medical decision-making. However, ensuring transparent decision-making processes of AI models in compliance with regulations requires a comprehensive understanding of the model's internal workings. However, previous methods heavily rely on expensive pixel-wise annotated datasets for interpreting the model, presenting a significant drawback in medical domains. In this paper, we propose a novel medical neuron concept annotation method, named Mask-free Medical Model Interpretation (MAMMI), addresses these challenges. By using a vision-language model, our method relaxes the need for pixel-level masks for neuron concept annotation. MAMMI achieves superior performance compared to other interpretation methods, demonstrating its efficacy in providing rich representations for neurons in medical image analysis. Our experiments on a model trained on NIH chest X-rays validate the effectiveness of MAMMI, showcasing its potential for transparent clinical decision-making in the medical domain. The code is available at https://github.com/ailab-kyunghee/MAMMI.
Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval
Apr 11, 2024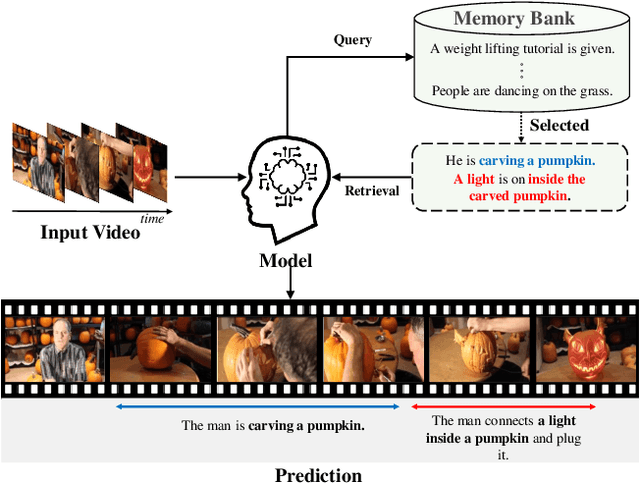

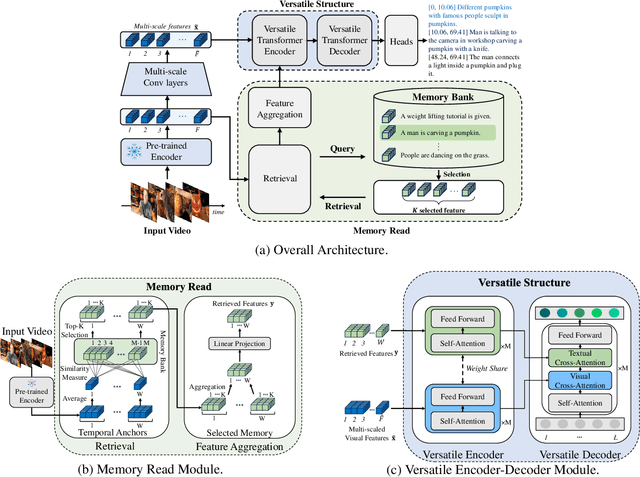

There has been significant attention to the research on dense video captioning, which aims to automatically localize and caption all events within untrimmed video. Several studies introduce methods by designing dense video captioning as a multitasking problem of event localization and event captioning to consider inter-task relations. However, addressing both tasks using only visual input is challenging due to the lack of semantic content. In this study, we address this by proposing a novel framework inspired by the cognitive information processing of humans. Our model utilizes external memory to incorporate prior knowledge. The memory retrieval method is proposed with cross-modal video-to-text matching. To effectively incorporate retrieved text features, the versatile encoder and the decoder with visual and textual cross-attention modules are designed. Comparative experiments have been conducted to show the effectiveness of the proposed method on ActivityNet Captions and YouCook2 datasets. Experimental results show promising performance of our model without extensive pretraining from a large video dataset.
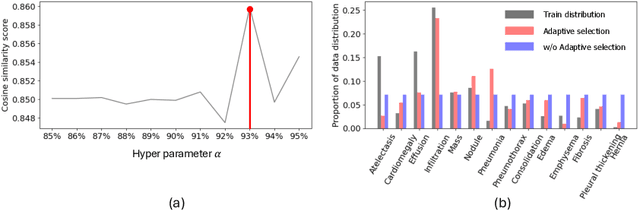
WWW: A Unified Framework for Explaining What, Where and Why of Neural Networks by Interpretation of Neuron Concepts
Feb 29, 2024
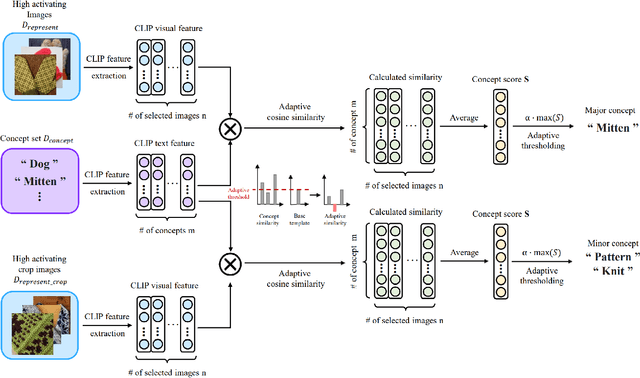
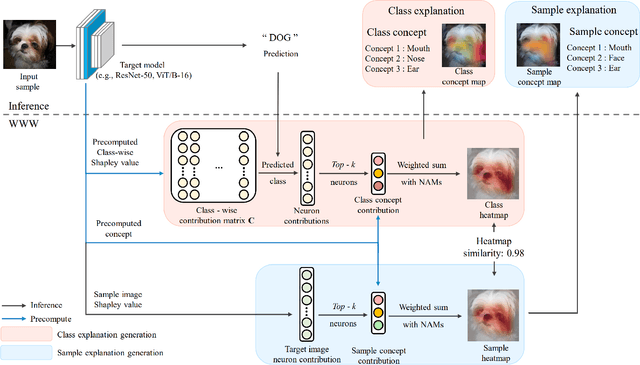
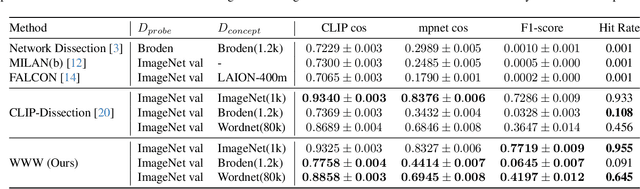
Recent advancements in neural networks have showcased their remarkable capabilities across various domains. Despite these successes, the "black box" problem still remains. Addressing this, we propose a novel framework, WWW, that offers the 'what', 'where', and 'why' of the neural network decisions in human-understandable terms. Specifically, WWW utilizes adaptive selection for concept discovery, employing adaptive cosine similarity and thresholding techniques to effectively explain 'what'. To address the 'where' and 'why', we proposed a novel combination of neuron activation maps (NAMs) with Shapley values, generating localized concept maps and heatmaps for individual inputs. Furthermore, WWW introduces a method for predicting uncertainty, leveraging heatmap similarities to estimate 'how' reliable the prediction is. Experimental evaluations of WWW demonstrate superior performance in both quantitative and qualitative metrics, outperforming existing methods in interpretability. WWW provides a unified solution for explaining 'what', 'where', and 'why', introducing a method for localized explanations from global interpretations and offering a plug-and-play solution adaptable to various architectures.