 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCM$^2$: Hierarchical Compact Memory Modeling for Dense Video Captioning
Dec 19, 2024



With the growing demand for solutions to real-world video challenges, interest in dense video captioning (DVC) has been on the rise. DVC involves the automatic captioning and localization of untrimmed videos. Several studies highlight the challenges of DVC and introduce improved methods utilizing prior knowledge, such as pre-training and external memory. In this research, we propose a model that leverages the prior knowledge of human-oriented hierarchical compact memory inspired by human memory hierarchy and cognition. To mimic human-like memory recall, we construct a hierarchical memory and a hierarchical memory reading module. We build an efficient hierarchical compact memory by employing clustering of memory events and summarization using large language models. Comparative experiments demonstrate that this hierarchical memory recall process improves the performance of DVC by achieving state-of-the-art performance on YouCook2 and ViTT datasets.
Retrieval-Augmented Natural Language Reasoning for Explainable Visual Question Answering
Aug 30, 2024Visual Question Answering with Natural Language Explanation (VQA-NLE) task is challenging due to its high demand for reasoning-based inference. Recent VQA-NLE studies focus on enhancing model networks to amplify the model's reasoning capability but this approach is resource-consuming and unstable. In this work, we introduce a new VQA-NLE model, ReRe (Retrieval-augmented natural language Reasoning), using leverage retrieval information from the memory to aid in generating accurate answers and persuasive explanations without relying on complex networks and extra datasets. ReRe is an encoder-decoder architecture model using a pre-trained clip vision encoder and a pre-trained GPT-2 language model as a decoder. Cross-attention layers are added in the GPT-2 for processing retrieval features. ReRe outperforms previous methods in VQA accuracy and explanation score and shows improvement in NLE with more persuasive, reliability.
Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval
Apr 11, 2024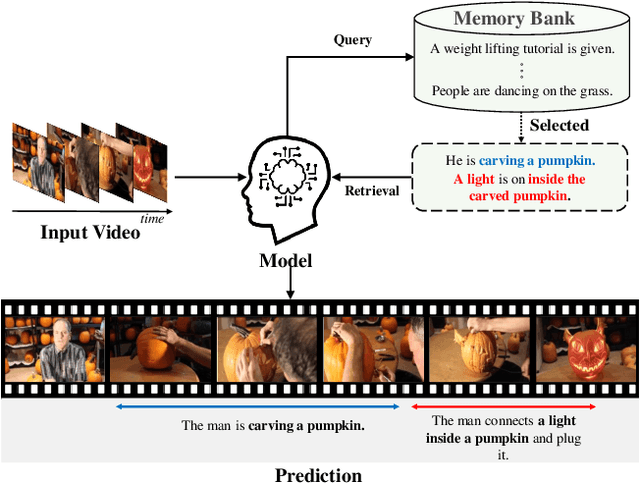

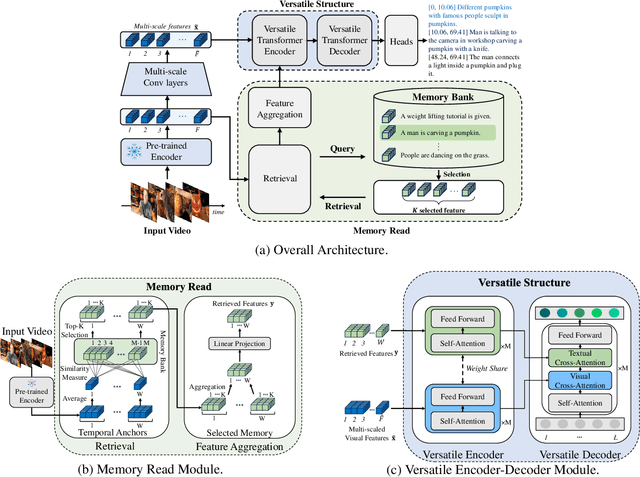

There has been significant attention to the research on dense video captioning, which aims to automatically localize and caption all events within untrimmed video. Several studies introduce methods by designing dense video captioning as a multitasking problem of event localization and event captioning to consider inter-task relations. However, addressing both tasks using only visual input is challenging due to the lack of semantic content. In this study, we address this by proposing a novel framework inspired by the cognitive information processing of humans. Our model utilizes external memory to incorporate prior knowledge. The memory retrieval method is proposed with cross-modal video-to-text matching. To effectively incorporate retrieved text features, the versatile encoder and the decoder with visual and textual cross-attention modules are designed. Comparative experiments have been conducted to show the effectiveness of the proposed method on ActivityNet Captions and YouCook2 datasets. Experimental results show promising performance of our model without extensive pretraining from a large video dataset.