 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSink-Token-Aware Pruning for Fine-Grained Video Understanding in Efficient Video LLMs
Apr 22, 2026Video Large Language Models (Video LLMs) incur high inference latency due to a large number of visual tokens provided to LLMs. To address this, training-free visual token pruning has emerged as a solution to reduce computational costs; however, existing methods are primarily validated on Multiple-Choice Question Answering (MCQA) benchmarks, where coarse-grained cues often suffice. In this work, we reveal that these methods suffer a sharp performance collapse on fine-grained understanding tasks requiring precise visual grounding, such as hallucination evaluation. To explore this gap, we conduct a systematic analysis and identify sink tokens--semantically uninformative tokens that attract excessive attention--as a key obstacle to fine-grained video understanding. When these sink tokens survive pruning, they distort the model's visual evidence and hinder fine-grained understanding. Motivated by these insights, we propose Sink-Token-aware Pruning (SToP), a simple yet effective plug-and-play method that introduces a sink score to quantify each token's tendency to behave as a sink and applies this score to existing spatial and temporal pruning methods to suppress them, thereby enhancing video understanding. To validate the effectiveness of SToP, we apply it to state-of-the-art pruning methods (VisionZip, FastVid, and Holitom) and evaluate it across diverse benchmarks covering hallucination, open-ended generation, compositional reasoning, and MCQA. Our results demonstrate that SToP significantly boosts performance, even when pruning up to 90% of visual tokens.
GCAgent: Long-Video Understanding via Schematic and Narrative Episodic Memory
Nov 15, 2025Long-video understanding remains a significant challenge for Multimodal Large Language Models (MLLMs) due to inherent token limitations and the complexity of capturing long-term temporal dependencies. Existing methods often fail to capture the global context and complex event relationships necessary for deep video reasoning. To address this, we introduce GCAgent, a novel Global-Context-Aware Agent framework that achieves comprehensive long-video understanding. Our core innovation is the Schematic and Narrative Episodic Memory. This memory structurally models events and their causal and temporal relations into a concise, organized context, fundamentally resolving the long-term dependency problem. Operating in a multi-stage Perception-Action-Reflection cycle, our GCAgent utilizes a Memory Manager to retrieve relevant episodic context for robust, context-aware inference. Extensive experiments confirm that GCAgent significantly enhances long-video understanding, achieving up to 23.5\% accuracy improvement on the Video-MME Long split over a strong MLLM baseline. Furthermore, our framework establishes state-of-the-art performance among comparable 7B-scale MLLMs, achieving 73.4\% accuracy on the Long split and the highest overall average (71.9\%) on the Video-MME benchmark, validating our agent-based reasoning paradigm and structured memory for cognitively-inspired long-video understanding.
Weakly Supervised Video Scene Graph Generation via Natural Language Supervision
Feb 21, 2025Existing Video Scene Graph Generation (VidSGG) studies are trained in a fully supervised manner, which requires all frames in a video to be annotated, thereby incurring high annotation cost compared to Image Scene Graph Generation (ImgSGG). Although the annotation cost of VidSGG can be alleviated by adopting a weakly supervised approach commonly used for ImgSGG (WS-ImgSGG) that uses image captions, there are two key reasons that hinder such a naive adoption: 1) Temporality within video captions, i.e., unlike image captions, video captions include temporal markers (e.g., before, while, then, after) that indicate time related details, and 2) Variability in action duration, i.e., unlike human actions in image captions, human actions in video captions unfold over varying duration. To address these issues, we propose a Natural Language-based Video Scene Graph Generation (NL-VSGG) framework that only utilizes the readily available video captions for training a VidSGG model. NL-VSGG consists of two key modules: Temporality-aware Caption Segmentation (TCS) module and Action Duration Variability-aware caption-frame alignment (ADV) module. Specifically, TCS segments the video captions into multiple sentences in a temporal order based on a Large Language Model (LLM), and ADV aligns each segmented sentence with appropriate frames considering the variability in action duration. Our approach leads to a significant enhancement in performance compared to simply applying the WS-ImgSGG pipeline to VidSGG on the Action Genome dataset. As a further benefit of utilizing the video captions as weak supervision, we show that the VidSGG model trained by NL-VSGG is able to predict a broader range of action classes that are not included in the training data, which makes our framework practical in reality.
HiCM$^2$: Hierarchical Compact Memory Modeling for Dense Video Captioning
Dec 19, 2024



With the growing demand for solutions to real-world video challenges, interest in dense video captioning (DVC) has been on the rise. DVC involves the automatic captioning and localization of untrimmed videos. Several studies highlight the challenges of DVC and introduce improved methods utilizing prior knowledge, such as pre-training and external memory. In this research, we propose a model that leverages the prior knowledge of human-oriented hierarchical compact memory inspired by human memory hierarchy and cognition. To mimic human-like memory recall, we construct a hierarchical memory and a hierarchical memory reading module. We build an efficient hierarchical compact memory by employing clustering of memory events and summarization using large language models. Comparative experiments demonstrate that this hierarchical memory recall process improves the performance of DVC by achieving state-of-the-art performance on YouCook2 and ViTT datasets.
Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval
Apr 11, 2024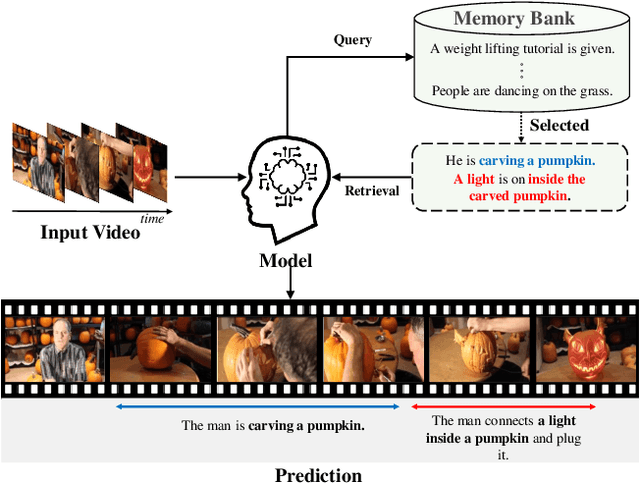

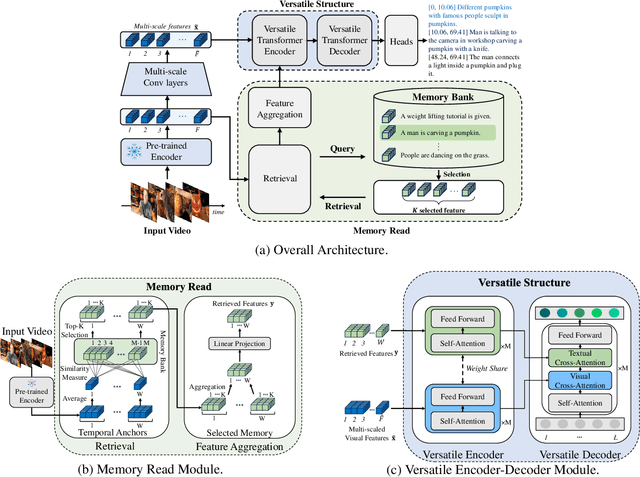

There has been significant attention to the research on dense video captioning, which aims to automatically localize and caption all events within untrimmed video. Several studies introduce methods by designing dense video captioning as a multitasking problem of event localization and event captioning to consider inter-task relations. However, addressing both tasks using only visual input is challenging due to the lack of semantic content. In this study, we address this by proposing a novel framework inspired by the cognitive information processing of humans. Our model utilizes external memory to incorporate prior knowledge. The memory retrieval method is proposed with cross-modal video-to-text matching. To effectively incorporate retrieved text features, the versatile encoder and the decoder with visual and textual cross-attention modules are designed. Comparative experiments have been conducted to show the effectiveness of the proposed method on ActivityNet Captions and YouCook2 datasets. Experimental results show promising performance of our model without extensive pretraining from a large video dataset.
Adaptive Self-training Framework for Fine-grained Scene Graph Generation
Jan 18, 2024



Scene graph generation (SGG) models have suffered from inherent problems regarding the benchmark datasets such as the long-tailed predicate distribution and missing annotation problems. In this work, we aim to alleviate the long-tailed problem of SGG by utilizing unannotated triplets. To this end, we introduce a Self-Training framework for SGG (ST-SGG) that assigns pseudo-labels for unannotated triplets based on which the SGG models are trained. While there has been significant progress in self-training for image recognition, designing a self-training framework for the SGG task is more challenging due to its inherent nature such as the semantic ambiguity and the long-tailed distribution of predicate classes. Hence, we propose a novel pseudo-labeling technique for SGG, called Class-specific Adaptive Thresholding with Momentum (CATM), which is a model-agnostic framework that can be applied to any existing SGG models. Furthermore, we devise a graph structure learner (GSL) that is beneficial when adopting our proposed self-training framework to the state-of-the-art message-passing neural network (MPNN)-based SGG models. Our extensive experiments verify the effectiveness of ST-SGG on various SGG models, particularly in enhancing the performance on fine-grained predicate classes.
LLM4SGG: Large Language Model for Weakly Supervised Scene Graph Generation
Oct 20, 2023Weakly-Supervised Scene Graph Generation (WSSGG) research has recently emerged as an alternative to the fully-supervised approach that heavily relies on costly annotations. In this regard, studies on WSSGG have utilized image captions to obtain unlocalized triplets while primarily focusing on grounding the unlocalized triplets over image regions. However, they have overlooked the two issues involved in the triplet formation process from the captions: 1) Semantic over-simplification issue arises when extracting triplets from captions, where fine-grained predicates in captions are undesirably converted into coarse-grained predicates, resulting in a long-tailed predicate distribution, and 2) Low-density scene graph issue arises when aligning the triplets in the caption with entity/predicate classes of interest, where many triplets are discarded and not used in training, leading to insufficient supervision. To tackle the two issues, we propose a new approach, i.e., Large Language Model for weakly-supervised SGG (LLM4SGG), where we mitigate the two issues by leveraging the LLM's in-depth understanding of language and reasoning ability during the extraction of triplets from captions and alignment of entity/predicate classes with target data. To further engage the LLM in these processes, we adopt the idea of Chain-of-Thought and the in-context few-shot learning strategy. To validate the effectiveness of LLM4SGG, we conduct extensive experiments on Visual Genome and GQA datasets, showing significant improvements in both Recall@K and mean Recall@K compared to the state-of-the-art WSSGG methods. A further appeal is that LLM4SGG is data-efficient, enabling effective model training with a small amount of training images.
Unbiased Heterogeneous Scene Graph Generation with Relation-aware Message Passing Neural Network
Dec 01, 2022



Recent scene graph generation (SGG) frameworks have focused on learning complex relationships among multiple objects in an image. Thanks to the nature of the message passing neural network (MPNN) that models high-order interactions between objects and their neighboring objects, they are dominant representation learning modules for SGG. However, existing MPNN-based frameworks assume the scene graph as a homogeneous graph, which restricts the context-awareness of visual relations between objects. That is, they overlook the fact that the relations tend to be highly dependent on the objects with which the relations are associated. In this paper, we propose an unbiased heterogeneous scene graph generation (HetSGG) framework that captures relation-aware context using message passing neural networks. We devise a novel message passing layer, called relation-aware message passing neural network (RMP), that aggregates the contextual information of an image considering the predicate type between objects. Our extensive evaluations demonstrate that HetSGG outperforms state-of-the-art methods, especially outperforming on tail predicate classes.
Information Elevation Network for Fast Online Action Detection
Sep 28, 2021



Online action detection (OAD) is a task that receives video segments within a streaming video as inputs and identifies ongoing actions within them. It is important to retain past information associated with a current action. However, long short-term memory (LSTM), a popular recurrent unit for modeling temporal information from videos, accumulates past information from the previous hidden and cell states and the extracted visual features at each timestep without considering the relationships between the past and current information. Consequently, the forget gate of the original LSTM can lose the accumulated information relevant to the current action because it determines which information to forget without considering the current action. We introduce a novel information elevation unit (IEU) that lifts up and accumulate the past information relevant to the current action in order to model the past information that is especially relevant to the current action. To the best of our knowledge, our IEN is the first attempt that considers the computational overhead for the practical use of OAD. Through ablation studies, we design an efficient and effective OAD network using IEUs, called an information elevation network (IEN). Our IEN uses visual features extracted by a fast action recognition network taking only RGB frames because extracting optical flows requires heavy computation overhead. On two OAD benchmark datasets, THUMOS-14 and TVSeries, our IEN outperforms state-of-the-art OAD methods using only RGB frames. Furthermore, on the THUMOS-14 dataset, our IEN outperforms the state-of-the-art OAD methods using two-stream features based on RGB frames and optical flows.
Learning to Discriminate Information for Online Action Detection: Analysis and Application
Sep 09, 2021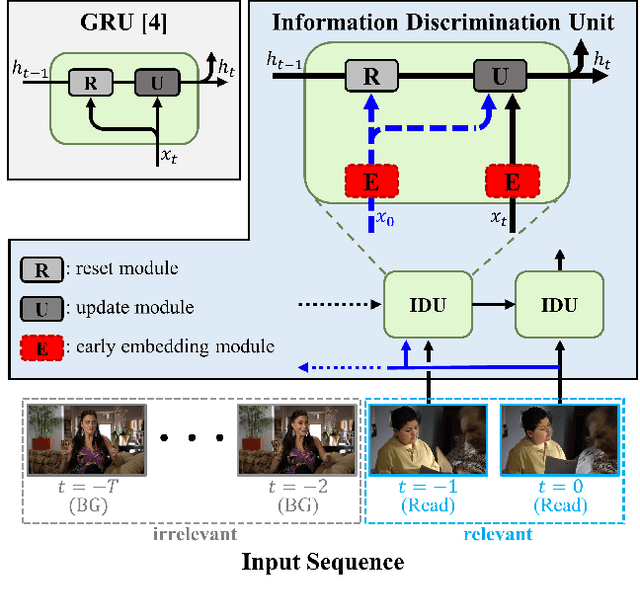
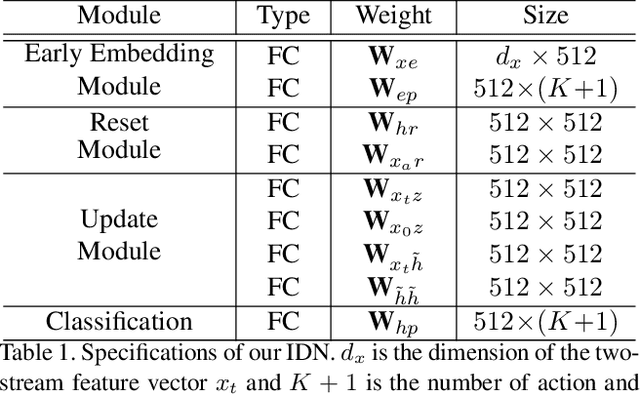
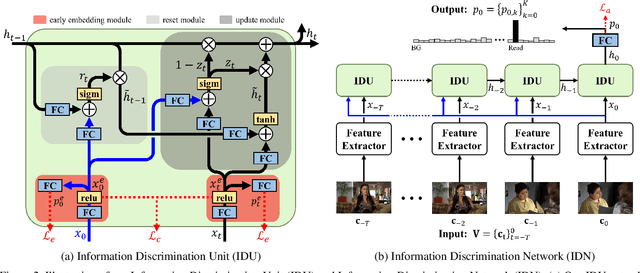
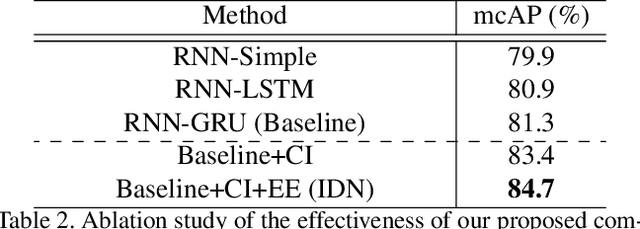
Online action detection, which aims to identify an ongoing action from a streaming video, is an important subject in real-world applications. For this task, previous methods use recurrent neural networks for modeling temporal relations in an input sequence. However, these methods overlook the fact that the input image sequence includes not only the action of interest but background and irrelevant actions. This would induce recurrent units to accumulate unnecessary information for encoding features on the action of interest. To overcome this problem, we propose a novel recurrent unit, named Information Discrimination Unit (IDU), which explicitly discriminates the information relevancy between an ongoing action and others to decide whether to accumulate the input information. This enables learning more discriminative representations for identifying an ongoing action. In this paper, we further present a new recurrent unit, called Information Integration Unit (IIU), for action anticipation. Our IIU exploits the outputs from IDU as pseudo action labels as well as RGB frames to learn enriched features of observed actions effectively. In experiments on TVSeries and THUMOS-14, the proposed methods outperform state-of-the-art methods by a significant margin in online action detection and action anticipation. Moreover, we demonstrate the effectiveness of the proposed units by conducting comprehensive ablation studies.