 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Video Scene Graph Generation via Natural Language Supervision
Feb 21, 2025Existing Video Scene Graph Generation (VidSGG) studies are trained in a fully supervised manner, which requires all frames in a video to be annotated, thereby incurring high annotation cost compared to Image Scene Graph Generation (ImgSGG). Although the annotation cost of VidSGG can be alleviated by adopting a weakly supervised approach commonly used for ImgSGG (WS-ImgSGG) that uses image captions, there are two key reasons that hinder such a naive adoption: 1) Temporality within video captions, i.e., unlike image captions, video captions include temporal markers (e.g., before, while, then, after) that indicate time related details, and 2) Variability in action duration, i.e., unlike human actions in image captions, human actions in video captions unfold over varying duration. To address these issues, we propose a Natural Language-based Video Scene Graph Generation (NL-VSGG) framework that only utilizes the readily available video captions for training a VidSGG model. NL-VSGG consists of two key modules: Temporality-aware Caption Segmentation (TCS) module and Action Duration Variability-aware caption-frame alignment (ADV) module. Specifically, TCS segments the video captions into multiple sentences in a temporal order based on a Large Language Model (LLM), and ADV aligns each segmented sentence with appropriate frames considering the variability in action duration. Our approach leads to a significant enhancement in performance compared to simply applying the WS-ImgSGG pipeline to VidSGG on the Action Genome dataset. As a further benefit of utilizing the video captions as weak supervision, we show that the VidSGG model trained by NL-VSGG is able to predict a broader range of action classes that are not included in the training data, which makes our framework practical in reality.
Semantic Diversity-aware Prototype-based Learning for Unbiased Scene Graph Generation
Jul 25, 2024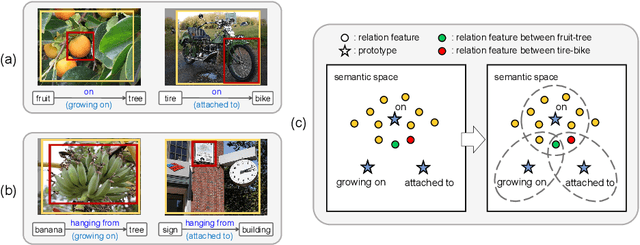
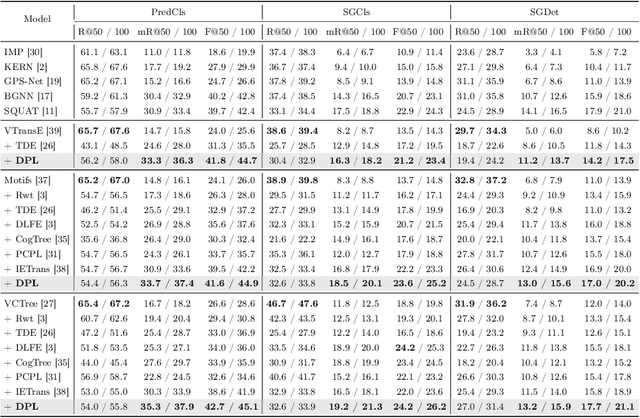
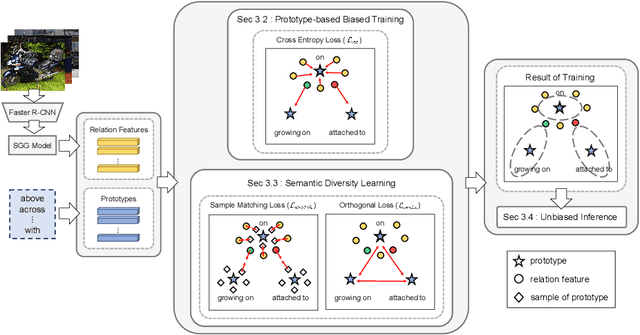
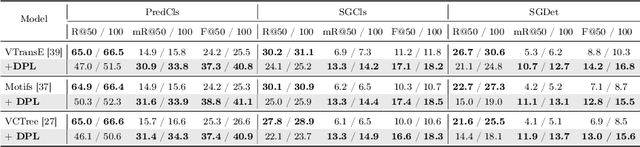
The scene graph generation (SGG) task involves detecting objects within an image and predicting predicates that represent the relationships between the objects. However, in SGG benchmark datasets, each subject-object pair is annotated with a single predicate even though a single predicate may exhibit diverse semantics (i.e., semantic diversity), existing SGG models are trained to predict the one and only predicate for each pair. This in turn results in the SGG models to overlook the semantic diversity that may exist in a predicate, thus leading to biased predictions. In this paper, we propose a novel model-agnostic Semantic Diversity-aware Prototype-based Learning (DPL) framework that enables unbiased predictions based on the understanding of the semantic diversity of predicates. Specifically, DPL learns the regions in the semantic space covered by each predicate to distinguish among the various different semantics that a single predicate can represent. Extensive experiments demonstrate that our proposed model-agnostic DPL framework brings significant performance improvement on existing SGG models, and also effectively understands the semantic diversity of predicates.
LLM4SGG: Large Language Model for Weakly Supervised Scene Graph Generation
Oct 20, 2023Weakly-Supervised Scene Graph Generation (WSSGG) research has recently emerged as an alternative to the fully-supervised approach that heavily relies on costly annotations. In this regard, studies on WSSGG have utilized image captions to obtain unlocalized triplets while primarily focusing on grounding the unlocalized triplets over image regions. However, they have overlooked the two issues involved in the triplet formation process from the captions: 1) Semantic over-simplification issue arises when extracting triplets from captions, where fine-grained predicates in captions are undesirably converted into coarse-grained predicates, resulting in a long-tailed predicate distribution, and 2) Low-density scene graph issue arises when aligning the triplets in the caption with entity/predicate classes of interest, where many triplets are discarded and not used in training, leading to insufficient supervision. To tackle the two issues, we propose a new approach, i.e., Large Language Model for weakly-supervised SGG (LLM4SGG), where we mitigate the two issues by leveraging the LLM's in-depth understanding of language and reasoning ability during the extraction of triplets from captions and alignment of entity/predicate classes with target data. To further engage the LLM in these processes, we adopt the idea of Chain-of-Thought and the in-context few-shot learning strategy. To validate the effectiveness of LLM4SGG, we conduct extensive experiments on Visual Genome and GQA datasets, showing significant improvements in both Recall@K and mean Recall@K compared to the state-of-the-art WSSGG methods. A further appeal is that LLM4SGG is data-efficient, enabling effective model training with a small amount of training images.