 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSink-Token-Aware Pruning for Fine-Grained Video Understanding in Efficient Video LLMs
Apr 22, 2026Video Large Language Models (Video LLMs) incur high inference latency due to a large number of visual tokens provided to LLMs. To address this, training-free visual token pruning has emerged as a solution to reduce computational costs; however, existing methods are primarily validated on Multiple-Choice Question Answering (MCQA) benchmarks, where coarse-grained cues often suffice. In this work, we reveal that these methods suffer a sharp performance collapse on fine-grained understanding tasks requiring precise visual grounding, such as hallucination evaluation. To explore this gap, we conduct a systematic analysis and identify sink tokens--semantically uninformative tokens that attract excessive attention--as a key obstacle to fine-grained video understanding. When these sink tokens survive pruning, they distort the model's visual evidence and hinder fine-grained understanding. Motivated by these insights, we propose Sink-Token-aware Pruning (SToP), a simple yet effective plug-and-play method that introduces a sink score to quantify each token's tendency to behave as a sink and applies this score to existing spatial and temporal pruning methods to suppress them, thereby enhancing video understanding. To validate the effectiveness of SToP, we apply it to state-of-the-art pruning methods (VisionZip, FastVid, and Holitom) and evaluate it across diverse benchmarks covering hallucination, open-ended generation, compositional reasoning, and MCQA. Our results demonstrate that SToP significantly boosts performance, even when pruning up to 90% of visual tokens.
Why and When Visual Token Pruning Fails? A Study on Relevant Visual Information Shift in MLLMs Decoding
Apr 14, 2026Recently, visual token pruning has been studied to handle the vast number of visual tokens in Multimodal Large Language Models. However, we observe that while existing pruning methods perform reliably on simple visual understanding, they struggle to effectively generalize to complex visual reasoning tasks, a critical gap underexplored in previous studies. Through a systematic analysis, we identify Relevant Visual Information Shift (RVIS) during decoding as the primary failure driver. To address this, we propose Decoding-stage Shift-aware Token Pruning (DSTP), a training-free add-on framework that enables existing pruning methods to align visual tokens with shifting reasoning requirements during the decoding stage. Extensive experiments demonstrate that DSTP significantly mitigates performance degradation of pruning methods in complex reasoning tasks, while consistently yielding performance gains even across visual understanding benchmarks. Furthermore, DSTP demonstrates effectiveness across diverse state-of-the-art architectures, highlighting its generalizability and efficiency with minimal computational overhead.
Disentangling and Generating Modalities for Recommendation in Missing Modality Scenarios
Apr 23, 2025Multi-modal recommender systems (MRSs) have achieved notable success in improving personalization by leveraging diverse modalities such as images, text, and audio. However, two key challenges remain insufficiently addressed: (1) Insufficient consideration of missing modality scenarios and (2) the overlooking of unique characteristics of modality features. These challenges result in significant performance degradation in realistic situations where modalities are missing. To address these issues, we propose Disentangling and Generating Modality Recommender (DGMRec), a novel framework tailored for missing modality scenarios. DGMRec disentangles modality features into general and specific modality features from an information-based perspective, enabling richer representations for recommendation. Building on this, it generates missing modality features by integrating aligned features from other modalities and leveraging user modality preferences. Extensive experiments show that DGMRec consistently outperforms state-of-the-art MRSs in challenging scenarios, including missing modalities and new item settings as well as diverse missing ratios and varying levels of missing modalities. Moreover, DGMRec's generation-based approach enables cross-modal retrieval, a task inapplicable for existing MRSs, highlighting its adaptability and potential for real-world applications. Our code is available at https://github.com/ptkjw1997/DGMRec.
Image is All You Need: Towards Efficient and Effective Large Language Model-Based Recommender Systems
Mar 08, 2025Large Language Models (LLMs) have recently emerged as a powerful backbone for recommender systems. Existing LLM-based recommender systems take two different approaches for representing items in natural language, i.e., Attribute-based Representation and Description-based Representation. In this work, we aim to address the trade-off between efficiency and effectiveness that these two approaches encounter, when representing items consumed by users. Based on our interesting observation that there is a significant information overlap between images and descriptions associated with items, we propose a novel method, Image is all you need for LLM-based Recommender system (I-LLMRec). Our main idea is to leverage images as an alternative to lengthy textual descriptions for representing items, aiming at reducing token usage while preserving the rich semantic information of item descriptions. Through extensive experiments, we demonstrate that I-LLMRec outperforms existing methods in both efficiency and effectiveness by leveraging images. Moreover, a further appeal of I-LLMRec is its ability to reduce sensitivity to noise in descriptions, leading to more robust recommendations.
Training Robust Graph Neural Networks by Modeling Noise Dependencies
Feb 27, 2025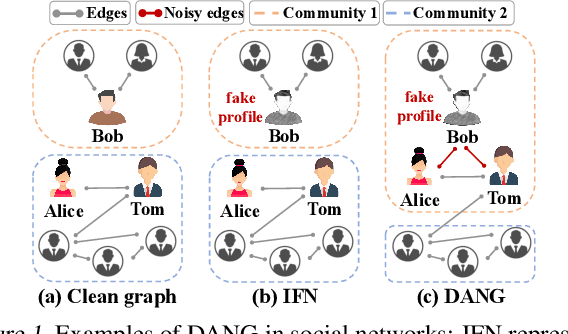
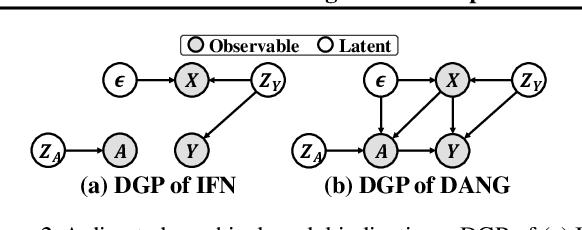
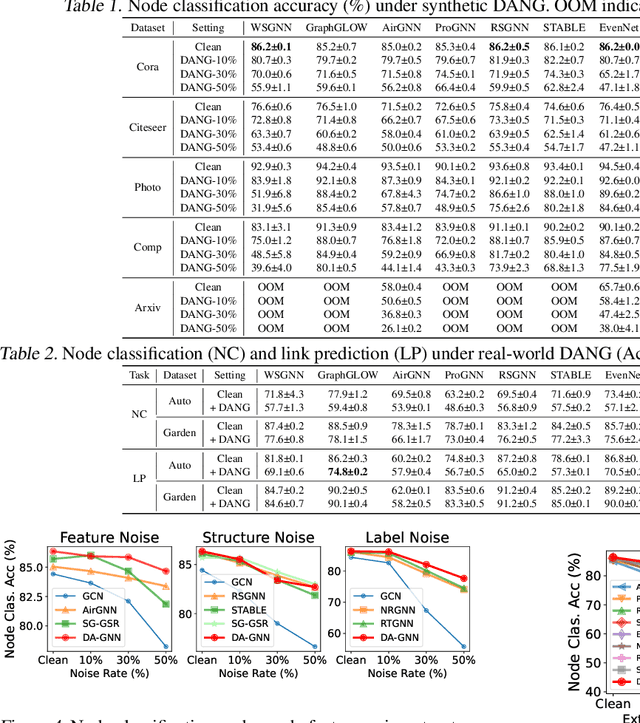
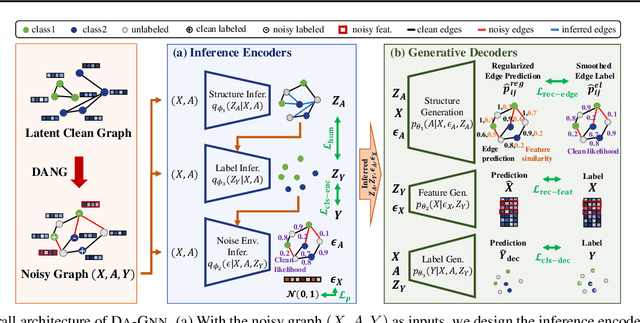
In real-world applications, node features in graphs often contain noise from various sources, leading to significant performance degradation in GNNs. Although several methods have been developed to enhance robustness, they rely on the unrealistic assumption that noise in node features is independent of the graph structure and node labels, thereby limiting their applicability. To this end, we introduce a more realistic noise scenario, dependency-aware noise on graphs (DANG), where noise in node features create a chain of noise dependencies that propagates to the graph structure and node labels. We propose a novel robust GNN, DA-GNN, which captures the causal relationships among variables in the data generating process (DGP) of DANG using variational inference. In addition, we present new benchmark datasets that simulate DANG in real-world applications, enabling more practical research on robust GNNs. Extensive experiments demonstrate that DA-GNN consistently outperforms existing baselines across various noise scenarios, including both DANG and conventional noise models commonly considered in this field.
Weakly Supervised Video Scene Graph Generation via Natural Language Supervision
Feb 21, 2025Existing Video Scene Graph Generation (VidSGG) studies are trained in a fully supervised manner, which requires all frames in a video to be annotated, thereby incurring high annotation cost compared to Image Scene Graph Generation (ImgSGG). Although the annotation cost of VidSGG can be alleviated by adopting a weakly supervised approach commonly used for ImgSGG (WS-ImgSGG) that uses image captions, there are two key reasons that hinder such a naive adoption: 1) Temporality within video captions, i.e., unlike image captions, video captions include temporal markers (e.g., before, while, then, after) that indicate time related details, and 2) Variability in action duration, i.e., unlike human actions in image captions, human actions in video captions unfold over varying duration. To address these issues, we propose a Natural Language-based Video Scene Graph Generation (NL-VSGG) framework that only utilizes the readily available video captions for training a VidSGG model. NL-VSGG consists of two key modules: Temporality-aware Caption Segmentation (TCS) module and Action Duration Variability-aware caption-frame alignment (ADV) module. Specifically, TCS segments the video captions into multiple sentences in a temporal order based on a Large Language Model (LLM), and ADV aligns each segmented sentence with appropriate frames considering the variability in action duration. Our approach leads to a significant enhancement in performance compared to simply applying the WS-ImgSGG pipeline to VidSGG on the Action Genome dataset. As a further benefit of utilizing the video captions as weak supervision, we show that the VidSGG model trained by NL-VSGG is able to predict a broader range of action classes that are not included in the training data, which makes our framework practical in reality.
Is Safety Standard Same for Everyone? User-Specific Safety Evaluation of Large Language Models
Feb 20, 2025As the use of large language model (LLM) agents continues to grow, their safety vulnerabilities have become increasingly evident. Extensive benchmarks evaluate various aspects of LLM safety by defining the safety relying heavily on general standards, overlooking user-specific standards. However, safety standards for LLM may vary based on a user-specific profiles rather than being universally consistent across all users. This raises a critical research question: Do LLM agents act safely when considering user-specific safety standards? Despite its importance for safe LLM use, no benchmark datasets currently exist to evaluate the user-specific safety of LLMs. To address this gap, we introduce U-SAFEBENCH, the first benchmark designed to assess user-specific aspect of LLM safety. Our evaluation of 18 widely used LLMs reveals current LLMs fail to act safely when considering user-specific safety standards, marking a new discovery in this field. To address this vulnerability, we propose a simple remedy based on chain-of-thought, demonstrating its effectiveness in improving user-specific safety. Our benchmark and code are available at https://github.com/yeonjun-in/U-SafeBench.
Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Feb 19, 2025Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users' item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs' ability to understand users' item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
RA-SGG: Retrieval-Augmented Scene Graph Generation Framework via Multi-Prototype Learning
Dec 17, 2024Scene Graph Generation (SGG) research has suffered from two fundamental challenges: the long-tailed predicate distribution and semantic ambiguity between predicates. These challenges lead to a bias towards head predicates in SGG models, favoring dominant general predicates while overlooking fine-grained predicates. In this paper, we address the challenges of SGG by framing it as multi-label classification problem with partial annotation, where relevant labels of fine-grained predicates are missing. Under the new frame, we propose Retrieval-Augmented Scene Graph Generation (RA-SGG), which identifies potential instances to be multi-labeled and enriches the single-label with multi-labels that are semantically similar to the original label by retrieving relevant samples from our established memory bank. Based on augmented relations (i.e., discovered multi-labels), we apply multi-prototype learning to train our SGG model. Several comprehensive experiments have demonstrated that RA-SGG outperforms state-of-the-art baselines by up to 3.6% on VG and 5.9% on GQA, particularly in terms of F@K, showing that RA-SGG effectively alleviates the issue of biased prediction caused by the long-tailed distribution and semantic ambiguity of predicates.
* 7 pages
Debiased Graph Poisoning Attack via Contrastive Surrogate Objective
Jul 27, 2024



Graph neural networks (GNN) are vulnerable to adversarial attacks, which aim to degrade the performance of GNNs through imperceptible changes on the graph. However, we find that in fact the prevalent meta-gradient-based attacks, which utilizes the gradient of the loss w.r.t the adjacency matrix, are biased towards training nodes. That is, their meta-gradient is determined by a training procedure of the surrogate model, which is solely trained on the training nodes. This bias manifests as an uneven perturbation, connecting two nodes when at least one of them is a labeled node, i.e., training node, while it is unlikely to connect two unlabeled nodes. However, these biased attack approaches are sub-optimal as they do not consider flipping edges between two unlabeled nodes at all. This means that they miss the potential attacked edges between unlabeled nodes that significantly alter the representation of a node. In this paper, we investigate the meta-gradients to uncover the root cause of the uneven perturbations of existing attacks. Based on our analysis, we propose a Meta-gradient-based attack method using contrastive surrogate objective (Metacon), which alleviates the bias in meta-gradient using a new surrogate loss. We conduct extensive experiments to show that Metacon outperforms existing meta gradient-based attack methods through benchmark datasets, while showing that alleviating the bias towards training nodes is effective in attacking the graph structure.