 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Feb 19, 2025Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users' item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs' ability to understand users' item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
Unifying Structure and Language Semantic for Efficient Contrastive Knowledge Graph Completion with Structured Entity Anchors
Nov 07, 2023



The goal of knowledge graph completion (KGC) is to predict missing links in a KG using trained facts that are already known. In recent, pre-trained language model (PLM) based methods that utilize both textual and structural information are emerging, but their performances lag behind state-of-the-art (SOTA) structure-based methods or some methods lose their inductive inference capabilities in the process of fusing structure embedding to text encoder. In this paper, we propose a novel method to effectively unify structure information and language semantics without losing the power of inductive reasoning. We adopt entity anchors and these anchors and textual description of KG elements are fed together into the PLM-based encoder to learn unified representations. In addition, the proposed method utilizes additional random negative samples which can be reused in the each mini-batch during contrastive learning to learn a generalized entity representations. We verify the effectiveness of the our proposed method through various experiments and analysis. The experimental results on standard benchmark widely used in link prediction task show that the proposed model outperforms existing the SOTA KGC models. Especially, our method show the largest performance improvement on FB15K-237, which is competitive to the SOTA of structure-based KGC methods.
e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce
Jul 01, 2022
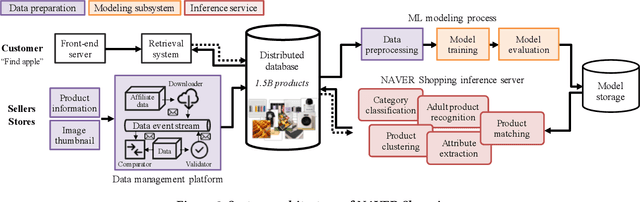
Understanding vision and language representations of product content is vital for search and recommendation applications in e-commerce. As a backbone for online shopping platforms and inspired by the recent success in representation learning research, we propose a contrastive learning framework that aligns language and visual models using unlabeled raw product text and images. We present techniques we used to train large-scale representation learning models and share solutions that address domain-specific challenges. We study the performance using our pre-trained model as backbones for diverse downstream tasks, including category classification, attribute extraction, product matching, product clustering, and adult product recognition. Experimental results show that our proposed method outperforms the baseline in each downstream task regarding both single modality and multiple modalities.