 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Structure and Language Semantic for Efficient Contrastive Knowledge Graph Completion with Structured Entity Anchors
Nov 07, 2023



The goal of knowledge graph completion (KGC) is to predict missing links in a KG using trained facts that are already known. In recent, pre-trained language model (PLM) based methods that utilize both textual and structural information are emerging, but their performances lag behind state-of-the-art (SOTA) structure-based methods or some methods lose their inductive inference capabilities in the process of fusing structure embedding to text encoder. In this paper, we propose a novel method to effectively unify structure information and language semantics without losing the power of inductive reasoning. We adopt entity anchors and these anchors and textual description of KG elements are fed together into the PLM-based encoder to learn unified representations. In addition, the proposed method utilizes additional random negative samples which can be reused in the each mini-batch during contrastive learning to learn a generalized entity representations. We verify the effectiveness of the our proposed method through various experiments and analysis. The experimental results on standard benchmark widely used in link prediction task show that the proposed model outperforms existing the SOTA KGC models. Especially, our method show the largest performance improvement on FB15K-237, which is competitive to the SOTA of structure-based KGC methods.
Entity Aware Negative Sampling with Auxiliary Loss of False Negative Prediction for Knowledge Graph Embedding
Oct 12, 2022

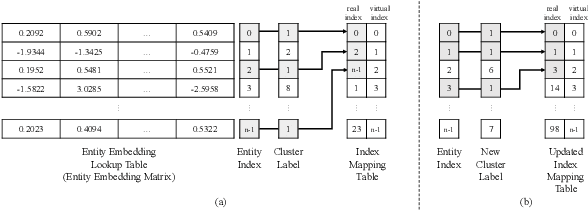

Knowledge graph (KG) embedding is widely used in many downstream applications using KGs. Generally, since KGs contain only ground truth triples, it is necessary to construct arbitrary negative samples for representation learning of KGs. Recently, various methods for sampling high-quality negatives have been studied because the quality of negative triples has great effect on KG embedding. In this paper, we propose a novel method called Entity Aware Negative Sampling (EANS), which is able to sample negative entities resemble to positive one by adopting Gaussian distribution to the aligned entity index space. Additionally, we introduce auxiliary loss for false negative prediction that can alleviate the impact of the sampled false negative triples. The proposed method can generate high-quality negative samples regardless of negative sample size and effectively mitigate the influence of false negative samples. The experimental results on standard benchmarks show that our EANS outperforms existing the state-of-the-art methods of negative sampling on several knowledge graph embedding models. Moreover, the proposed method achieves competitive performance even when the number of negative samples is limited to only one.