 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Feb 19, 2025Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users' item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs' ability to understand users' item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Apr 17, 2024

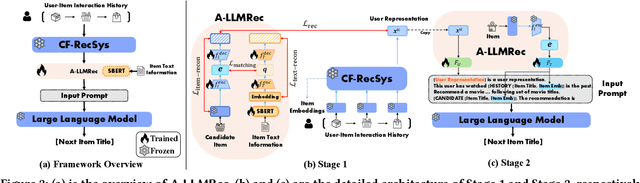

Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
Task Relation-aware Continual User Representation Learning
Jun 01, 2023User modeling, which learns to represent users into a low-dimensional representation space based on their past behaviors, got a surge of interest from the industry for providing personalized services to users. Previous efforts in user modeling mainly focus on learning a task-specific user representation that is designed for a single task. However, since learning task-specific user representations for every task is infeasible, recent studies introduce the concept of universal user representation, which is a more generalized representation of a user that is relevant to a variety of tasks. Despite their effectiveness, existing approaches for learning universal user representations are impractical in real-world applications due to the data requirement, catastrophic forgetting and the limited learning capability for continually added tasks. In this paper, we propose a novel continual user representation learning method, called TERACON, whose learning capability is not limited as the number of learned tasks increases while capturing the relationship between the tasks. The main idea is to introduce an embedding for each task, i.e., task embedding, which is utilized to generate task-specific soft masks that not only allow the entire model parameters to be updated until the end of training sequence, but also facilitate the relationship between the tasks to be captured. Moreover, we introduce a novel knowledge retention module with pseudo-labeling strategy that successfully alleviates the long-standing problem of continual learning, i.e., catastrophic forgetting. Extensive experiments on public and proprietary real-world datasets demonstrate the superiority and practicality of TERACON. Our code is available at https://github.com/Sein-Kim/TERACON.