 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-EvolveRec: Self-Evolving Recommender Systems with LLM-based Directional Feedback
Feb 13, 2026Traditional methods for automating recommender system design, such as Neural Architecture Search (NAS), are often constrained by a fixed search space defined by human priors, limiting innovation to pre-defined operators. While recent LLM-driven code evolution frameworks shift fixed search space target to open-ended program spaces, they primarily rely on scalar metrics (e.g., NDCG, Hit Ratio) that fail to provide qualitative insights into model failures or directional guidance for improvement. To address this, we propose Self-EvolveRec, a novel framework that establishes a directional feedback loop by integrating a User Simulator for qualitative critiques and a Model Diagnosis Tool for quantitative internal verification. Furthermore, we introduce a Diagnosis Tool - Model Co-Evolution strategy to ensure that evaluation criteria dynamically adapt as the recommendation architecture evolves. Extensive experiments demonstrate that Self-EvolveRec significantly outperforms state-of-the-art NAS and LLM-driven code evolution baselines in both recommendation performance and user satisfaction. Our code is available at https://github.com/Sein-Kim/self_evolverec.
Disentangling and Generating Modalities for Recommendation in Missing Modality Scenarios
Apr 23, 2025Multi-modal recommender systems (MRSs) have achieved notable success in improving personalization by leveraging diverse modalities such as images, text, and audio. However, two key challenges remain insufficiently addressed: (1) Insufficient consideration of missing modality scenarios and (2) the overlooking of unique characteristics of modality features. These challenges result in significant performance degradation in realistic situations where modalities are missing. To address these issues, we propose Disentangling and Generating Modality Recommender (DGMRec), a novel framework tailored for missing modality scenarios. DGMRec disentangles modality features into general and specific modality features from an information-based perspective, enabling richer representations for recommendation. Building on this, it generates missing modality features by integrating aligned features from other modalities and leveraging user modality preferences. Extensive experiments show that DGMRec consistently outperforms state-of-the-art MRSs in challenging scenarios, including missing modalities and new item settings as well as diverse missing ratios and varying levels of missing modalities. Moreover, DGMRec's generation-based approach enables cross-modal retrieval, a task inapplicable for existing MRSs, highlighting its adaptability and potential for real-world applications. Our code is available at https://github.com/ptkjw1997/DGMRec.
Dynamic Time-aware Continual User Representation Learning
Apr 23, 2025
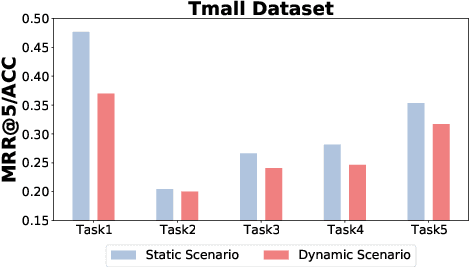
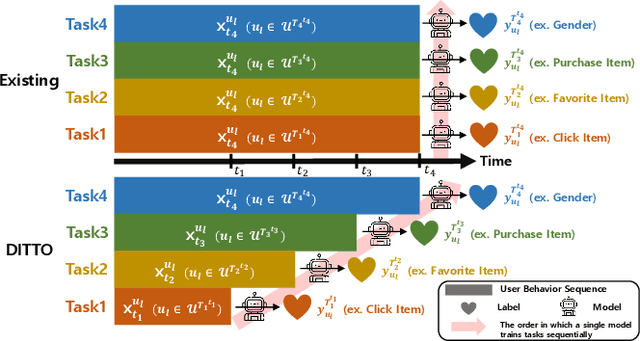
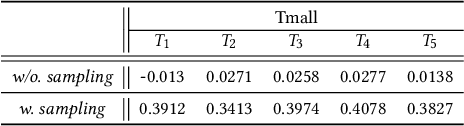
Traditional user modeling (UM) approaches have primarily focused on designing models for a single specific task, but they face limitations in generalization and adaptability across various tasks. Recognizing these challenges, recent studies have shifted towards continual learning (CL)-based universal user representation learning aiming to develop a single model capable of handling multiple tasks. Despite advancements, existing methods are in fact evaluated under an unrealistic scenario that does not consider the passage of time as tasks progress, which overlooks newly emerged items that may change the item distribution of previous tasks. In this paper, we introduce a practical evaluation scenario on which CL-based universal user representation learning approaches should be evaluated, which takes into account the passage of time as tasks progress. Then, we propose a novel framework Dynamic Time-aware continual user representation learner, named DITTO, designed to alleviate catastrophic forgetting despite continuous shifts in item distribution, while also allowing the knowledge acquired from previous tasks to adapt to the current shifted item distribution. Through our extensive experiments, we demonstrate the superiority of DITTO over state-of-the-art methods under a practical evaluation scenario. Our source code is available at https://github.com/seungyoon-Choi/DITTO_official.
Image is All You Need: Towards Efficient and Effective Large Language Model-Based Recommender Systems
Mar 08, 2025Large Language Models (LLMs) have recently emerged as a powerful backbone for recommender systems. Existing LLM-based recommender systems take two different approaches for representing items in natural language, i.e., Attribute-based Representation and Description-based Representation. In this work, we aim to address the trade-off between efficiency and effectiveness that these two approaches encounter, when representing items consumed by users. Based on our interesting observation that there is a significant information overlap between images and descriptions associated with items, we propose a novel method, Image is all you need for LLM-based Recommender system (I-LLMRec). Our main idea is to leverage images as an alternative to lengthy textual descriptions for representing items, aiming at reducing token usage while preserving the rich semantic information of item descriptions. Through extensive experiments, we demonstrate that I-LLMRec outperforms existing methods in both efficiency and effectiveness by leveraging images. Moreover, a further appeal of I-LLMRec is its ability to reduce sensitivity to noise in descriptions, leading to more robust recommendations.
Subgraph Federated Learning for Local Generalization
Mar 06, 2025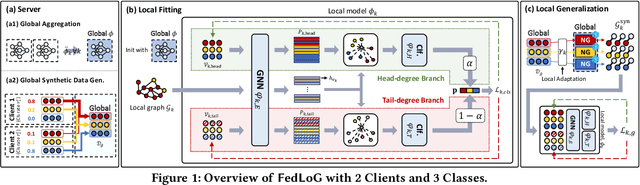
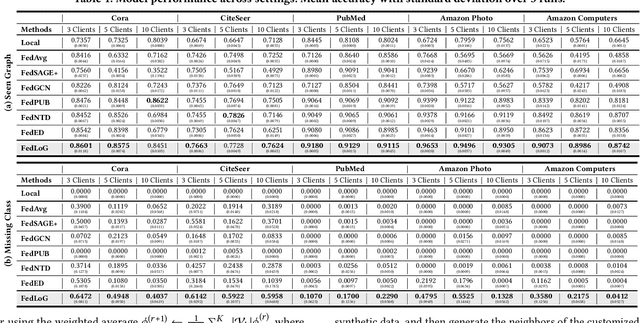
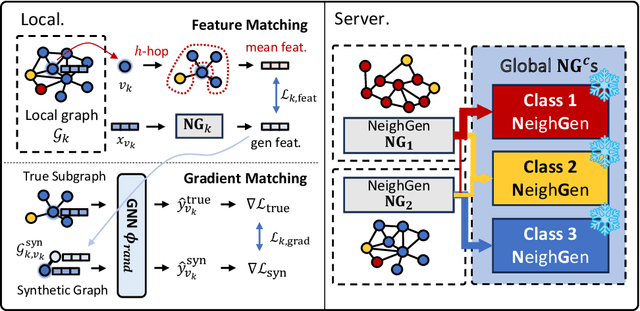
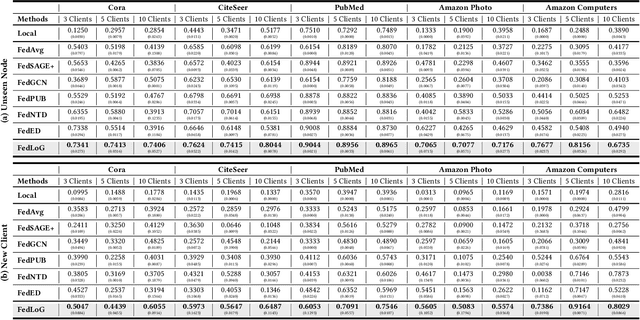
Federated Learning (FL) on graphs enables collaborative model training to enhance performance without compromising the privacy of each client. However, existing methods often overlook the mutable nature of graph data, which frequently introduces new nodes and leads to shifts in label distribution. Since they focus solely on performing well on each client's local data, they are prone to overfitting to their local distributions (i.e., local overfitting), which hinders their ability to generalize to unseen data with diverse label distributions. In contrast, our proposed method, FedLoG, effectively tackles this issue by mitigating local overfitting. Our model generates global synthetic data by condensing the reliable information from each class representation and its structural information across clients. Using these synthetic data as a training set, we alleviate the local overfitting problem by adaptively generalizing the absent knowledge within each local dataset. This enhances the generalization capabilities of local models, enabling them to handle unseen data effectively. Our model outperforms baselines in our proposed experimental settings, which are designed to measure generalization power to unseen data in practical scenarios. Our code is available at https://github.com/sung-won-kim/FedLoG
Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Feb 19, 2025Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users' item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs' ability to understand users' item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Apr 17, 2024

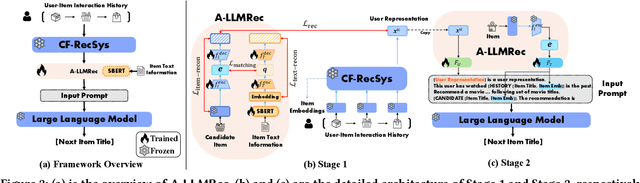

Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
DSLR: Diversity Enhancement and Structure Learning for Rehearsal-based Graph Continual Learning
Feb 23, 2024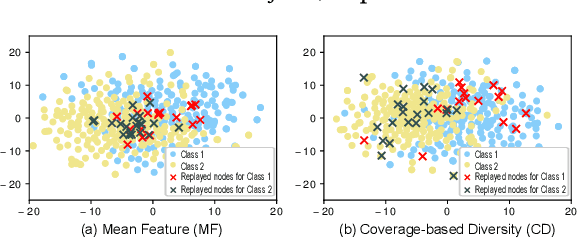
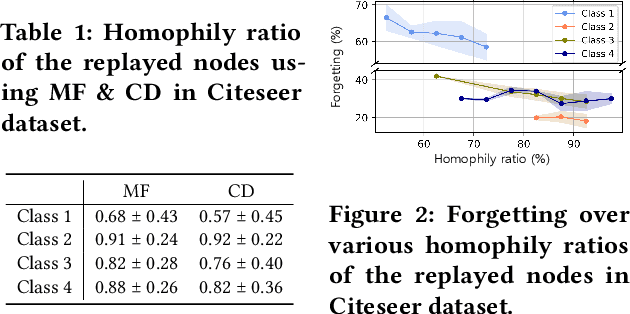

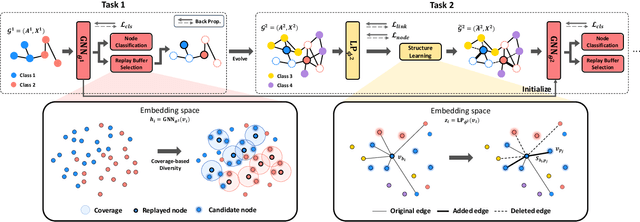
We investigate the replay buffer in rehearsal-based approaches for graph continual learning (GCL) methods. Existing rehearsal-based GCL methods select the most representative nodes for each class and store them in a replay buffer for later use in training subsequent tasks. However, we discovered that considering only the class representativeness of each replayed node makes the replayed nodes to be concentrated around the center of each class, incurring a potential risk of overfitting to nodes residing in those regions, which aggravates catastrophic forgetting. Moreover, as the rehearsal-based approach heavily relies on a few replayed nodes to retain knowledge obtained from previous tasks, involving the replayed nodes that have irrelevant neighbors in the model training may have a significant detrimental impact on model performance. In this paper, we propose a GCL model named DSLR, specifically, we devise a coverage-based diversity (CD) approach to consider both the class representativeness and the diversity within each class of the replayed nodes. Moreover, we adopt graph structure learning (GSL) to ensure that the replayed nodes are connected to truly informative neighbors. Extensive experimental results demonstrate the effectiveness and efficiency of DSLR. Our source code is available at https://github.com/seungyoon-Choi/DSLR_official.
MUSE: Music Recommender System with Shuffle Play Recommendation Enhancement
Aug 26, 2023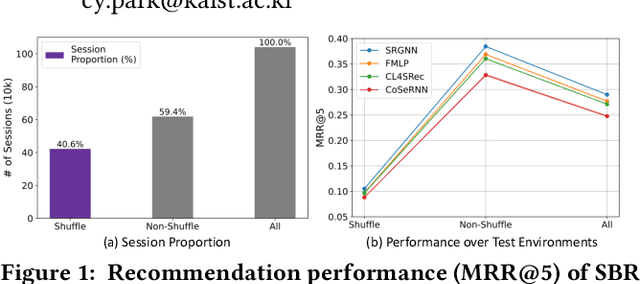
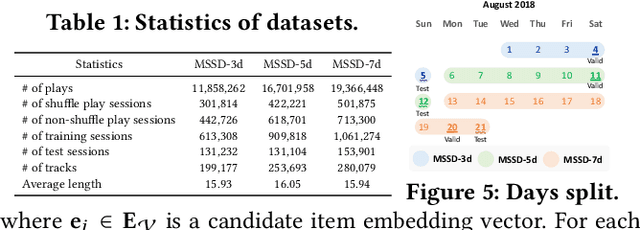
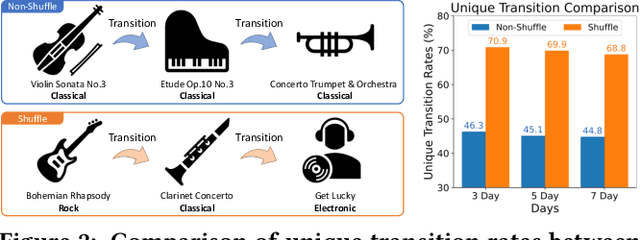
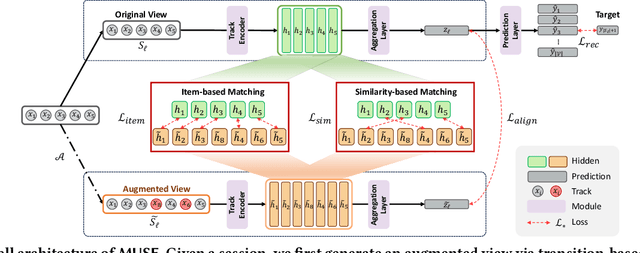
Recommender systems have become indispensable in music streaming services, enhancing user experiences by personalizing playlists and facilitating the serendipitous discovery of new music. However, the existing recommender systems overlook the unique challenges inherent in the music domain, specifically shuffle play, which provides subsequent tracks in a random sequence. Based on our observation that the shuffle play sessions hinder the overall training process of music recommender systems mainly due to the high unique transition rates of shuffle play sessions, we propose a Music Recommender System with Shuffle Play Recommendation Enhancement (MUSE). MUSE employs the self-supervised learning framework that maximizes the agreement between the original session and the augmented session, which is augmented by our novel session augmentation method, called transition-based augmentation. To further facilitate the alignment of the representations between the two views, we devise two fine-grained matching strategies, i.e., item- and similarity-based matching strategies. Through rigorous experiments conducted across diverse environments, we demonstrate MUSE's efficacy over 12 baseline models on a large-scale Music Streaming Sessions Dataset (MSSD) from Spotify. The source code of MUSE is available at \url{https://github.com/yunhak0/MUSE}.
Task Relation-aware Continual User Representation Learning
Jun 01, 2023User modeling, which learns to represent users into a low-dimensional representation space based on their past behaviors, got a surge of interest from the industry for providing personalized services to users. Previous efforts in user modeling mainly focus on learning a task-specific user representation that is designed for a single task. However, since learning task-specific user representations for every task is infeasible, recent studies introduce the concept of universal user representation, which is a more generalized representation of a user that is relevant to a variety of tasks. Despite their effectiveness, existing approaches for learning universal user representations are impractical in real-world applications due to the data requirement, catastrophic forgetting and the limited learning capability for continually added tasks. In this paper, we propose a novel continual user representation learning method, called TERACON, whose learning capability is not limited as the number of learned tasks increases while capturing the relationship between the tasks. The main idea is to introduce an embedding for each task, i.e., task embedding, which is utilized to generate task-specific soft masks that not only allow the entire model parameters to be updated until the end of training sequence, but also facilitate the relationship between the tasks to be captured. Moreover, we introduce a novel knowledge retention module with pseudo-labeling strategy that successfully alleviates the long-standing problem of continual learning, i.e., catastrophic forgetting. Extensive experiments on public and proprietary real-world datasets demonstrate the superiority and practicality of TERACON. Our code is available at https://github.com/Sein-Kim/TERACON.