 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Multi-Agent Reasoning for Biological Perturbation Prediction
Feb 07, 2026Predicting gene regulation responses to biological perturbations requires reasoning about underlying biological causalities. While large language models (LLMs) show promise for such tasks, they are often overwhelmed by the entangled nature of high-dimensional perturbation results. Moreover, recent works have primarily focused on genetic perturbations in single-cell experiments, leaving bulk-cell chemical perturbations, which is central to drug discovery, largely unexplored. Motivated by this, we present LINCSQA, a novel benchmark for predicting target gene regulation under complex chemical perturbations in bulk-cell environments. We further propose PBio-Agent, a multi-agent framework that integrates difficulty-aware task sequencing with iterative knowledge refinement. Our key insight is that genes affected by the same perturbation share causal structure, allowing confidently predicted genes to contextualize more challenging cases. The framework employs specialized agents enriched with biological knowledge graphs, while a synthesis agent integrates outputs and specialized judges ensure logical coherence. PBio-Agent outperforms existing baselines on both LINCSQA and PerturbQA, enabling even smaller models to predict and explain complex biological processes without additional training.
Subgraph Federated Learning for Local Generalization
Mar 06, 2025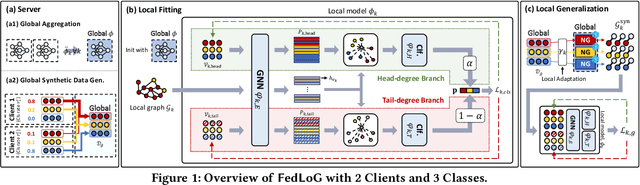
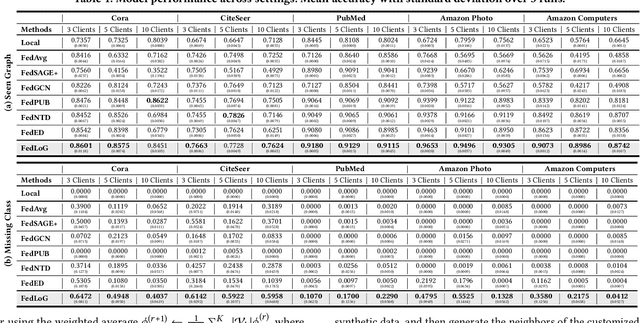
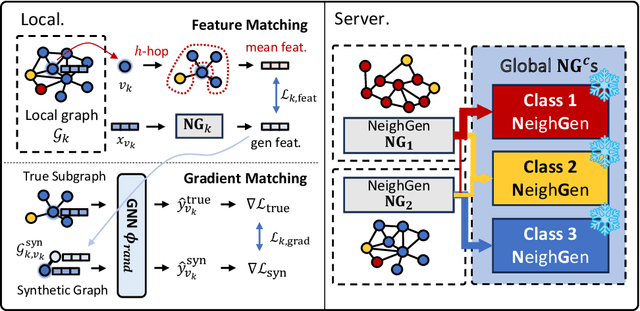
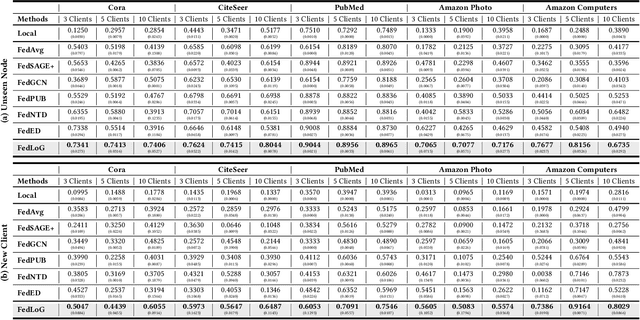
Federated Learning (FL) on graphs enables collaborative model training to enhance performance without compromising the privacy of each client. However, existing methods often overlook the mutable nature of graph data, which frequently introduces new nodes and leads to shifts in label distribution. Since they focus solely on performing well on each client's local data, they are prone to overfitting to their local distributions (i.e., local overfitting), which hinders their ability to generalize to unseen data with diverse label distributions. In contrast, our proposed method, FedLoG, effectively tackles this issue by mitigating local overfitting. Our model generates global synthetic data by condensing the reliable information from each class representation and its structural information across clients. Using these synthetic data as a training set, we alleviate the local overfitting problem by adaptively generalizing the absent knowledge within each local dataset. This enhances the generalization capabilities of local models, enabling them to handle unseen data effectively. Our model outperforms baselines in our proposed experimental settings, which are designed to measure generalization power to unseen data in practical scenarios. Our code is available at https://github.com/sung-won-kim/FedLoG
3D Interaction Geometric Pre-training for Molecular Relational Learning
Dec 04, 2024Molecular Relational Learning (MRL) is a rapidly growing field that focuses on understanding the interaction dynamics between molecules, which is crucial for applications ranging from catalyst engineering to drug discovery. Despite recent progress, earlier MRL approaches are limited to using only the 2D topological structure of molecules, as obtaining the 3D interaction geometry remains prohibitively expensive. This paper introduces a novel 3D geometric pre-training strategy for MRL (3DMRL) that incorporates a 3D virtual interaction environment, overcoming the limitations of costly traditional quantum mechanical calculation methods. With the constructed 3D virtual interaction environment, 3DMRL trains 2D MRL model to learn the overall 3D geometric information of molecular interaction through contrastive learning. Moreover, fine-grained interaction between molecules is learned through force prediction loss, which is crucial in understanding the wide range of molecular interaction processes. Extensive experiments on various tasks using real-world datasets, including out-of-distribution and extrapolation scenarios, demonstrate the effectiveness of 3DMRL, showing up to a 24.93\% improvement in performance across 40 tasks.
MUSE: Music Recommender System with Shuffle Play Recommendation Enhancement
Aug 26, 2023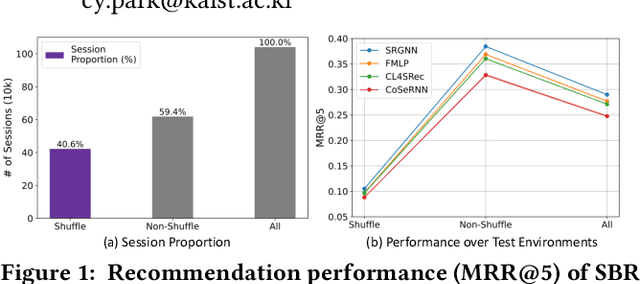
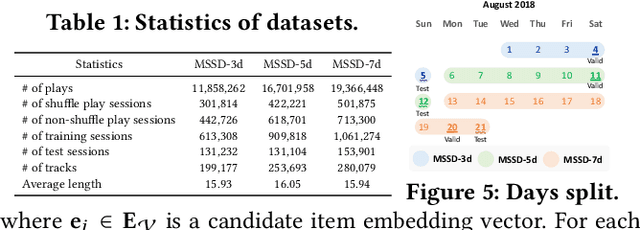
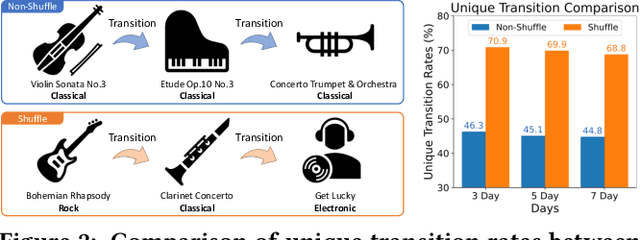
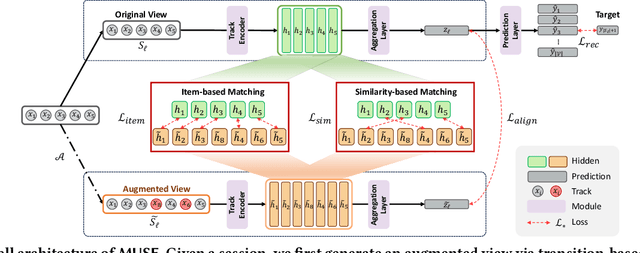
Recommender systems have become indispensable in music streaming services, enhancing user experiences by personalizing playlists and facilitating the serendipitous discovery of new music. However, the existing recommender systems overlook the unique challenges inherent in the music domain, specifically shuffle play, which provides subsequent tracks in a random sequence. Based on our observation that the shuffle play sessions hinder the overall training process of music recommender systems mainly due to the high unique transition rates of shuffle play sessions, we propose a Music Recommender System with Shuffle Play Recommendation Enhancement (MUSE). MUSE employs the self-supervised learning framework that maximizes the agreement between the original session and the augmented session, which is augmented by our novel session augmentation method, called transition-based augmentation. To further facilitate the alignment of the representations between the two views, we devise two fine-grained matching strategies, i.e., item- and similarity-based matching strategies. Through rigorous experiments conducted across diverse environments, we demonstrate MUSE's efficacy over 12 baseline models on a large-scale Music Streaming Sessions Dataset (MSSD) from Spotify. The source code of MUSE is available at \url{https://github.com/yunhak0/MUSE}.
GraFN: Semi-Supervised Node Classification on Graph with Few Labels via Non-Parametric Distribution Assignment
Apr 07, 2022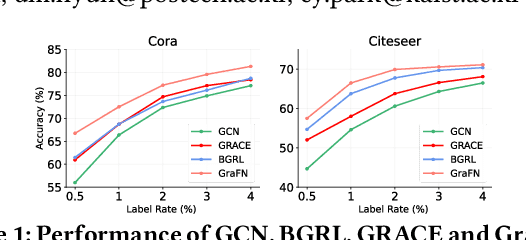
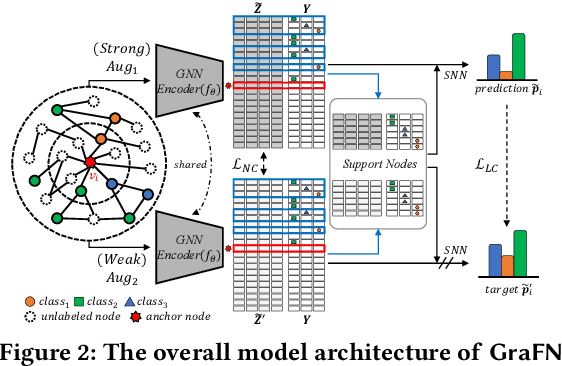
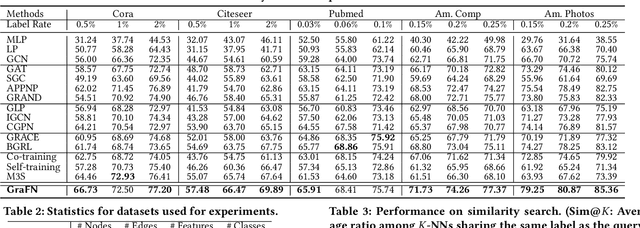
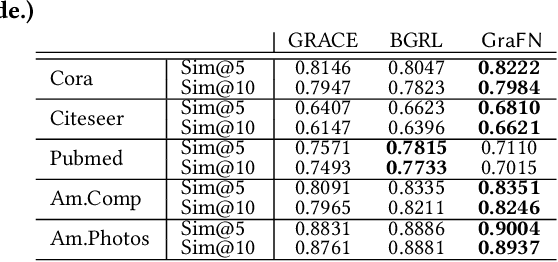
Despite the success of Graph Neural Networks (GNNs) on various applications, GNNs encounter significant performance degradation when the amount of supervision signals, i.e., number of labeled nodes, is limited, which is expected as GNNs are trained solely based on the supervision obtained from the labeled nodes. On the other hand,recent self-supervised learning paradigm aims to train GNNs by solving pretext tasks that do not require any labeled nodes, and it has shown to even outperform GNNs trained with few labeled nodes. However, a major drawback of self-supervised methods is that they fall short of learning class discriminative node representations since no labeled information is utilized during training. To this end, we propose a novel semi-supervised method for graphs, GraFN, that leverages few labeled nodes to ensure nodes that belong to the same class to be grouped together, thereby achieving the best of both worlds of semi-supervised and self-supervised methods. Specifically, GraFN randomly samples support nodes from labeled nodes and anchor nodes from the entire graph. Then, it minimizes the difference between two predicted class distributions that are non-parametrically assigned by anchor-supports similarity from two differently augmented graphs. We experimentally show that GraFN surpasses both the semi-supervised and self-supervised methods in terms of node classification on real-world graphs. The source code for GraFN is available at https://github.com/Junseok0207/GraFN.