 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Music Recommender System with Shuffle Play Recommendation Enhancement
Aug 26, 2023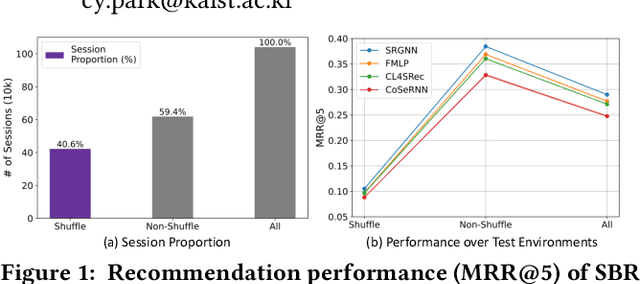
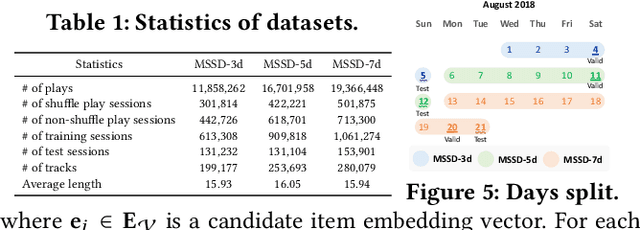
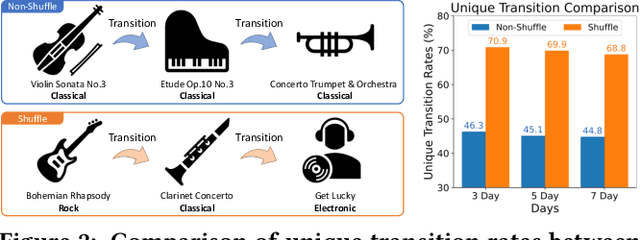
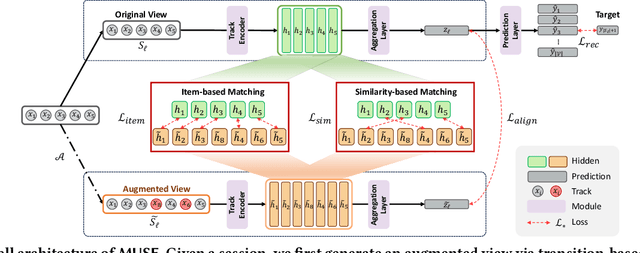
Recommender systems have become indispensable in music streaming services, enhancing user experiences by personalizing playlists and facilitating the serendipitous discovery of new music. However, the existing recommender systems overlook the unique challenges inherent in the music domain, specifically shuffle play, which provides subsequent tracks in a random sequence. Based on our observation that the shuffle play sessions hinder the overall training process of music recommender systems mainly due to the high unique transition rates of shuffle play sessions, we propose a Music Recommender System with Shuffle Play Recommendation Enhancement (MUSE). MUSE employs the self-supervised learning framework that maximizes the agreement between the original session and the augmented session, which is augmented by our novel session augmentation method, called transition-based augmentation. To further facilitate the alignment of the representations between the two views, we devise two fine-grained matching strategies, i.e., item- and similarity-based matching strategies. Through rigorous experiments conducted across diverse environments, we demonstrate MUSE's efficacy over 12 baseline models on a large-scale Music Streaming Sessions Dataset (MSSD) from Spotify. The source code of MUSE is available at \url{https://github.com/yunhak0/MUSE}.
Conditional Graph Information Bottleneck for Molecular Relational Learning
Apr 29, 2023



Molecular relational learning, whose goal is to learn the interaction behavior between molecular pairs, got a surge of interest in molecular sciences due to its wide range of applications. Recently, graph neural networks have recently shown great success in molecular relational learning by modeling a molecule as a graph structure, and considering atom-level interactions between two molecules. Despite their success, existing molecular relational learning methods tend to overlook the nature of chemistry, i.e., a chemical compound is composed of multiple substructures such as functional groups that cause distinctive chemical reactions. In this work, we propose a novel relational learning framework, called CGIB, that predicts the interaction behavior between a pair of graphs by detecting core subgraphs therein. The main idea is, given a pair of graphs, to find a subgraph from a graph that contains the minimal sufficient information regarding the task at hand conditioned on the paired graph based on the principle of conditional graph information bottleneck. We argue that our proposed method mimics the nature of chemical reactions, i.e., the core substructure of a molecule varies depending on which other molecule it interacts with. Extensive experiments on various tasks with real-world datasets demonstrate the superiority of CGIB over state-of-the-art baselines. Our code is available at https://github.com/Namkyeong/CGIB.
MELT: Mutual Enhancement of Long-Tailed User and Item for Sequential Recommendation
Apr 17, 2023



The long-tailed problem is a long-standing challenge in Sequential Recommender Systems (SRS) in which the problem exists in terms of both users and items. While many existing studies address the long-tailed problem in SRS, they only focus on either the user or item perspective. However, we discover that the long-tailed user and item problems exist at the same time, and considering only either one of them leads to sub-optimal performance of the other one. In this paper, we propose a novel framework for SRS, called Mutual Enhancement of Long-Tailed user and item (MELT), that jointly alleviates the long-tailed problem in the perspectives of both users and items. MELT consists of bilateral branches each of which is responsible for long-tailed users and items, respectively, and the branches are trained to mutually enhance each other, which is trained effectively by a curriculum learning-based training. MELT is model-agnostic in that it can be seamlessly integrated with existing SRS models. Extensive experiments on eight datasets demonstrate the benefit of alleviating the long-tailed problems in terms of both users and items even without sacrificing the performance of head users and items, which has not been achieved by existing methods. To the best of our knowledge, MELT is the first work that jointly alleviates the long-tailed user and item problems in SRS.
Predicting Density of States via Multi-modal Transformer
Mar 13, 2023The density of states (DOS) is a spectral property of materials, which provides fundamental insights on various characteristics of materials. In this paper, we propose a model to predict the DOS by reflecting the nature of DOS: DOS determines the general distribution of states as a function of energy. Specifically, we integrate the heterogeneous information obtained from the crystal structure and the energies via multi-modal transformer, thereby modeling the complex relationships between the atoms in the crystal structure, and various energy levels. Extensive experiments on two types of DOS, i.e., Phonon DOS and Electron DOS, with various real-world scenarios demonstrate the superiority of DOSTransformer. The source code for DOSTransformer is available at https://github.com/HeewoongNoh/DOSTransformer.
Dynamic Multi-Behavior Sequence Modeling for Next Item Recommendation
Jan 28, 2023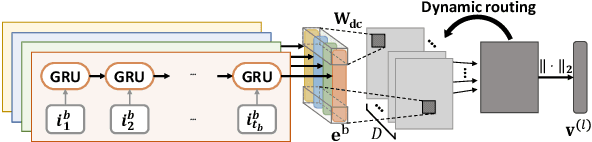
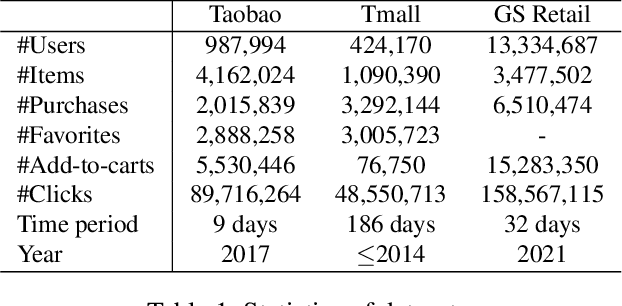
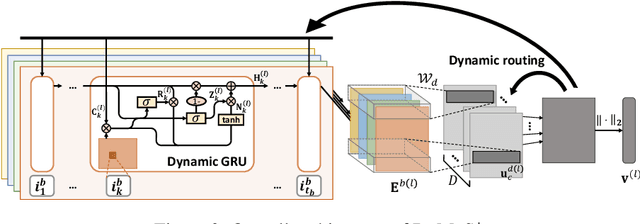
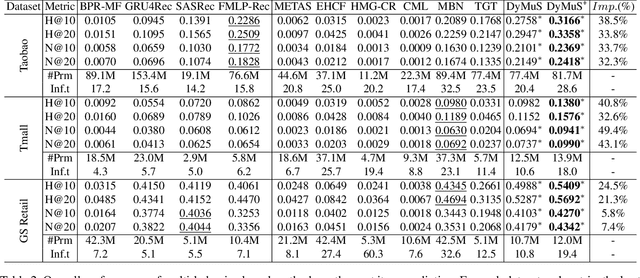
Sequential Recommender Systems (SRSs) aim to predict the next item that users will consume, by modeling the user interests within their item sequences. While most existing SRSs focus on a single type of user behavior, only a few pay attention to multi-behavior sequences, although they are very common in real-world scenarios. It is challenging to effectively capture the user interests within multi-behavior sequences, because the information about user interests is entangled throughout the sequences in complex relationships. To this end, we first address the characteristics of multi-behavior sequences that should be considered in SRSs, and then propose novel methods for Dynamic Multi-behavior Sequence modeling named DyMuS, which is a light version, and DyMuS+, which is an improved version, considering the characteristics. DyMuS first encodes each behavior sequence independently, and then combines the encoded sequences using dynamic routing, which dynamically integrates information required in the final result from among many candidates, based on correlations between the sequences. DyMuS+, furthermore, applies the dynamic routing even to encoding each behavior sequence to further capture the correlations at item-level. Moreover, we release a new, large and up-to-date dataset for multi-behavior recommendation. Our experiments on DyMuS and DyMuS+ show their superiority and the significance of capturing the characteristics of multi-behavior sequences.
Generating Multiple-Length Summaries via Reinforcement Learning for Unsupervised Sentence Summarization
Dec 21, 2022Sentence summarization shortens given texts while maintaining core contents of the texts. Unsupervised approaches have been studied to summarize texts without human-written summaries. However, recent unsupervised models are extractive, which remove words from texts and thus they are less flexible than abstractive summarization. In this work, we devise an abstractive model based on reinforcement learning without ground-truth summaries. We formulate the unsupervised summarization based on the Markov decision process with rewards representing the summary quality. To further enhance the summary quality, we develop a multi-summary learning mechanism that generates multiple summaries with varying lengths for a given text, while making the summaries mutually enhance each other. Experimental results show that the proposed model substantially outperforms both abstractive and extractive models, yet frequently generating new words not contained in input texts.
Heterogeneous Graph Learning for Multi-modal Medical Data Analysis
Nov 28, 2022



Routine clinical visits of a patient produce not only image data, but also non-image data containing clinical information regarding the patient, i.e., medical data is multi-modal in nature. Such heterogeneous modalities offer different and complementary perspectives on the same patient, resulting in more accurate clinical decisions when they are properly combined. However, despite its significance, how to effectively fuse the multi-modal medical data into a unified framework has received relatively little attention. In this paper, we propose an effective graph-based framework called HetMed (Heterogeneous Graph Learning for Multi-modal Medical Data Analysis) for fusing the multi-modal medical data. Specifically, we construct a multiplex network that incorporates multiple types of non-image features of patients to capture the complex relationship between patients in a systematic way, which leads to more accurate clinical decisions. Extensive experiments on various real-world datasets demonstrate the superiority and practicality of HetMed. The source code for HetMed is available at https://github.com/Sein-Kim/Multimodal-Medical.
Beyond Learning from Next Item: Sequential Recommendation via Personalized Interest Sustainability
Sep 14, 2022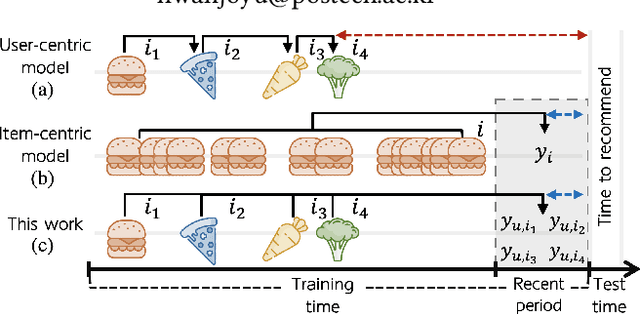
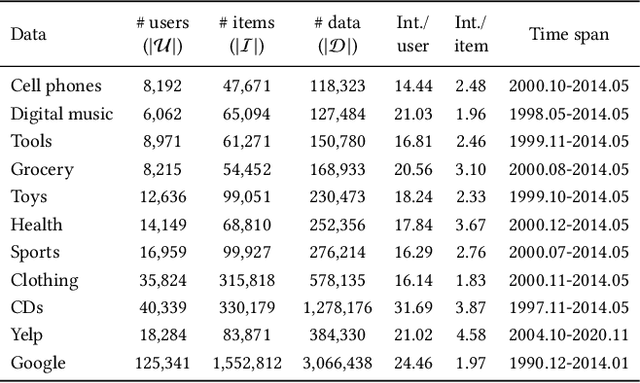
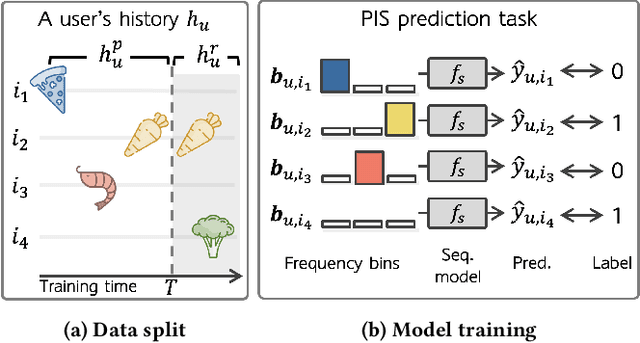
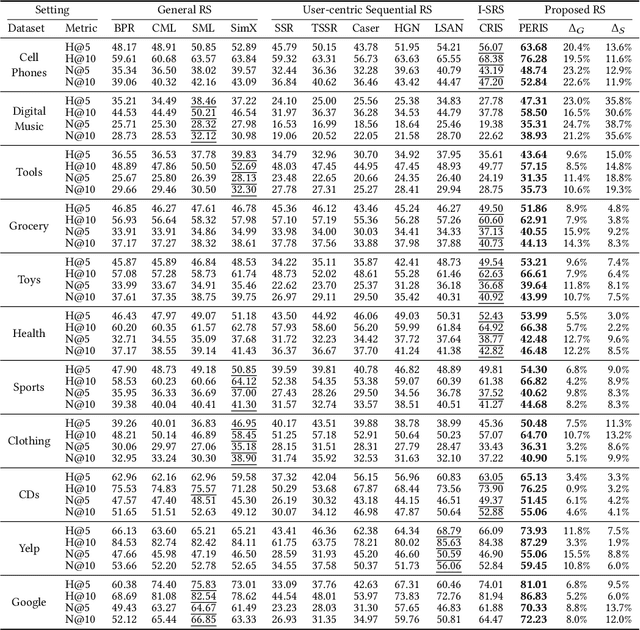
Sequential recommender systems have shown effective suggestions by capturing users' interest drift. There have been two groups of existing sequential models: user- and item-centric models. The user-centric models capture personalized interest drift based on each user's sequential consumption history, but do not explicitly consider whether users' interest in items sustains beyond the training time, i.e., interest sustainability. On the other hand, the item-centric models consider whether users' general interest sustains after the training time, but it is not personalized. In this work, we propose a recommender system taking advantages of the models in both categories. Our proposed model captures personalized interest sustainability, indicating whether each user's interest in items will sustain beyond the training time or not. We first formulate a task that requires to predict which items each user will consume in the recent period of the training time based on users' consumption history. We then propose simple yet effective schemes to augment users' sparse consumption history. Extensive experiments show that the proposed model outperforms 10 baseline models on 11 real-world datasets. The codes are available at https://github.com/dmhyun/PERIS.
Relational Self-Supervised Learning on Graphs
Aug 21, 2022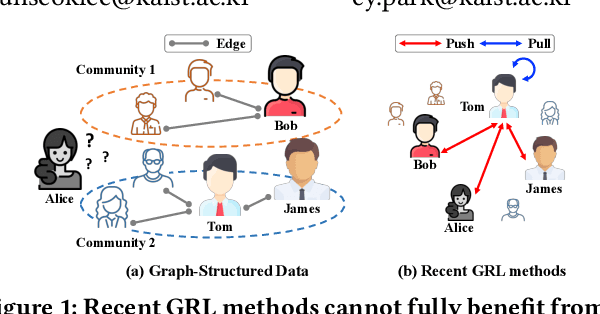

Over the past few years, graph representation learning (GRL) has been a powerful strategy for analyzing graph-structured data. Recently, GRL methods have shown promising results by adopting self-supervised learning methods developed for learning representations of images. Despite their success, existing GRL methods tend to overlook an inherent distinction between images and graphs, i.e., images are assumed to be independently and identically distributed, whereas graphs exhibit relational information among data instances, i.e., nodes. To fully benefit from the relational information inherent in the graph-structured data, we propose a novel GRL method, called RGRL, that learns from the relational information generated from the graph itself. RGRL learns node representations such that the relationship among nodes is invariant to augmentations, i.e., augmentation-invariant relationship, which allows the node representations to vary as long as the relationship among the nodes is preserved. By considering the relationship among nodes in both global and local perspectives, RGRL overcomes limitations of previous contrastive and non-contrastive methods, and achieves the best of both worlds. Extensive experiments on fourteen benchmark datasets over various downstream tasks demonstrate the superiority of RGRL over state-of-the-art baselines. The source code for RGRL is available at https://github.com/Namkyeong/RGRL.
GraFN: Semi-Supervised Node Classification on Graph with Few Labels via Non-Parametric Distribution Assignment
Apr 07, 2022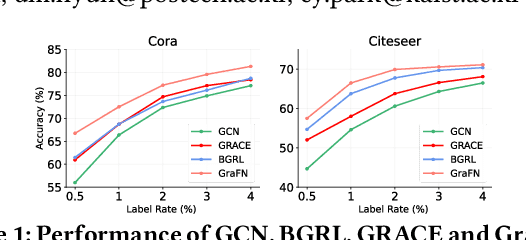
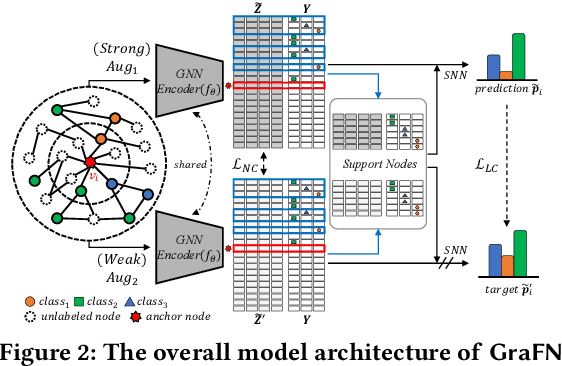
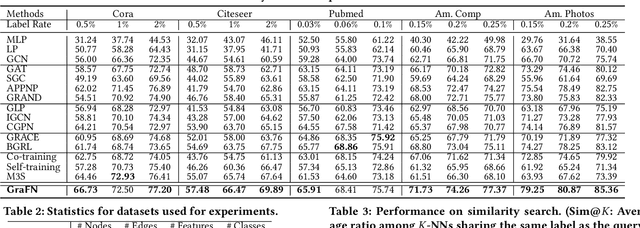
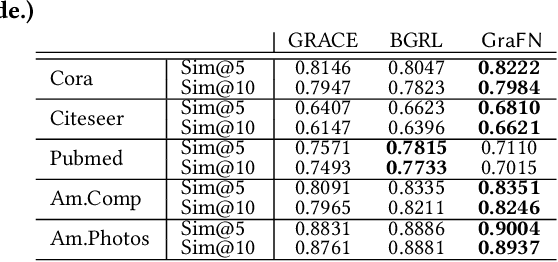
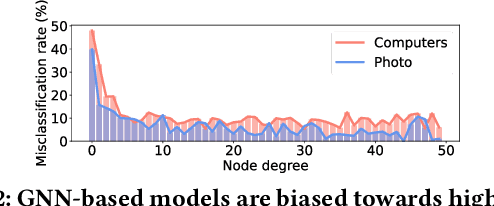
Despite the success of Graph Neural Networks (GNNs) on various applications, GNNs encounter significant performance degradation when the amount of supervision signals, i.e., number of labeled nodes, is limited, which is expected as GNNs are trained solely based on the supervision obtained from the labeled nodes. On the other hand,recent self-supervised learning paradigm aims to train GNNs by solving pretext tasks that do not require any labeled nodes, and it has shown to even outperform GNNs trained with few labeled nodes. However, a major drawback of self-supervised methods is that they fall short of learning class discriminative node representations since no labeled information is utilized during training. To this end, we propose a novel semi-supervised method for graphs, GraFN, that leverages few labeled nodes to ensure nodes that belong to the same class to be grouped together, thereby achieving the best of both worlds of semi-supervised and self-supervised methods. Specifically, GraFN randomly samples support nodes from labeled nodes and anchor nodes from the entire graph. Then, it minimizes the difference between two predicted class distributions that are non-parametrically assigned by anchor-supports similarity from two differently augmented graphs. We experimentally show that GraFN surpasses both the semi-supervised and self-supervised methods in terms of node classification on real-world graphs. The source code for GraFN is available at https://github.com/Junseok0207/GraFN.