 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThickness-aware E(3)-Equivariant 3D Mesh Neural Networks
May 27, 2025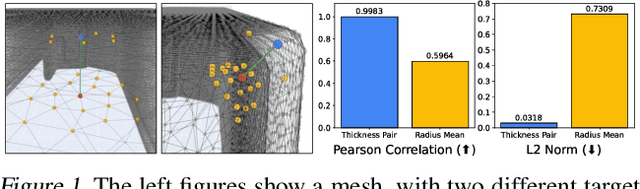
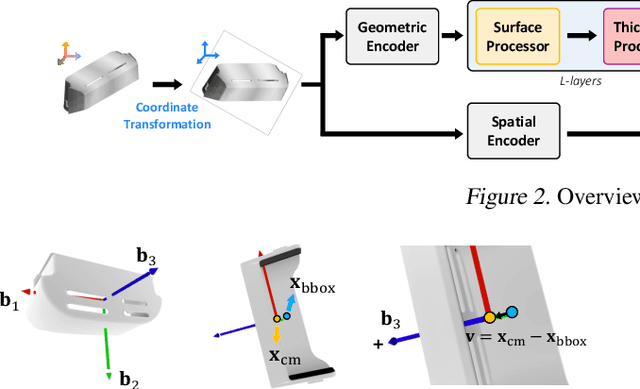
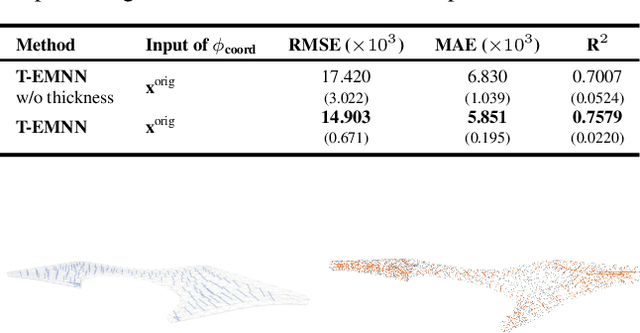

Mesh-based 3D static analysis methods have recently emerged as efficient alternatives to traditional computational numerical solvers, significantly reducing computational costs and runtime for various physics-based analyses. However, these methods primarily focus on surface topology and geometry, often overlooking the inherent thickness of real-world 3D objects, which exhibits high correlations and similar behavior between opposing surfaces. This limitation arises from the disconnected nature of these surfaces and the absence of internal edge connections within the mesh. In this work, we propose a novel framework, the Thickness-aware E(3)-Equivariant 3D Mesh Neural Network (T-EMNN), that effectively integrates the thickness of 3D objects while maintaining the computational efficiency of surface meshes. Additionally, we introduce data-driven coordinates that encode spatial information while preserving E(3)-equivariance or invariance properties, ensuring consistent and robust analysis. Evaluations on a real-world industrial dataset demonstrate the superior performance of T-EMNN in accurately predicting node-level 3D deformations, effectively capturing thickness effects while maintaining computational efficiency.
Subgraph Federated Learning for Local Generalization
Mar 06, 2025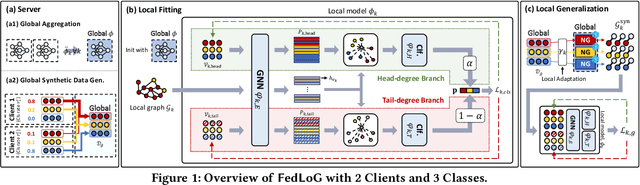
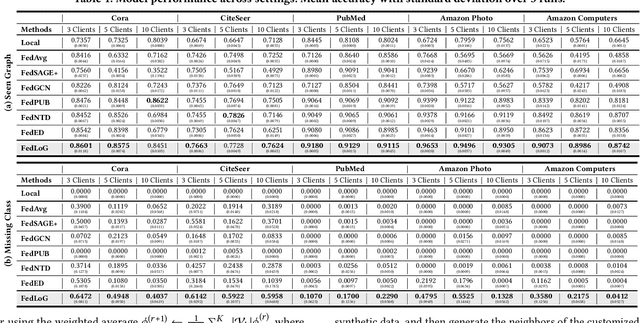
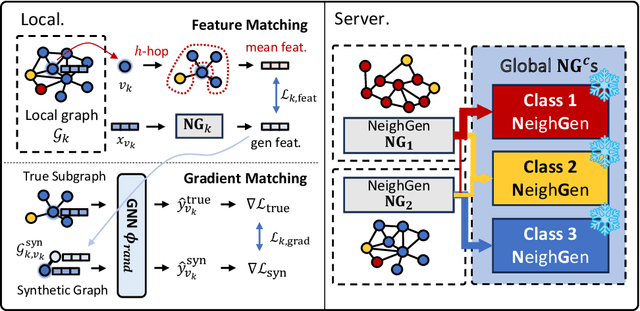
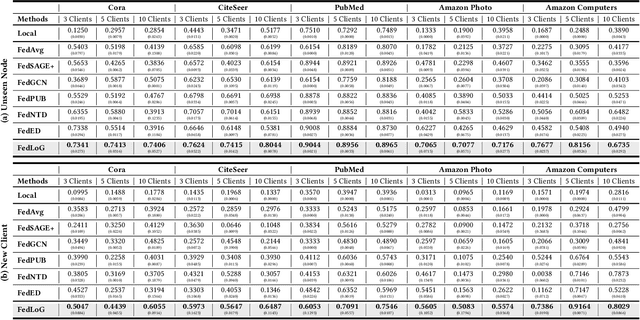
Federated Learning (FL) on graphs enables collaborative model training to enhance performance without compromising the privacy of each client. However, existing methods often overlook the mutable nature of graph data, which frequently introduces new nodes and leads to shifts in label distribution. Since they focus solely on performing well on each client's local data, they are prone to overfitting to their local distributions (i.e., local overfitting), which hinders their ability to generalize to unseen data with diverse label distributions. In contrast, our proposed method, FedLoG, effectively tackles this issue by mitigating local overfitting. Our model generates global synthetic data by condensing the reliable information from each class representation and its structural information across clients. Using these synthetic data as a training set, we alleviate the local overfitting problem by adaptively generalizing the absent knowledge within each local dataset. This enhances the generalization capabilities of local models, enabling them to handle unseen data effectively. Our model outperforms baselines in our proposed experimental settings, which are designed to measure generalization power to unseen data in practical scenarios. Our code is available at https://github.com/sung-won-kim/FedLoG
ETTA: Elucidating the Design Space of Text-to-Audio Models
Dec 26, 2024



Recent years have seen significant progress in Text-To-Audio (TTA) synthesis, enabling users to enrich their creative workflows with synthetic audio generated from natural language prompts. Despite this progress, the effects of data, model architecture, training objective functions, and sampling strategies on target benchmarks are not well understood. With the purpose of providing a holistic understanding of the design space of TTA models, we set up a large-scale empirical experiment focused on diffusion and flow matching models. Our contributions include: 1) AF-Synthetic, a large dataset of high quality synthetic captions obtained from an audio understanding model; 2) a systematic comparison of different architectural, training, and inference design choices for TTA models; 3) an analysis of sampling methods and their Pareto curves with respect to generation quality and inference speed. We leverage the knowledge obtained from this extensive analysis to propose our best model dubbed Elucidated Text-To-Audio (ETTA). When evaluated on AudioCaps and MusicCaps, ETTA provides improvements over the baselines trained on publicly available data, while being competitive with models trained on proprietary data. Finally, we show ETTA's improved ability to generate creative audio following complex and imaginative captions -- a task that is more challenging than current benchmarks.
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Aug 27, 2024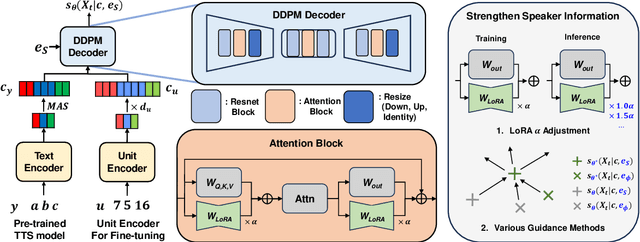
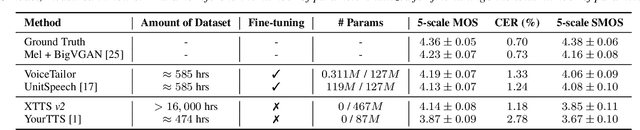
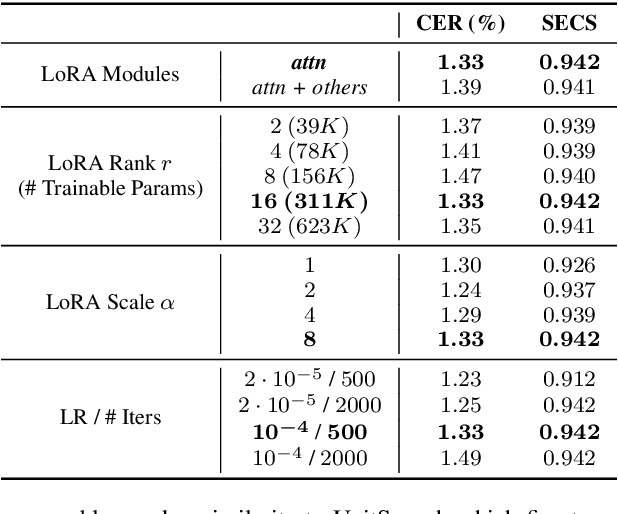
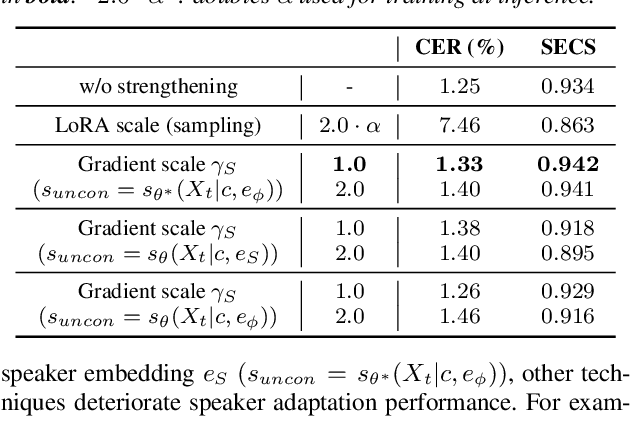
We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25\% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.
Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck
Jun 19, 2024



Temporal Graph Neural Networks (TGNN) have the ability to capture both the graph topology and dynamic dependencies of interactions within a graph over time. There has been a growing need to explain the predictions of TGNN models due to the difficulty in identifying how past events influence their predictions. Since the explanation model for a static graph cannot be readily applied to temporal graphs due to its inability to capture temporal dependencies, recent studies proposed explanation models for temporal graphs. However, existing explanation models for temporal graphs rely on post-hoc explanations, requiring separate models for prediction and explanation, which is limited in two aspects: efficiency and accuracy of explanation. In this work, we propose a novel built-in explanation framework for temporal graphs, called Self-Explainable Temporal Graph Networks based on Graph Information Bottleneck (TGIB). TGIB provides explanations for event occurrences by introducing stochasticity in each temporal event based on the Information Bottleneck theory. Experimental results demonstrate the superiority of TGIB in terms of both the link prediction performance and explainability compared to state-of-the-art methods. This is the first work that simultaneously performs prediction and explanation for temporal graphs in an end-to-end manner.
DSLR: Diversity Enhancement and Structure Learning for Rehearsal-based Graph Continual Learning
Feb 23, 2024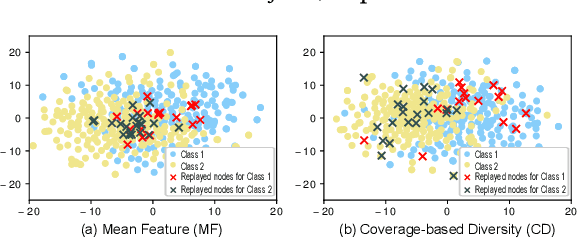
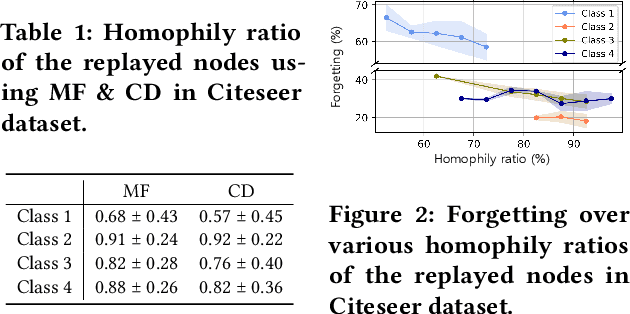

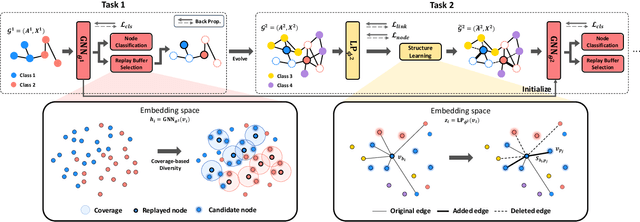
We investigate the replay buffer in rehearsal-based approaches for graph continual learning (GCL) methods. Existing rehearsal-based GCL methods select the most representative nodes for each class and store them in a replay buffer for later use in training subsequent tasks. However, we discovered that considering only the class representativeness of each replayed node makes the replayed nodes to be concentrated around the center of each class, incurring a potential risk of overfitting to nodes residing in those regions, which aggravates catastrophic forgetting. Moreover, as the rehearsal-based approach heavily relies on a few replayed nodes to retain knowledge obtained from previous tasks, involving the replayed nodes that have irrelevant neighbors in the model training may have a significant detrimental impact on model performance. In this paper, we propose a GCL model named DSLR, specifically, we devise a coverage-based diversity (CD) approach to consider both the class representativeness and the diversity within each class of the replayed nodes. Moreover, we adopt graph structure learning (GSL) to ensure that the replayed nodes are connected to truly informative neighbors. Extensive experimental results demonstrate the effectiveness and efficiency of DSLR. Our source code is available at https://github.com/seungyoon-Choi/DSLR_official.
Scaling NVIDIA's Multi-speaker Multi-lingual TTS Systems with Zero-Shot TTS to Indic Languages
Jan 29, 2024In this paper, we describe the TTS models developed by NVIDIA for the MMITS-VC (Multi-speaker, Multi-lingual Indic TTS with Voice Cloning) 2024 Challenge. In Tracks 1 and 2, we utilize RAD-MMM to perform few-shot TTS by training additionally on 5 minutes of target speaker data. In Track 3, we utilize P-Flow to perform zero-shot TTS by training on the challenge dataset as well as external datasets. We use HiFi-GAN vocoders for all submissions. RAD-MMM performs competitively on Tracks 1 and 2, while P-Flow ranks first on Track 3, with mean opinion score (MOS) 4.4 and speaker similarity score (SMOS) of 3.62.
Interpretable Prototype-based Graph Information Bottleneck
Oct 30, 2023The success of Graph Neural Networks (GNNs) has led to a need for understanding their decision-making process and providing explanations for their predictions, which has given rise to explainable AI (XAI) that offers transparent explanations for black-box models. Recently, the use of prototypes has successfully improved the explainability of models by learning prototypes to imply training graphs that affect the prediction. However, these approaches tend to provide prototypes with excessive information from the entire graph, leading to the exclusion of key substructures or the inclusion of irrelevant substructures, which can limit both the interpretability and the performance of the model in downstream tasks. In this work, we propose a novel framework of explainable GNNs, called interpretable Prototype-based Graph Information Bottleneck (PGIB) that incorporates prototype learning within the information bottleneck framework to provide prototypes with the key subgraph from the input graph that is important for the model prediction. This is the first work that incorporates prototype learning into the process of identifying the key subgraphs that have a critical impact on the prediction performance. Extensive experiments, including qualitative analysis, demonstrate that PGIB outperforms state-of-the-art methods in terms of both prediction performance and explainability.
UnitSpeech: Speaker-adaptive Speech Synthesis with Untranscribed Data
Jun 28, 2023We propose UnitSpeech, a speaker-adaptive speech synthesis method that fine-tunes a diffusion-based text-to-speech (TTS) model using minimal untranscribed data. To achieve this, we use the self-supervised unit representation as a pseudo transcript and integrate the unit encoder into the pre-trained TTS model. We train the unit encoder to provide speech content to the diffusion-based decoder and then fine-tune the decoder for speaker adaptation to the reference speaker using a single $<$unit, speech$>$ pair. UnitSpeech performs speech synthesis tasks such as TTS and voice conversion (VC) in a personalized manner without requiring model re-training for each task. UnitSpeech achieves comparable and superior results on personalized TTS and any-to-any VC tasks compared to previous baselines. Our model also shows widespread adaptive performance on real-world data and other tasks that use a unit sequence as input.
Unsupervised Episode Generation for Graph Meta-learning
Jun 27, 2023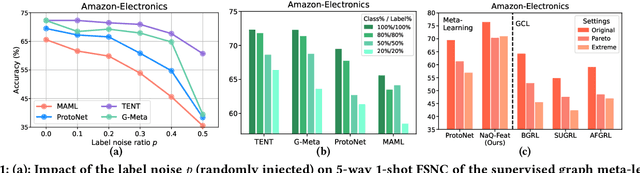
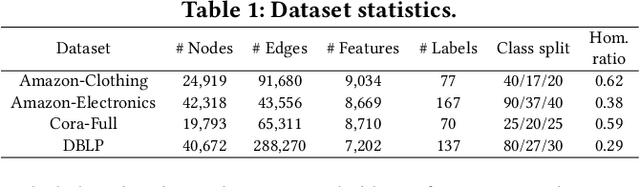
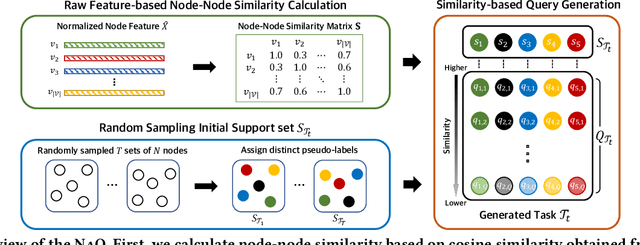
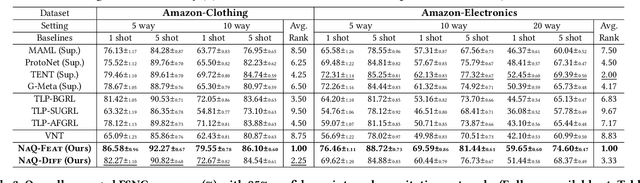
In this paper, we investigate Unsupervised Episode Generation methods to solve Few-Shot Node-Classification (FSNC) problem via Meta-learning without labels. Dominant meta-learning methodologies for FSNC were developed under the existence of abundant labeled nodes for training, which however may not be possible to obtain in the real-world. Although few studies have been proposed to tackle the label-scarcity problem, they still rely on a limited amount of labeled data, which hinders the full utilization of the information of all nodes in a graph. Despite the effectiveness of Self-Supervised Learning (SSL) approaches on FSNC without labels, they mainly learn generic node embeddings without consideration on the downstream task to be solved, which may limit its performance. In this work, we propose unsupervised episode generation methods to benefit from their generalization ability for FSNC tasks while resolving label-scarcity problem. We first propose a method that utilizes graph augmentation to generate training episodes called g-UMTRA, which however has several drawbacks, i.e., 1) increased training time due to the computation of augmented features and 2) low applicability to existing baselines. Hence, we propose Neighbors as Queries (NaQ), which generates episodes from structural neighbors found by graph diffusion. Our proposed methods are model-agnostic, that is, they can be plugged into any existing graph meta-learning models, while not sacrificing much of their performance or sometimes even improving them. We provide theoretical insights to support why our unsupervised episode generation methodologies work, and extensive experimental results demonstrate the potential of our unsupervised episode generation methods for graph meta-learning towards FSNC problems.