 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalize-then-Store: Benchmarking and Learning Personalized Memory for Long-horizon Agents
May 25, 2026Existing large language model (LLM) based memory systems apply universal, static policies that overlook a fundamental reality: the contexts that are worth storing in memory are different across users. This misalignment wastes limited memory budget on transient interactions while failing to preserve critical context for long horizon tasks. To address this gap, we investigate an underexplored question: can LLM based memory systems learn personalized memory policies? We introduce PerMemBench, the first benchmark for evaluating personalized memory systems, featuring multi year, multi domain interaction histories across diverse user personas. We further present the first empirical study of memory personalization, proposing session level storage gating, a lightweight framework that selectively bypasses memory operations for transient sessions. Our study confirms that personalization yields substantial retention gains under perfect gating, yet reveals that accurate gating remains an open and critical challenge.
Reasoning Structure Matters for Safety Alignment of Reasoning Models
Apr 21, 2026Large reasoning models (LRMs) achieve strong performance on complex reasoning tasks but often generate harmful responses to malicious user queries. This paper investigates the underlying cause of these safety risks and shows that the issue lies in the reasoning structure itself. Based on this insight, we claim that effective safety alignment can be achieved by altering the reasoning structure. We propose AltTrain, a simple yet effective post training method that explicitly alters the reasoning structure of LRMs. AltTrain is both practical and generalizable, requiring no complex reinforcement learning (RL) training or reward design, only supervised finetuning (SFT) with a lightweight 1K training examples. Experiments across LRM backbones and model sizes demonstrate strong safety alignment, along with robust generalization across reasoning, QA, summarization, and multilingual setting.
Rethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation
Mar 26, 2026Failure attribution is essential for diagnosing and improving multi-agent systems (MAS), yet existing benchmarks and methods largely assume a single deterministic root cause for each failure. In practice, MAS failures often admit multiple plausible attributions due to complex inter-agent dependencies and ambiguous execution trajectories. We revisit MAS failure attribution from a multi-perspective standpoint and propose multi-perspective failure attribution, a practical paradigm that explicitly accounts for attribution ambiguity. To support this setting, we introduce MP-Bench, the first benchmark designed for multi-perspective failure attribution in MAS, along with a new evaluation protocol tailored to this paradigm. Through extensive experiments, we find that prior conclusions suggesting LLMs struggle with failure attribution are largely driven by limitations in existing benchmark designs. Our results highlight the necessity of multi-perspective benchmarks and evaluation protocols for realistic and reliable MAS debugging.
Self-EvolveRec: Self-Evolving Recommender Systems with LLM-based Directional Feedback
Feb 13, 2026Traditional methods for automating recommender system design, such as Neural Architecture Search (NAS), are often constrained by a fixed search space defined by human priors, limiting innovation to pre-defined operators. While recent LLM-driven code evolution frameworks shift fixed search space target to open-ended program spaces, they primarily rely on scalar metrics (e.g., NDCG, Hit Ratio) that fail to provide qualitative insights into model failures or directional guidance for improvement. To address this, we propose Self-EvolveRec, a novel framework that establishes a directional feedback loop by integrating a User Simulator for qualitative critiques and a Model Diagnosis Tool for quantitative internal verification. Furthermore, we introduce a Diagnosis Tool - Model Co-Evolution strategy to ensure that evaluation criteria dynamically adapt as the recommendation architecture evolves. Extensive experiments demonstrate that Self-EvolveRec significantly outperforms state-of-the-art NAS and LLM-driven code evolution baselines in both recommendation performance and user satisfaction. Our code is available at https://github.com/Sein-Kim/self_evolverec.
R1-ACT: Efficient Reasoning Model Safety Alignment by Activating Safety Knowledge
Aug 01, 2025Although large reasoning models (LRMs) have demonstrated impressive capabilities on complex tasks, recent studies reveal that these models frequently fulfill harmful user instructions, raising significant safety concerns. In this paper, we investigate the underlying cause of LRM safety risks and find that models already possess sufficient safety knowledge but fail to activate it during reasoning. Based on this insight, we propose R1-Act, a simple and efficient post-training method that explicitly triggers safety knowledge through a structured reasoning process. R1-Act achieves strong safety improvements while preserving reasoning performance, outperforming prior alignment methods. Notably, it requires only 1,000 training examples and 90 minutes of training on a single RTX A6000 GPU. Extensive experiments across multiple LRM backbones and sizes demonstrate the robustness, scalability, and practical efficiency of our approach.
Disambiguation in Conversational Question Answering in the Era of LLM: A Survey
May 18, 2025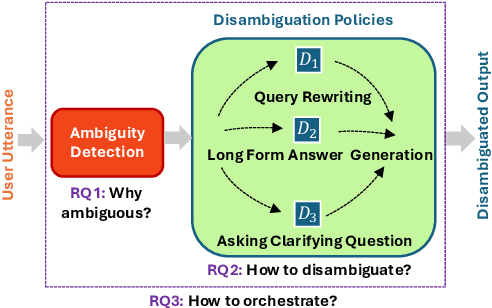
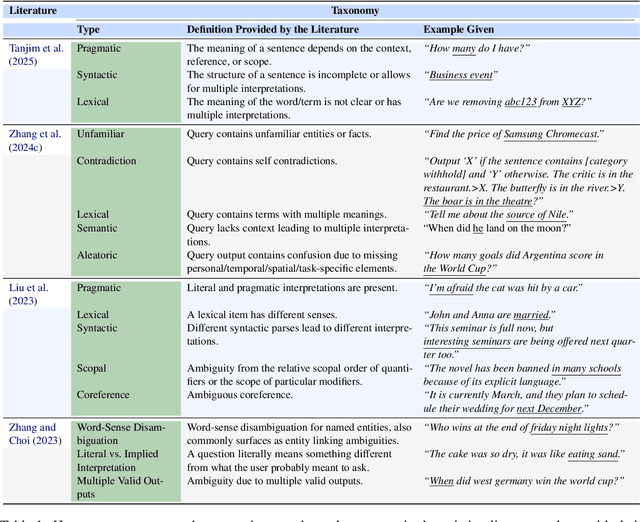
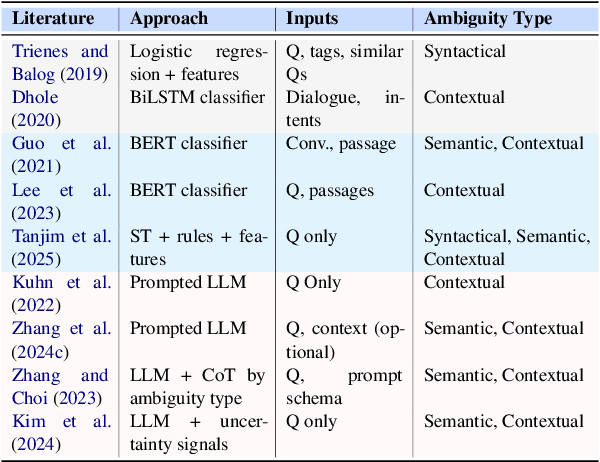
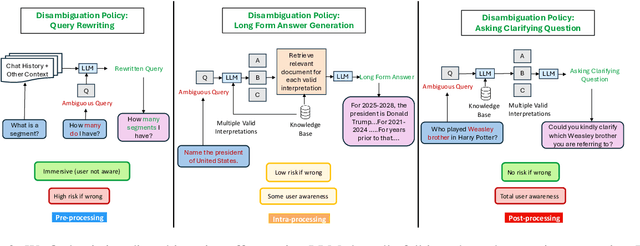
Ambiguity remains a fundamental challenge in Natural Language Processing (NLP) due to the inherent complexity and flexibility of human language. With the advent of Large Language Models (LLMs), addressing ambiguity has become even more critical due to their expanded capabilities and applications. In the context of Conversational Question Answering (CQA), this paper explores the definition, forms, and implications of ambiguity for language driven systems, particularly in the context of LLMs. We define key terms and concepts, categorize various disambiguation approaches enabled by LLMs, and provide a comparative analysis of their advantages and disadvantages. We also explore publicly available datasets for benchmarking ambiguity detection and resolution techniques and highlight their relevance for ongoing research. Finally, we identify open problems and future research directions, proposing areas for further investigation. By offering a comprehensive review of current research on ambiguities and disambiguation with LLMs, we aim to contribute to the development of more robust and reliable language systems.
Image is All You Need: Towards Efficient and Effective Large Language Model-Based Recommender Systems
Mar 08, 2025Large Language Models (LLMs) have recently emerged as a powerful backbone for recommender systems. Existing LLM-based recommender systems take two different approaches for representing items in natural language, i.e., Attribute-based Representation and Description-based Representation. In this work, we aim to address the trade-off between efficiency and effectiveness that these two approaches encounter, when representing items consumed by users. Based on our interesting observation that there is a significant information overlap between images and descriptions associated with items, we propose a novel method, Image is all you need for LLM-based Recommender system (I-LLMRec). Our main idea is to leverage images as an alternative to lengthy textual descriptions for representing items, aiming at reducing token usage while preserving the rich semantic information of item descriptions. Through extensive experiments, we demonstrate that I-LLMRec outperforms existing methods in both efficiency and effectiveness by leveraging images. Moreover, a further appeal of I-LLMRec is its ability to reduce sensitivity to noise in descriptions, leading to more robust recommendations.
Training Robust Graph Neural Networks by Modeling Noise Dependencies
Feb 27, 2025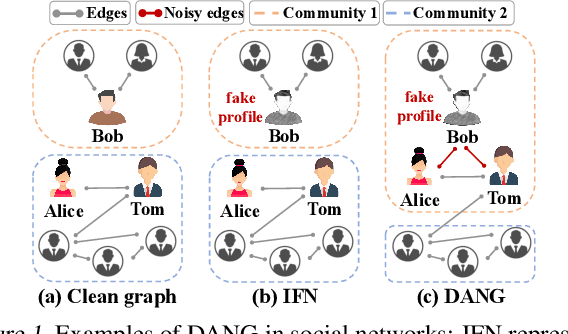
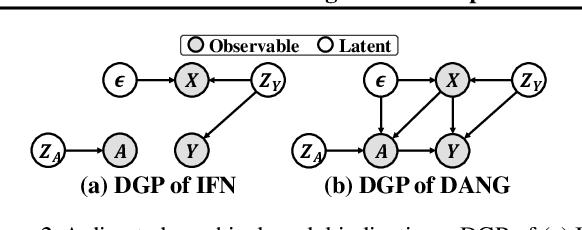
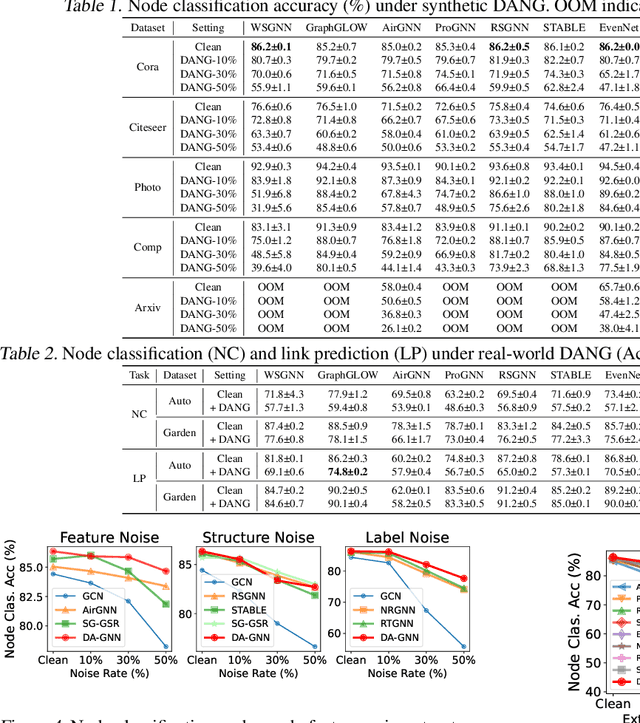
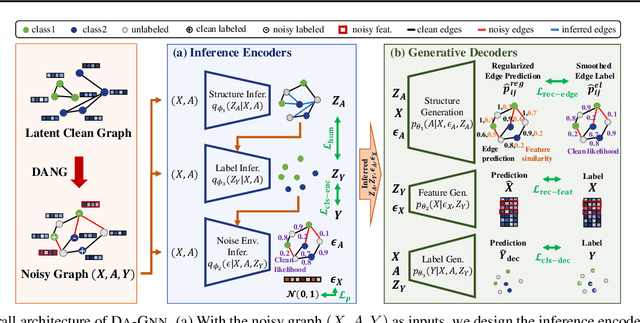
In real-world applications, node features in graphs often contain noise from various sources, leading to significant performance degradation in GNNs. Although several methods have been developed to enhance robustness, they rely on the unrealistic assumption that noise in node features is independent of the graph structure and node labels, thereby limiting their applicability. To this end, we introduce a more realistic noise scenario, dependency-aware noise on graphs (DANG), where noise in node features create a chain of noise dependencies that propagates to the graph structure and node labels. We propose a novel robust GNN, DA-GNN, which captures the causal relationships among variables in the data generating process (DGP) of DANG using variational inference. In addition, we present new benchmark datasets that simulate DANG in real-world applications, enabling more practical research on robust GNNs. Extensive experiments demonstrate that DA-GNN consistently outperforms existing baselines across various noise scenarios, including both DANG and conventional noise models commonly considered in this field.
Weakly Supervised Video Scene Graph Generation via Natural Language Supervision
Feb 21, 2025Existing Video Scene Graph Generation (VidSGG) studies are trained in a fully supervised manner, which requires all frames in a video to be annotated, thereby incurring high annotation cost compared to Image Scene Graph Generation (ImgSGG). Although the annotation cost of VidSGG can be alleviated by adopting a weakly supervised approach commonly used for ImgSGG (WS-ImgSGG) that uses image captions, there are two key reasons that hinder such a naive adoption: 1) Temporality within video captions, i.e., unlike image captions, video captions include temporal markers (e.g., before, while, then, after) that indicate time related details, and 2) Variability in action duration, i.e., unlike human actions in image captions, human actions in video captions unfold over varying duration. To address these issues, we propose a Natural Language-based Video Scene Graph Generation (NL-VSGG) framework that only utilizes the readily available video captions for training a VidSGG model. NL-VSGG consists of two key modules: Temporality-aware Caption Segmentation (TCS) module and Action Duration Variability-aware caption-frame alignment (ADV) module. Specifically, TCS segments the video captions into multiple sentences in a temporal order based on a Large Language Model (LLM), and ADV aligns each segmented sentence with appropriate frames considering the variability in action duration. Our approach leads to a significant enhancement in performance compared to simply applying the WS-ImgSGG pipeline to VidSGG on the Action Genome dataset. As a further benefit of utilizing the video captions as weak supervision, we show that the VidSGG model trained by NL-VSGG is able to predict a broader range of action classes that are not included in the training data, which makes our framework practical in reality.
Is Safety Standard Same for Everyone? User-Specific Safety Evaluation of Large Language Models
Feb 20, 2025As the use of large language model (LLM) agents continues to grow, their safety vulnerabilities have become increasingly evident. Extensive benchmarks evaluate various aspects of LLM safety by defining the safety relying heavily on general standards, overlooking user-specific standards. However, safety standards for LLM may vary based on a user-specific profiles rather than being universally consistent across all users. This raises a critical research question: Do LLM agents act safely when considering user-specific safety standards? Despite its importance for safe LLM use, no benchmark datasets currently exist to evaluate the user-specific safety of LLMs. To address this gap, we introduce U-SAFEBENCH, the first benchmark designed to assess user-specific aspect of LLM safety. Our evaluation of 18 widely used LLMs reveals current LLMs fail to act safely when considering user-specific safety standards, marking a new discovery in this field. To address this vulnerability, we propose a simple remedy based on chain-of-thought, demonstrating its effectiveness in improving user-specific safety. Our benchmark and code are available at https://github.com/yeonjun-in/U-SafeBench.