 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBugSweeper: Function-Level Detection of Smart Contract Vulnerabilities Using Graph Neural Networks
Dec 12, 2025The rapid growth of Ethereum has made it more important to quickly and accurately detect smart contract vulnerabilities. While machine-learning-based methods have shown some promise, many still rely on rule-based preprocessing designed by domain experts. Rule-based preprocessing methods often discard crucial context from the source code, potentially causing certain vulnerabilities to be overlooked and limiting adaptability to newly emerging threats. We introduce BugSweeper, an end-to-end deep learning framework that detects vulnerabilities directly from the source code without manual engineering. BugSweeper represents each Solidity function as a Function-Level Abstract Syntax Graph (FLAG), a novel graph that combines its Abstract Syntax Tree (AST) with enriched control-flow and data-flow semantics. Then, our two-stage Graph Neural Network (GNN) analyzes these graphs. The first-stage GNN filters noise from the syntax graphs, while the second-stage GNN conducts high-level reasoning to detect diverse vulnerabilities. Extensive experiments on real-world contracts show that BugSweeper significantly outperforms all state-of-the-art detection methods. By removing the need for handcrafted rules, our approach offers a robust, automated, and scalable solution for securing smart contracts without any dependence on security experts.
Revisiting Fake News Detection: Towards Temporality-aware Evaluation by Leveraging Engagement Earliness
Nov 19, 2024Social graph-based fake news detection aims to identify news articles containing false information by utilizing social contexts, e.g., user information, tweets and comments. However, conventional methods are evaluated under less realistic scenarios, where the model has access to future knowledge on article-related and context-related data during training. In this work, we newly formalize a more realistic evaluation scheme that mimics real-world scenarios, where the data is temporality-aware and the detection model can only be trained on data collected up to a certain point in time. We show that the discriminative capabilities of conventional methods decrease sharply under this new setting, and further propose DAWN, a method more applicable to such scenarios. Our empirical findings indicate that later engagements (e.g., consuming or reposting news) contribute more to noisy edges that link real news-fake news pairs in the social graph. Motivated by this, we utilize feature representations of engagement earliness to guide an edge weight estimator to suppress the weights of such noisy edges, thereby enhancing the detection performance of DAWN. Through extensive experiments, we demonstrate that DAWN outperforms existing fake news detection methods under real-world environments. The source code is available at https://github.com/LeeJunmo/DAWN.
Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis
Nov 20, 2023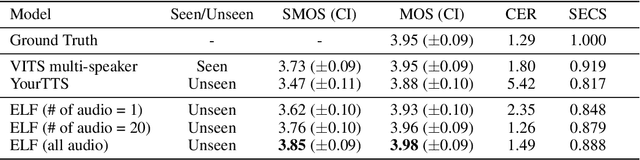
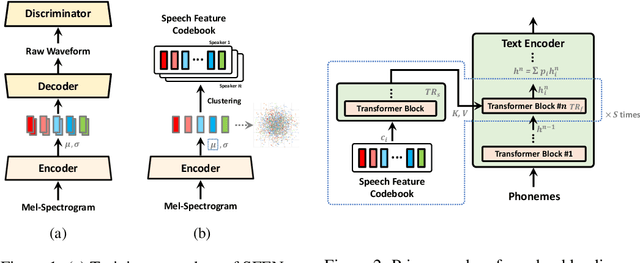
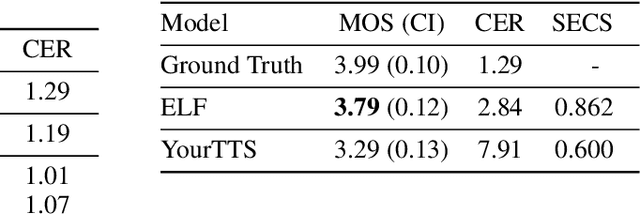
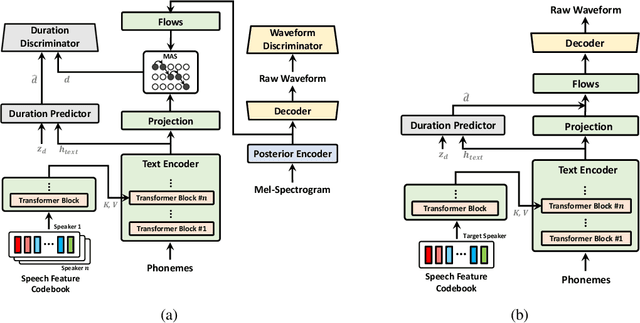
In this work, we propose a novel method for modeling numerous speakers, which enables expressing the overall characteristics of speakers in detail like a trained multi-speaker model without additional training on the target speaker's dataset. Although various works with similar purposes have been actively studied, their performance has not yet reached that of trained multi-speaker models due to their fundamental limitations. To overcome previous limitations, we propose effective methods for feature learning and representing target speakers' speech characteristics by discretizing the features and conditioning them to a speech synthesis model. Our method obtained a significantly higher similarity mean opinion score (SMOS) in subjective similarity evaluation than seen speakers of a best-performing multi-speaker model, even with unseen speakers. The proposed method also outperforms a zero-shot method by significant margins. Furthermore, our method shows remarkable performance in generating new artificial speakers. In addition, we demonstrate that the encoded latent features are sufficiently informative to reconstruct an original speaker's speech completely. It implies that our method can be used as a general methodology to encode and reconstruct speakers' characteristics in various tasks.
Class Label-aware Graph Anomaly Detection
Aug 22, 2023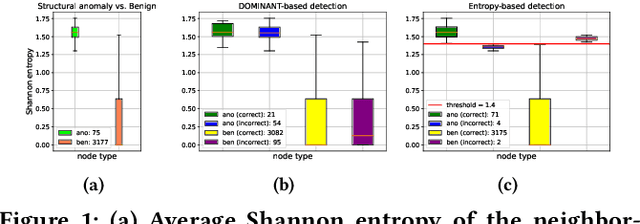
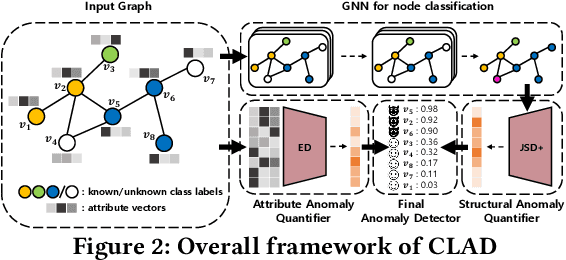

Unsupervised GAD methods assume the lack of anomaly labels, i.e., whether a node is anomalous or not. One common observation we made from previous unsupervised methods is that they not only assume the absence of such anomaly labels, but also the absence of class labels (the class a node belongs to used in a general node classification task). In this work, we study the utility of class labels for unsupervised GAD; in particular, how they enhance the detection of structural anomalies. To this end, we propose a Class Label-aware Graph Anomaly Detection framework (CLAD) that utilizes a limited amount of labeled nodes to enhance the performance of unsupervised GAD. Extensive experiments on ten datasets demonstrate the superior performance of CLAD in comparison to existing unsupervised GAD methods, even in the absence of ground-truth class label information. The source code for CLAD is available at \url{https://github.com/jhkim611/CLAD}.
A Blockchain-based Platform for Reliable Inference and Training of Large-Scale Models
May 06, 2023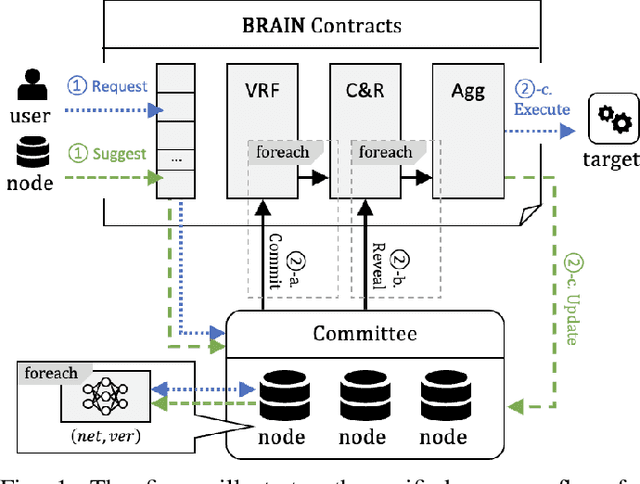


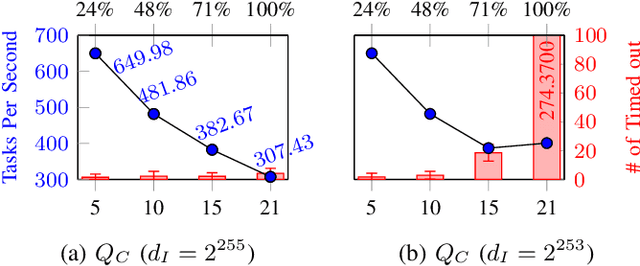
As artificial intelligence (AI) continues to permeate various domains, concerns surrounding trust and transparency in AI-driven inference and training processes have emerged, particularly with respect to potential biases and traceability challenges. Decentralized solutions such as blockchain have been proposed to tackle these issues, but they often struggle when dealing with large-scale models, leading to time-consuming inference and inefficient training verification. To overcome these limitations, we introduce BRAIN, a Blockchain-based Reliable AI Network, a novel platform specifically designed to ensure reliable inference and training of large models. BRAIN harnesses a unique two-phase transaction mechanism, allowing real-time processing via pipelining by separating request and response transactions. Each randomly-selected inference committee commits and reveals the inference results, and upon reaching an agreement through a smart contract, then the requested operation is executed using the consensus result. Additionally, BRAIN carries out training by employing a randomly-selected training committee. They submit commit and reveal transactions along with their respective scores, enabling local model aggregation based on the median value of the scores. Experimental results demonstrate that BRAIN delivers considerably higher inference throughput at reasonable gas fees. In particular, BRAIN's tasks-per-second performance is 454.4293 times greater than that of a naive single-phase implementation.
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Jun 28, 2022
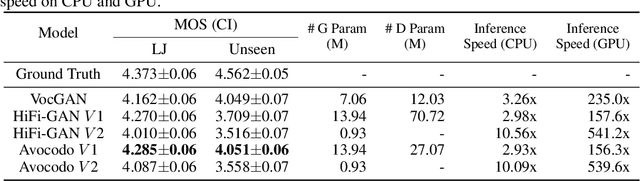
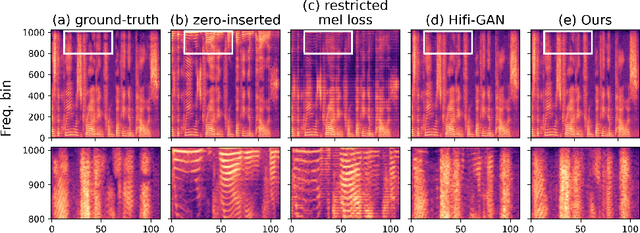
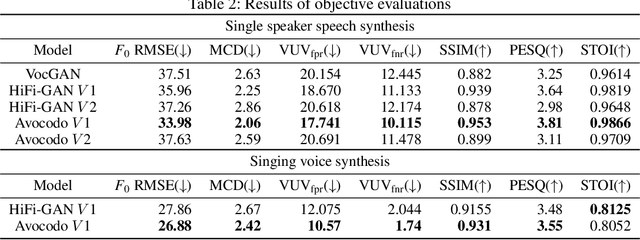
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020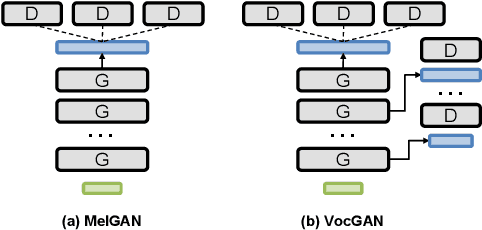
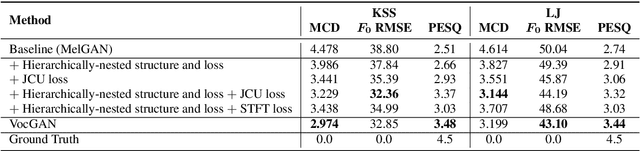
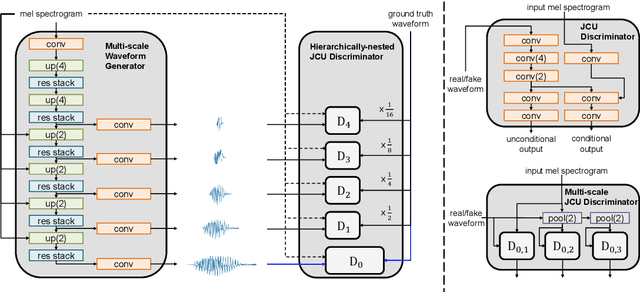
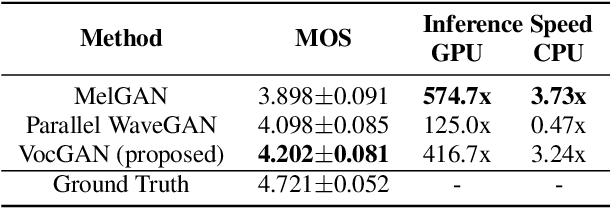
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.