 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Jun 12, 2024This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020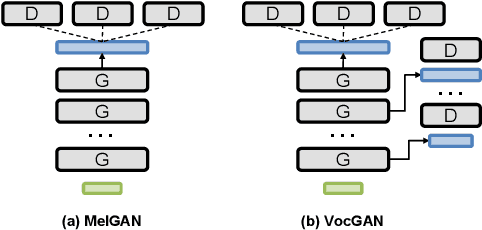
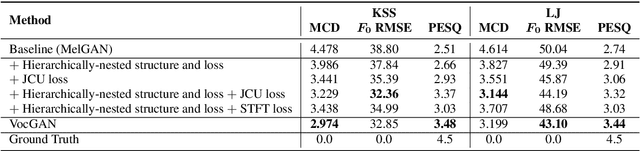
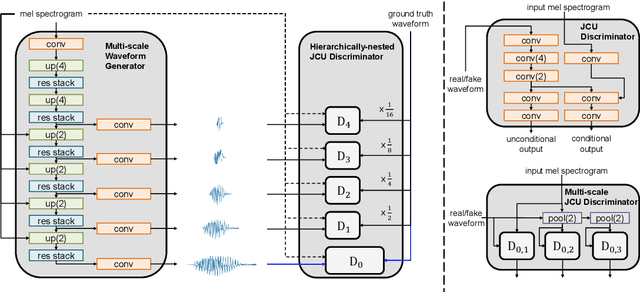
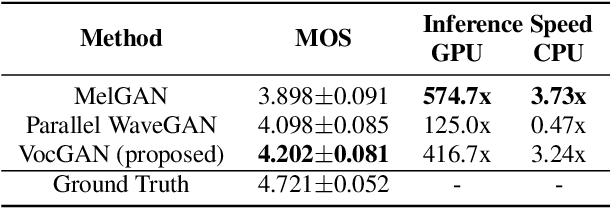
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.