 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Aware Adapter for Few-Shot Keyword Spotting
Dec 24, 2024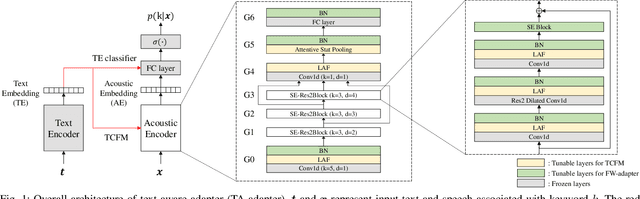
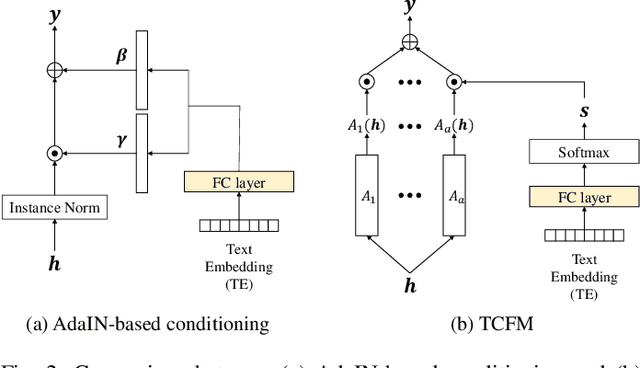
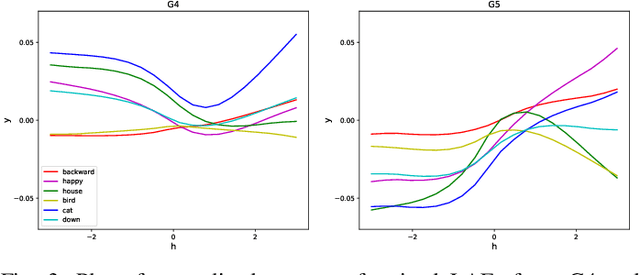
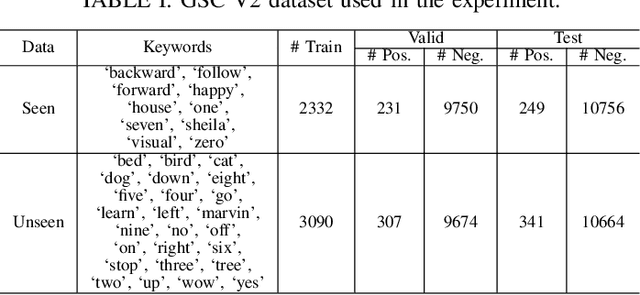
Recent advances in flexible keyword spotting (KWS) with text enrollment allow users to personalize keywords without uttering them during enrollment. However, there is still room for improvement in target keyword performance. In this work, we propose a novel few-shot transfer learning method, called text-aware adapter (TA-adapter), designed to enhance a pre-trained flexible KWS model for specific keywords with limited speech samples. To adapt the acoustic encoder, we leverage a jointly pre-trained text encoder to generate a text embedding that acts as a representative vector for the keyword. By fine-tuning only a small portion of the network while keeping the core components' weights intact, the TA-adapter proves highly efficient for few-shot KWS, enabling a seamless return to the original pre-trained model. In our experiments, the TA-adapter demonstrated significant performance improvements across 35 distinct keywords from the Google Speech Commands V2 dataset, with only a 0.14% increase in the total number of parameters.
CTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Jun 12, 2024This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
Relational Proxy Loss for Audio-Text based Keyword Spotting
Jun 08, 2024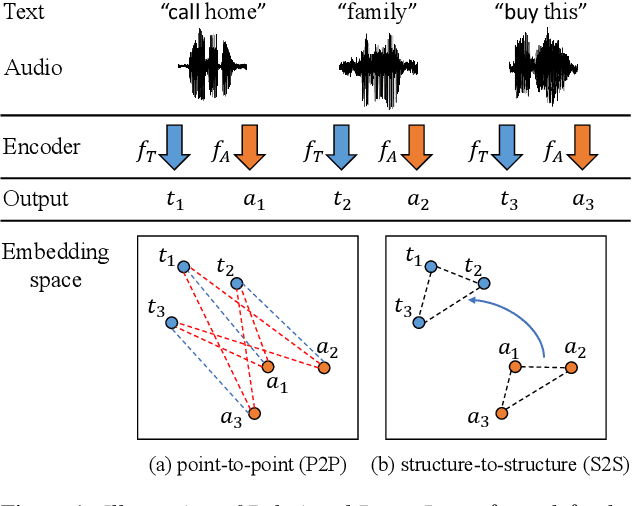
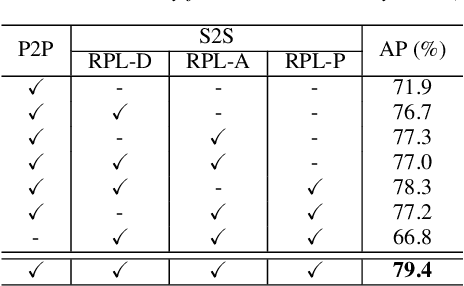
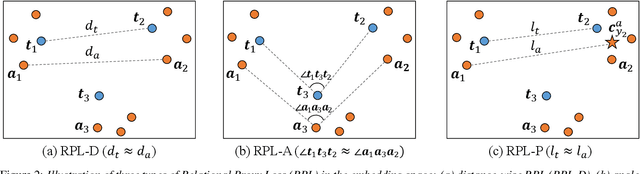

In recent years, there has been an increasing focus on user convenience, leading to increased interest in text-based keyword enrollment systems for keyword spotting (KWS). Since the system utilizes text input during the enrollment phase and audio input during actual usage, we call this task audio-text based KWS. To enable this task, both acoustic and text encoders are typically trained using deep metric learning loss functions, such as triplet- and proxy-based losses. This study aims to improve existing methods by leveraging the structural relations within acoustic embeddings and within text embeddings. Unlike previous studies that only compare acoustic and text embeddings on a point-to-point basis, our approach focuses on the relational structures within the embedding space by introducing the concept of Relational Proxy Loss (RPL). By incorporating RPL, we demonstrated improved performance on the Wall Street Journal (WSJ) corpus.
Identifying Critical LMS Features for Predicting At-risk Students
Apr 27, 2022
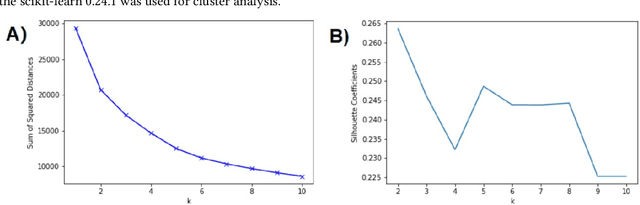

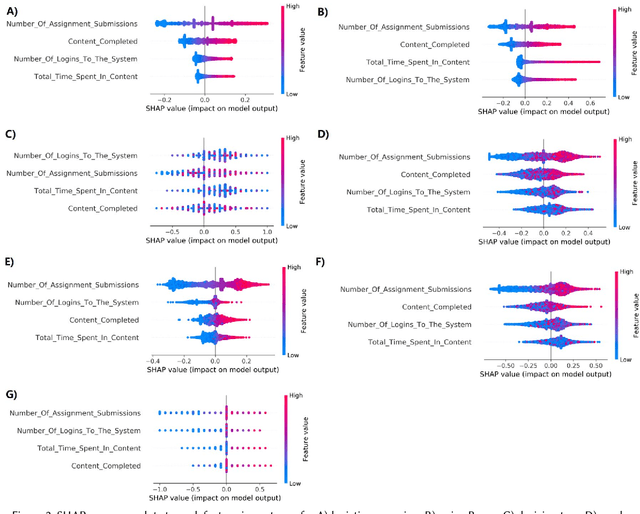
Learning management systems (LMSs) have become essential in higher education and play an important role in helping educational institutions to promote student success. Traditionally, LMSs have been used by postsecondary institutions in administration, reporting, and delivery of educational content. In this paper, we present an additional use of LMS by using its data logs to perform data-analytics and identify academically at-risk students. The data-driven insights would allow educational institutions and educators to develop and implement pedagogical interventions targeting academically at-risk students. We used anonymized data logs created by Brightspace LMS during fall 2019, spring 2020, and fall 2020 semesters at our college. Supervised machine learning algorithms were used to predict the final course performance of students, and several algorithms were found to perform well with accuracy above 90%. SHAP value method was used to assess the relative importance of features used in the predictive models. Unsupervised learning was also used to group students into different clusters based on the similarities in their interaction/involvement with LMS. In both of supervised and unsupervised learning, we identified two most-important features (Number_Of_Assignment_Submissions and Content_Completed). More importantly, our study lays a foundation and provides a framework for developing a real-time data analytics metric that may be incorporated into a LMS.
Sequential Skip Prediction with Few-shot in Streamed Music Contents
Jan 24, 2019
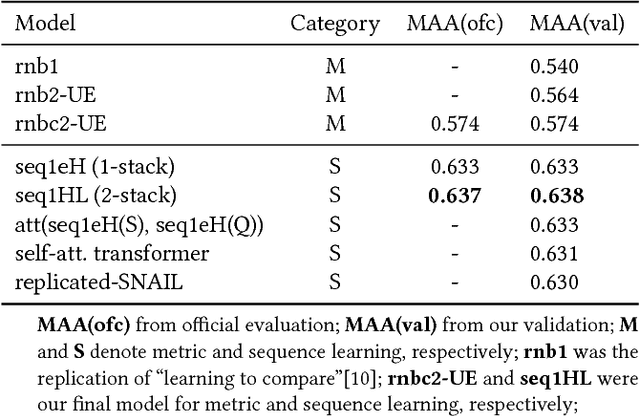
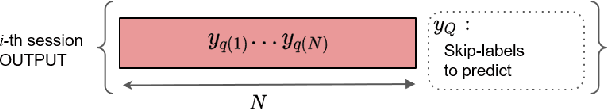

This paper provides an outline of the algorithms submitted for the WSDM Cup 2019 Spotify Sequential Skip Prediction Challenge (team name: mimbres). In the challenge, complete information including acoustic features and user interaction logs for the first half of a listening session is provided. Our goal is to predict whether the individual tracks in the second half of the session will be skipped or not, only given acoustic features. We proposed two different kinds of algorithms that were based on metric learning and sequence learning. The experimental results showed that the sequence learning approach performed significantly better than the metric learning approach. Moreover, we conducted additional experiments to find that significant performance gain can be achieved using complete user log information.