 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
Jan 20, 2026Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.
Adversarial Deep Metric Learning for Cross-Modal Audio-Text Alignment in Open-Vocabulary Keyword Spotting
May 22, 2025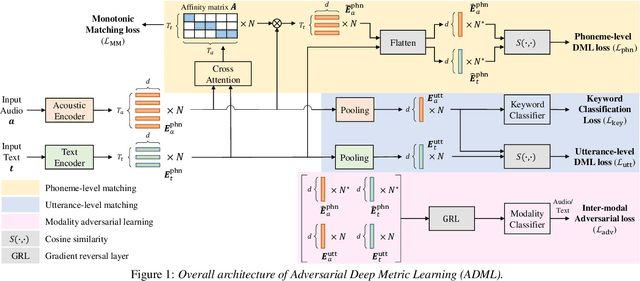



For text enrollment-based open-vocabulary keyword spotting (KWS), acoustic and text embeddings are typically compared at either the phoneme or utterance level. To facilitate this, we optimize acoustic and text encoders using deep metric learning (DML), enabling direct comparison of multi-modal embeddings in a shared embedding space. However, the inherent heterogeneity between audio and text modalities presents a significant challenge. To address this, we propose Modality Adversarial Learning (MAL), which reduces the domain gap in heterogeneous modality representations. Specifically, we train a modality classifier adversarially to encourage both encoders to generate modality-invariant embeddings. Additionally, we apply DML to achieve phoneme-level alignment between audio and text, and conduct comprehensive comparisons across various DML objectives. Experiments on the Wall Street Journal (WSJ) and LibriPhrase datasets demonstrate the effectiveness of the proposed approach.
Text-Aware Adapter for Few-Shot Keyword Spotting
Dec 24, 2024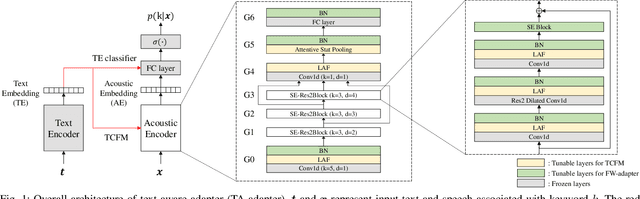
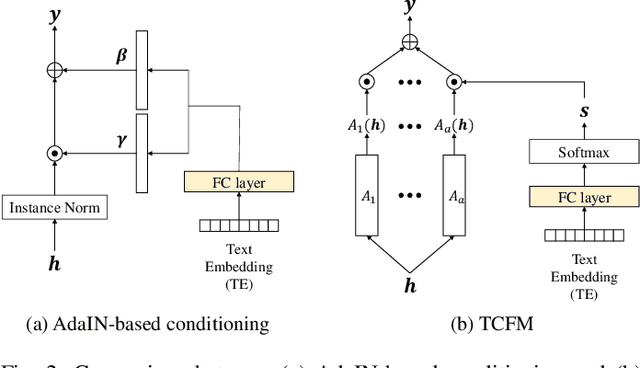
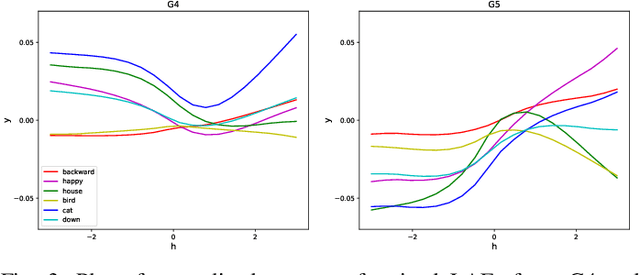
Recent advances in flexible keyword spotting (KWS) with text enrollment allow users to personalize keywords without uttering them during enrollment. However, there is still room for improvement in target keyword performance. In this work, we propose a novel few-shot transfer learning method, called text-aware adapter (TA-adapter), designed to enhance a pre-trained flexible KWS model for specific keywords with limited speech samples. To adapt the acoustic encoder, we leverage a jointly pre-trained text encoder to generate a text embedding that acts as a representative vector for the keyword. By fine-tuning only a small portion of the network while keeping the core components' weights intact, the TA-adapter proves highly efficient for few-shot KWS, enabling a seamless return to the original pre-trained model. In our experiments, the TA-adapter demonstrated significant performance improvements across 35 distinct keywords from the Google Speech Commands V2 dataset, with only a 0.14% increase in the total number of parameters.
Deep Metric Learning with Adaptive Margin and Adaptive Scale for Acoustic Word Discrimination
Oct 26, 2022



Many recent loss functions in deep metric learning are expressed with logarithmic and exponential forms, and they involve margin and scale as essential hyper-parameters. Since each data class has an intrinsic characteristic, several previous works have tried to learn embedding space close to the real distribution by introducing adaptive margins. However, there was no work on adaptive scales at all. We argue that both margin and scale should be adaptively adjustable during the training. In this paper, we propose a method called Adaptive Margin and Scale (AdaMS), where hyper-parameters of margin and scale are replaced with learnable parameters of adaptive margins and adaptive scales for each class. Our method is evaluated on Wall Street Journal dataset, and we achieve outperforming results for word discrimination tasks.
Asymmetric Proxy Loss for Multi-View Acoustic Word Embeddings
Mar 30, 2022



Acoustic word embeddings (AWEs) are discriminative representations of speech segments, and learned embedding space reflects the phonetic similarity between words. With multi-view learning, where text labels are considered as supplementary input, AWEs are jointly trained with acoustically grounded word embeddings (AGWEs). In this paper, we expand the multi-view approach into a proxy-based framework for deep metric learning by equating AGWEs with proxies. A simple modification in computing the similarity matrix allows the general pair weighting to formulate the data-to-proxy relationship. Under the systematized framework, we propose an asymmetric-proxy loss that combines different parts of loss functions asymmetrically while keeping their merits. It follows the assumptions that the optimal function for anchor-positive pairs may differ from one for anchor-negative pairs, and a proxy may have a different impact when it substitutes for different positions in the triplet. We present comparative experiments with various proxy-based losses including our asymmetric-proxy loss, and evaluate AWEs and AGWEs for word discrimination tasks on WSJ corpus. The results demonstrate the effectiveness of the proposed method.
Multi-Task Network for Noise-Robust Keyword Spotting and Speaker Verification using CTC-based Soft VAD and Global Query Attention
May 16, 2020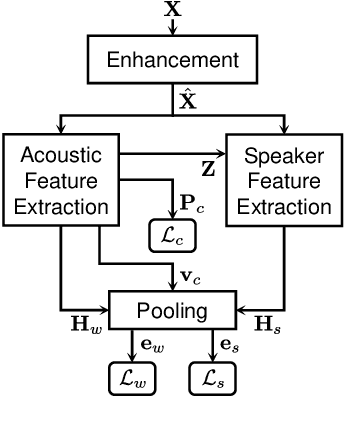
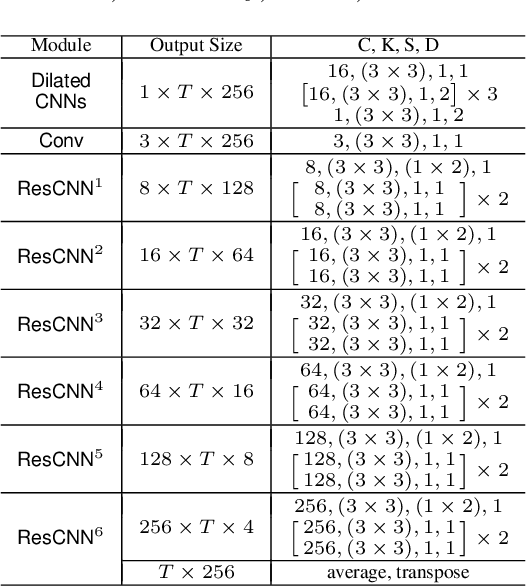
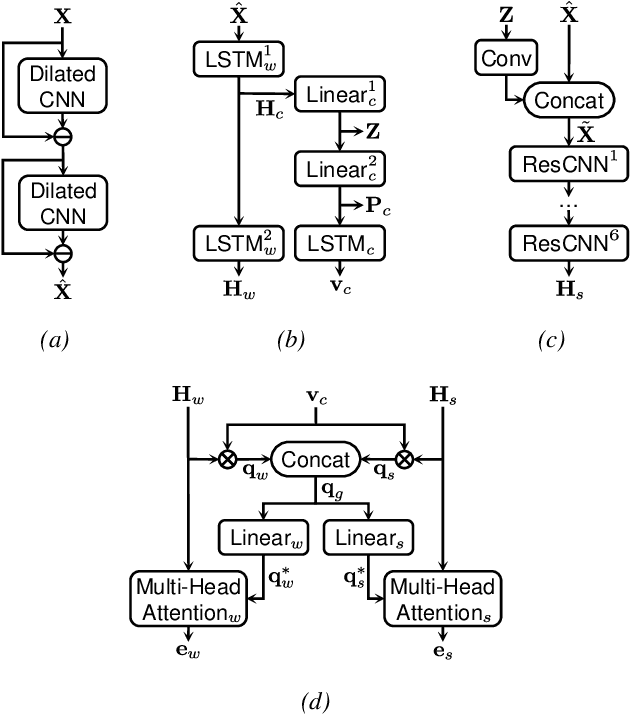
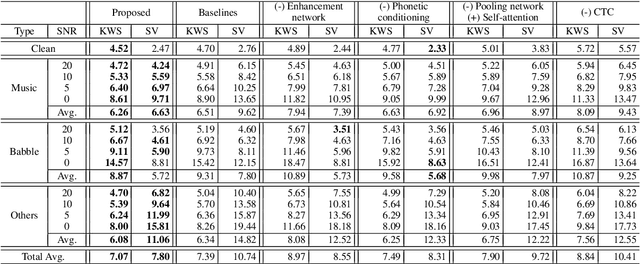
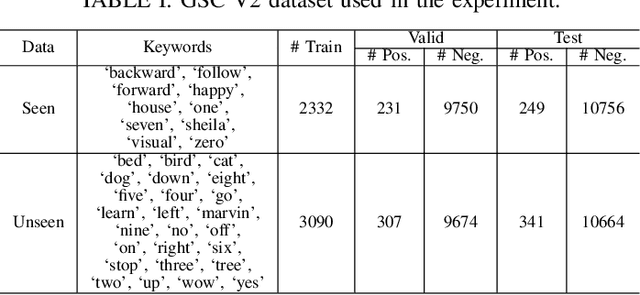
Keyword spotting (KWS) and speaker verification (SV) have been studied independently although it is known that acoustic and speaker domains are complementary. In this paper, we propose a multi-task network that performs KWS and SV simultaneously to fully utilize the interrelated domain information. The multi-task network tightly combines sub-networks aiming at performance improvement in challenging conditions such as noisy environments, open-vocabulary KWS, and short-duration SV, by introducing novel techniques of connectionist temporal classification (CTC)-based soft voice activity detection (VAD) and global query attention. Frame-level acoustic and speaker information is integrated with phonetically originated weights so that forms a word-level global representation. Then it is used for the aggregation of feature vectors to generate discriminative embeddings. Our proposed approach shows 4.06% and 26.71% relative improvements in equal error rate (EER) compared to the baselines for both tasks. We also present a visualization example and results of ablation experiments.
Multi-Scale Aggregation Using Feature Pyramid Module for Text-Independent Speaker Verification
Apr 14, 2020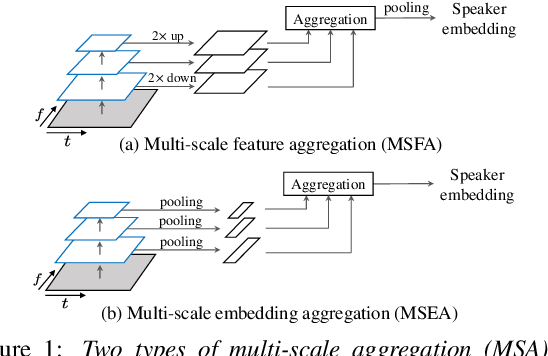
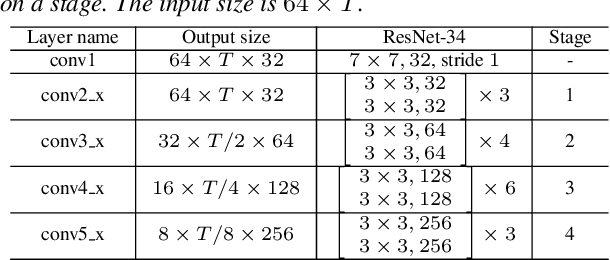
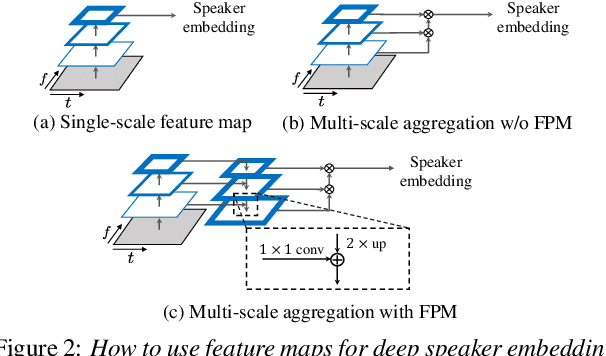
Currently, the most widely used approach for speaker verification is the deep speaker embedding learning. In this approach, convolutional neural networks are mainly used as a frame-level feature extractor, and speaker embeddings are extracted from the last layer of the feature extractor. Multi-scale aggregation (MSA), which utilizes multi-scale features from different layers of the feature extractor, has recently been introduced into the approach and has shown improved performance for both short and long utterances. This paper improves the MSA by using a feature pyramid module, which enhances speaker-discriminative information of features at multiple layers via a top-down pathway and lateral connections. We extract speaker embeddings using the enhanced features that contain rich speaker information at different resolutions. Experiments on the VoxCeleb dataset show that the proposed module improves previous MSA methods with a smaller number of parameters, providing better performance than state-of-the-art approaches.
Additional Shared Decoder on Siamese Multi-view Encoders for Learning Acoustic Word Embeddings
Oct 01, 2019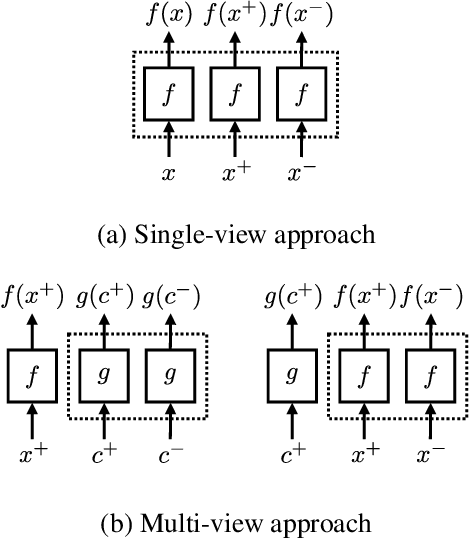
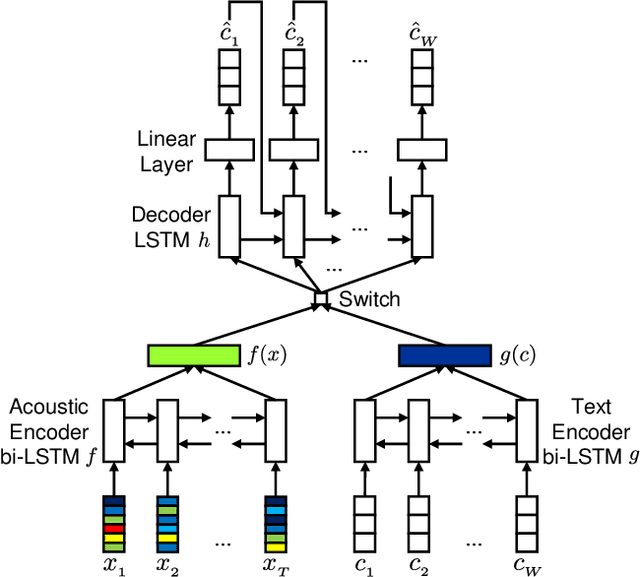
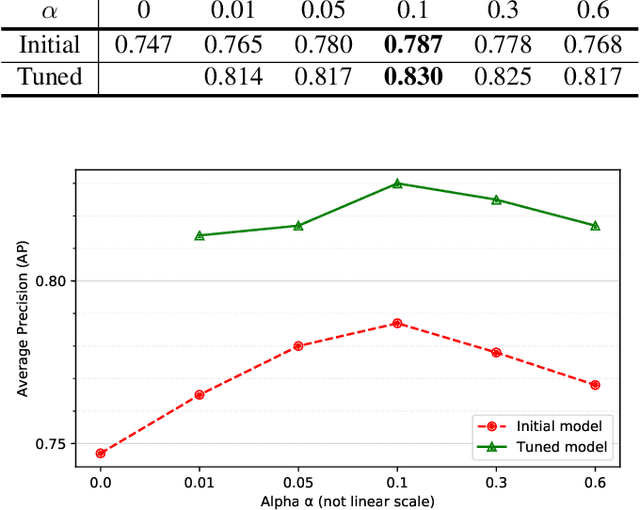
Acoustic word embeddings --- fixed-dimensional vector representations of arbitrary-length words --- have attracted increasing interest in query-by-example spoken term detection. Recently, on the fact that the orthography of text labels partly reflects the phonetic similarity between the words' pronunciation, a multi-view approach has been introduced that jointly learns acoustic and text embeddings. It showed that it is possible to learn discriminative embeddings by designing the objective which takes text labels as well as word segments. In this paper, we propose a network architecture that expands the multi-view approach by combining the Siamese multi-view encoders with a shared decoder network to maximize the effect of the relationship between acoustic and text embeddings in embedding space. Discriminatively trained with multi-view triplet loss and decoding loss, our proposed approach achieves better performance on acoustic word discrimination task with the WSJ dataset, resulting in 11.1% relative improvement in average precision. We also present experimental results on cross-view word discrimination and word level speech recognition tasks.
Learning acoustic word embeddings with phonetically associated triplet network
Nov 28, 2018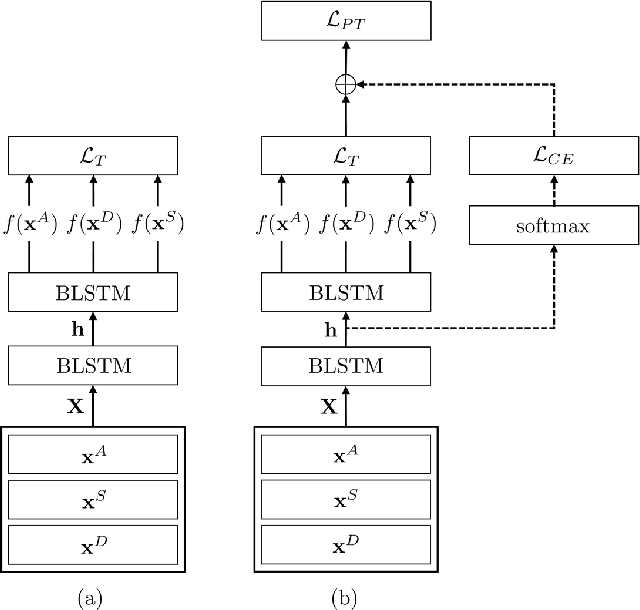

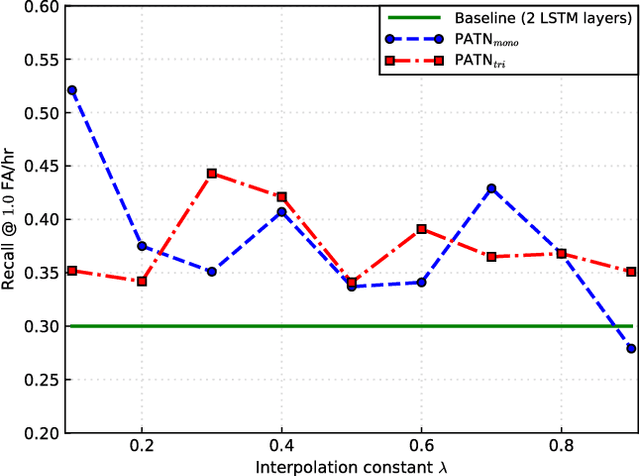

Previous researches on acoustic word embeddings used in query-by-example spoken term detection have shown remarkable performance improvements when using a triplet network. However, the triplet network is trained using only a limited information about acoustic similarity between words. In this paper, we propose a novel architecture, phonetically associated triplet network (PATN), which aims at increasing discriminative power of acoustic word embeddings by utilizing phonetic information as well as word identity. The proposed model is learned to minimize a combined loss function that was made by introducing a cross entropy loss to the lower layer of LSTM-based triplet network. We observed that the proposed method performs significantly better than the baseline triplet network on a word discrimination task with the WSJ dataset resulting in over 20% relative improvement in recall rate at 1.0 false alarm per hour. Finally, we examined the generalization ability by conducting the out-of-domain test on the RM dataset.