 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Aggregation Using Feature Pyramid Module for Text-Independent Speaker Verification
Paper and Code
Apr 14, 2020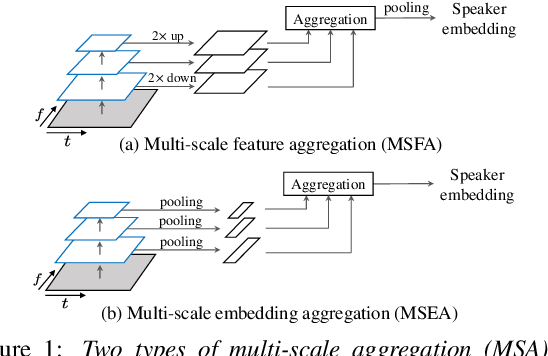
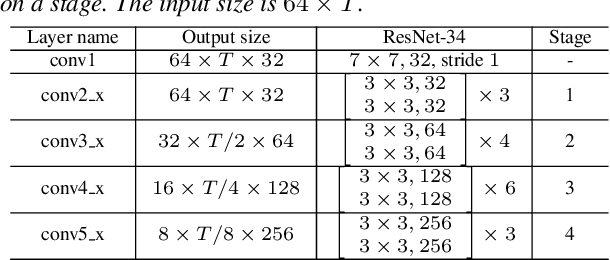
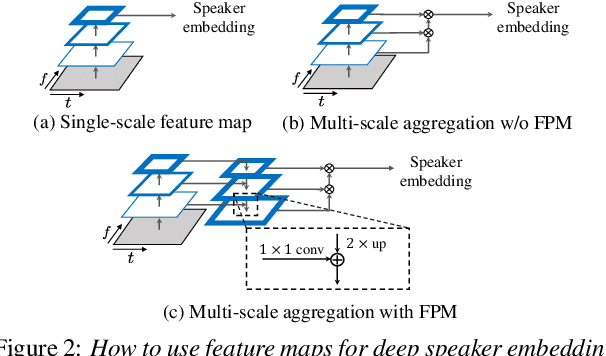
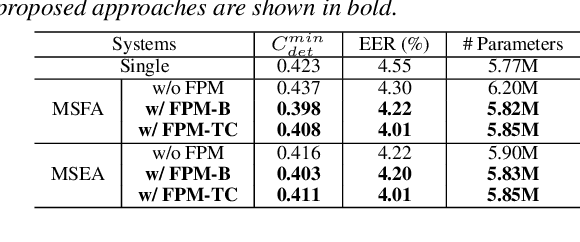
Currently, the most widely used approach for speaker verification is the deep speaker embedding learning. In this approach, convolutional neural networks are mainly used as a frame-level feature extractor, and speaker embeddings are extracted from the last layer of the feature extractor. Multi-scale aggregation (MSA), which utilizes multi-scale features from different layers of the feature extractor, has recently been introduced into the approach and has shown improved performance for both short and long utterances. This paper improves the MSA by using a feature pyramid module, which enhances speaker-discriminative information of features at multiple layers via a top-down pathway and lateral connections. We extract speaker embeddings using the enhanced features that contain rich speaker information at different resolutions. Experiments on the VoxCeleb dataset show that the proposed module improves previous MSA methods with a smaller number of parameters, providing better performance than state-of-the-art approaches.