 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiDAL: Learning Training Dynamics for Active Learning
Oct 13, 2022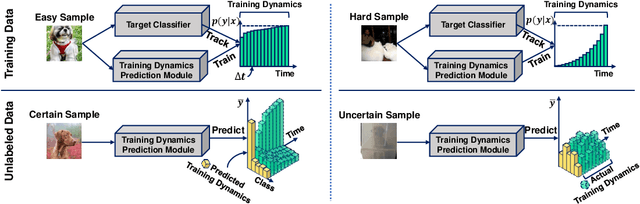


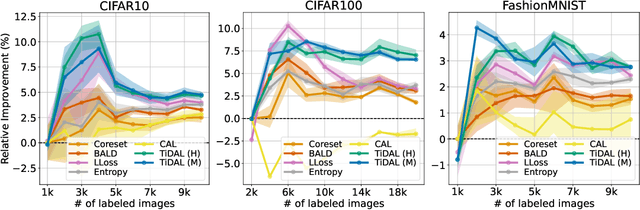
Active learning (AL) aims to select the most useful data samples from an unlabeled data pool and annotate them to expand the labeled dataset under a limited budget. Especially, uncertainty-based methods choose the most uncertain samples, which are known to be effective in improving model performance. However, AL literature often overlooks training dynamics (TD), defined as the ever-changing model behavior during optimization via stochastic gradient descent, even though other areas of literature have empirically shown that TD provides important clues for measuring the sample uncertainty. In this paper, we propose a novel AL method, Training Dynamics for Active Learning (TiDAL), which leverages the TD to quantify uncertainties of unlabeled data. Since tracking the TD of all the large-scale unlabeled data is impractical, TiDAL utilizes an additional prediction module that learns the TD of labeled data. To further justify the design of TiDAL, we provide theoretical and empirical evidence to argue the usefulness of leveraging TD for AL. Experimental results show that our TiDAL achieves better or comparable performance on both balanced and imbalanced benchmark datasets compared to state-of-the-art AL methods, which estimate data uncertainty using only static information after model training.
Learning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection
Nov 29, 2021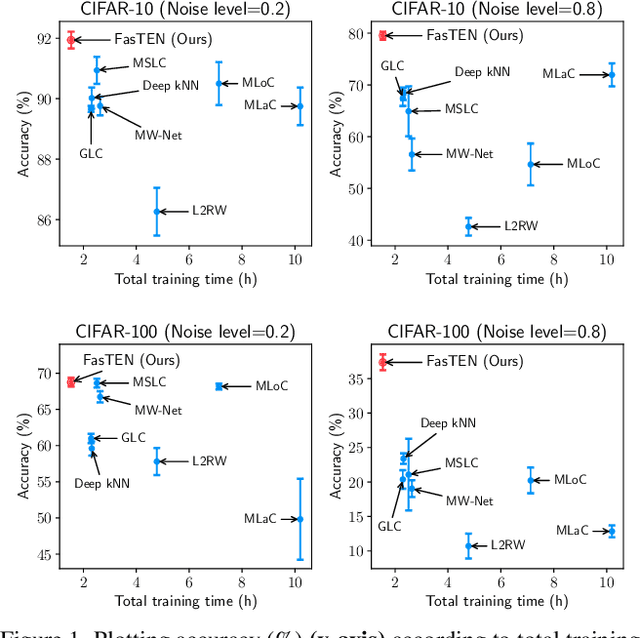
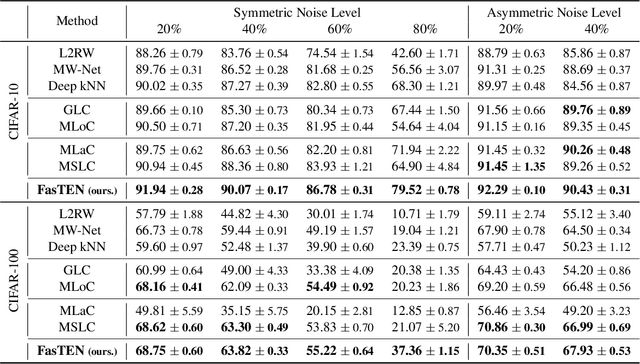
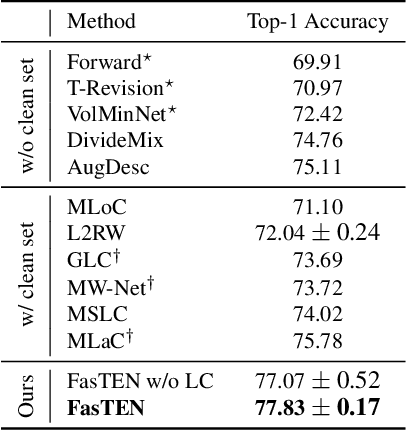
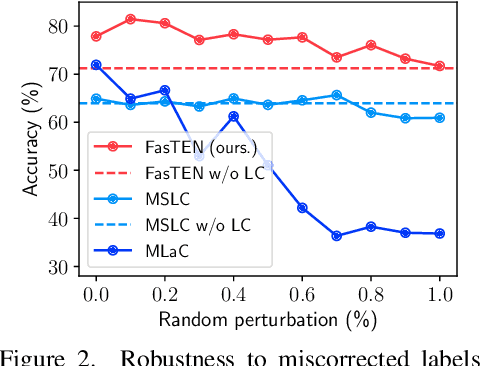
Recent studies on learning with noisy labels have shown remarkable performance by exploiting a small clean dataset. In particular, model agnostic meta-learning-based label correction methods further improve performance by correcting noisy labels on the fly. However, there is no safeguard on the label miscorrection, resulting in unavoidable performance degradation. Moreover, every training step requires at least three back-propagations, significantly slowing down the training speed. To mitigate these issues, we propose a robust and efficient method that learns a label transition matrix on the fly. Employing the transition matrix makes the classifier skeptical about all the corrected samples, which alleviates the miscorrection issue. We also introduce a two-head architecture to efficiently estimate the label transition matrix every iteration within a single back-propagation, so that the estimated matrix closely follows the shifting noise distribution induced by label correction. Extensive experiments demonstrate that our approach shows the best performance in training efficiency while having comparable or better accuracy than existing methods.
Multi-Scale Aggregation Using Feature Pyramid Module for Text-Independent Speaker Verification
Apr 14, 2020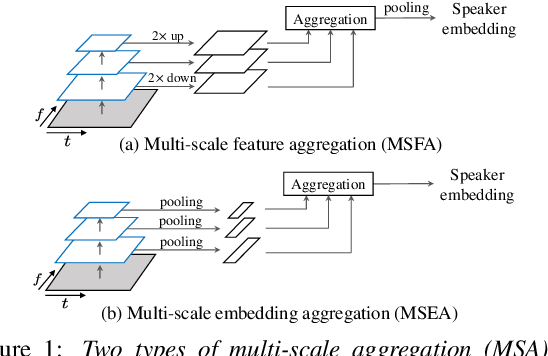
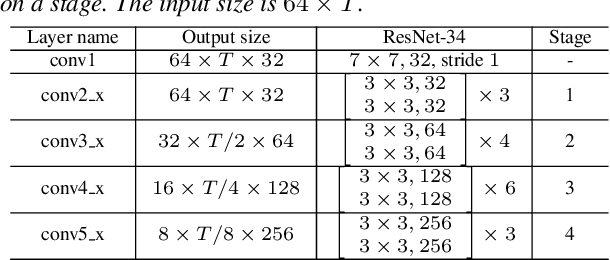
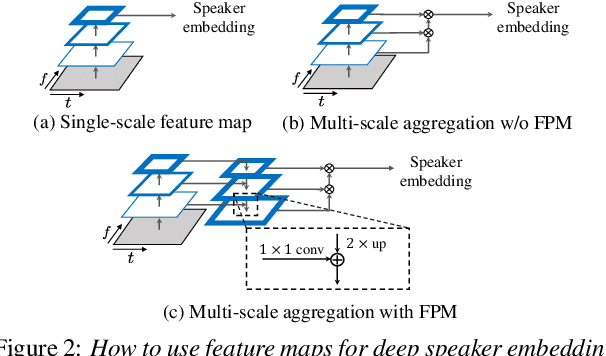
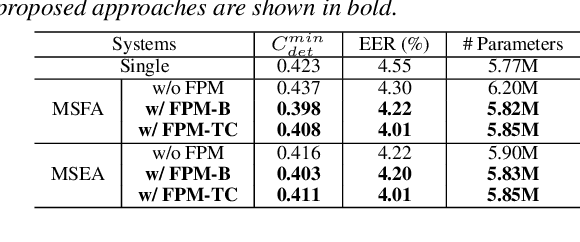
Currently, the most widely used approach for speaker verification is the deep speaker embedding learning. In this approach, convolutional neural networks are mainly used as a frame-level feature extractor, and speaker embeddings are extracted from the last layer of the feature extractor. Multi-scale aggregation (MSA), which utilizes multi-scale features from different layers of the feature extractor, has recently been introduced into the approach and has shown improved performance for both short and long utterances. This paper improves the MSA by using a feature pyramid module, which enhances speaker-discriminative information of features at multiple layers via a top-down pathway and lateral connections. We extract speaker embeddings using the enhanced features that contain rich speaker information at different resolutions. Experiments on the VoxCeleb dataset show that the proposed module improves previous MSA methods with a smaller number of parameters, providing better performance than state-of-the-art approaches.
Meta-Learning for Short Utterance Speaker Recognition with Imbalance Length Pairs
Apr 06, 2020



In realistic settings, a speaker recognition system needs to identify a speaker given a short utterance, while the utterance used to enroll may be relatively long. However, existing speaker recognition models perform poorly with such short utterances. To solve this problem, we introduce a meta-learning scheme with imbalance length pairs. Specifically, we use a prototypical network and train it with a support set of long utterances and a query set of short utterances. However, since optimizing for only the classes in the given episode is not sufficient to learn discriminative embeddings for other classes in the entire dataset, we additionally classify both support set and query set against the entire classes in the training set to learn a well-discriminated embedding space. By combining these two learning schemes, our model outperforms existing state-of-the-art speaker verification models learned in a standard supervised learning framework on short utterance (1-2 seconds) on VoxCeleb dataset. We also validate our proposed model for unseen speaker identification, on which it also achieves significant gain over existing approaches.
Transductive Few-shot Learning with Meta-Learned Confidence
Feb 27, 2020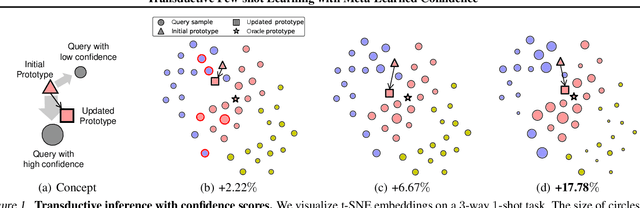

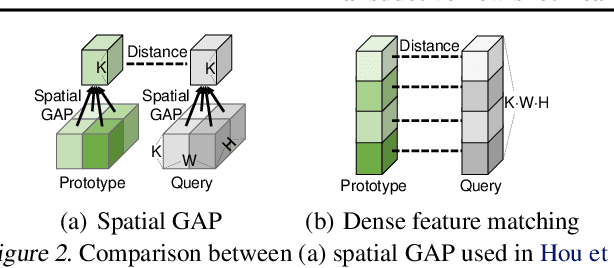

We propose a novel transductive inference framework for metric-based meta-learning models, which updates the prototype of each class with the confidence-weighted average of all the support and query samples. However, a caveat here is that the model confidence may be unreliable, which could lead to incorrect prediction in the transductive setting. To tackle this issue, we further propose to meta-learn to assign correct confidence scores to unlabeled queries. Specifically, we meta-learn the parameters of the distance-metric, such that the model can improve its transductive inference performance on unseen tasks with the generated confidence scores. We also consider various types of uncertainties to further enhance the reliability of the meta-learned confidence. We combine our transductive meta-learning scheme, Meta-Confidence Transduction (MCT) with a novel dense classifier, Dense Feature Matching Network (DFMN), which performs both instance-level and feature-level classification without global average pooling and validate it on four benchmark datasets. Our model achieves state-of-the-art results on all datasets, outperforming existing state-of-the-art models by 11.11% and 7.68% on miniImageNet and tieredImageNet dataset respectively. Further qualitative analysis confirms that this impressive performance gain is indeed due to its ability to assign high confidence to instances with the correct labels.