 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFlowPO: Generative Flow Network as a Language Model Prompt Optimizer
Feb 03, 2026Finding effective prompts for language models (LMs) is critical yet notoriously difficult: the prompt space is combinatorially large, rewards are sparse due to expensive target-LM evaluation. Yet, existing RL-based prompt optimizers often rely on on-policy updates and a meta-prompt sampled from a fixed distribution, leading to poor sample efficiency. We propose GFlowPO, a probabilistic prompt optimization framework that casts prompt search as a posterior inference problem over latent prompts regularized by a meta-prompted reference-LM prior. In the first step, we fine-tune a lightweight prompt-LM with an off-policy Generative Flow Network (GFlowNet) objective, using a replay-based training policy that reuses past prompt evaluations to enable sample-efficient exploration. In the second step, we introduce Dynamic Memory Update (DMU), a training-free mechanism that updates the meta-prompt by injecting both (i) diverse prompts from a replay buffer and (ii) top-performing prompts from a small priority queue, thereby progressively concentrating the search process on high-reward regions. Across few-shot text classification, instruction induction benchmarks, and question answering tasks, GFlowPO consistently outperforms recent discrete prompt optimization baselines.
Bayesian Neural Scaling Laws Extrapolation with Prior-Fitted Networks
May 29, 2025



Scaling has been a major driver of recent advancements in deep learning. Numerous empirical studies have found that scaling laws often follow the power-law and proposed several variants of power-law functions to predict the scaling behavior at larger scales. However, existing methods mostly rely on point estimation and do not quantify uncertainty, which is crucial for real-world applications involving decision-making problems such as determining the expected performance improvements achievable by investing additional computational resources. In this work, we explore a Bayesian framework based on Prior-data Fitted Networks (PFNs) for neural scaling law extrapolation. Specifically, we design a prior distribution that enables the sampling of infinitely many synthetic functions resembling real-world neural scaling laws, allowing our PFN to meta-learn the extrapolation. We validate the effectiveness of our approach on real-world neural scaling laws, comparing it against both the existing point estimation methods and Bayesian approaches. Our method demonstrates superior performance, particularly in data-limited scenarios such as Bayesian active learning, underscoring its potential for reliable, uncertainty-aware extrapolation in practical applications.
Cost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
May 28, 2024In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
Delta-AI: Local objectives for amortized inference in sparse graphical models
Oct 03, 2023



We present a new algorithm for amortized inference in sparse probabilistic graphical models (PGMs), which we call $\Delta$-amortized inference ($\Delta$-AI). Our approach is based on the observation that when the sampling of variables in a PGM is seen as a sequence of actions taken by an agent, sparsity of the PGM enables local credit assignment in the agent's policy learning objective. This yields a local constraint that can be turned into a local loss in the style of generative flow networks (GFlowNets) that enables off-policy training but avoids the need to instantiate all the random variables for each parameter update, thus speeding up training considerably. The $\Delta$-AI objective matches the conditional distribution of a variable given its Markov blanket in a tractable learned sampler, which has the structure of a Bayesian network, with the same conditional distribution under the target PGM. As such, the trained sampler recovers marginals and conditional distributions of interest and enables inference of partial subsets of variables. We illustrate $\Delta$-AI's effectiveness for sampling from synthetic PGMs and training latent variable models with sparse factor structure.
Dataset Condensation with Latent Space Knowledge Factorization and Sharing
Aug 21, 2022
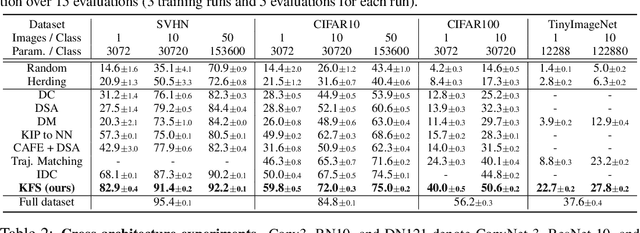
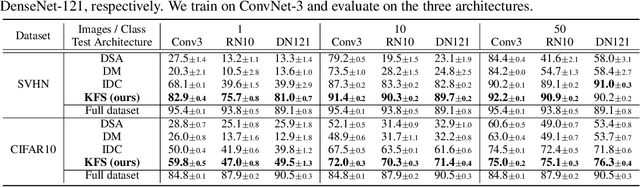
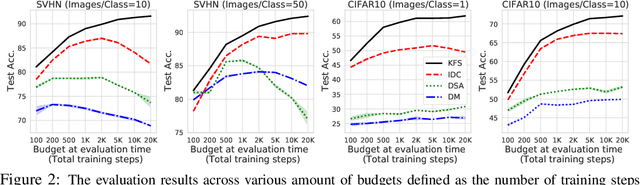
In this paper, we introduce a novel approach for systematically solving dataset condensation problem in an efficient manner by exploiting the regularity in a given dataset. Instead of condensing the dataset directly in the original input space, we assume a generative process of the dataset with a set of learnable codes defined in a compact latent space followed by a set of tiny decoders which maps them differently to the original input space. By combining different codes and decoders interchangeably, we can dramatically increase the number of synthetic examples with essentially the same parameter count, because the latent space is much lower dimensional and since we can assume as many decoders as necessary to capture different styles represented in the dataset with negligible cost. Such knowledge factorization allows efficient sharing of information between synthetic examples in a systematic way, providing far better trade-off between compression ratio and quality of the generated examples. We experimentally show that our method achieves new state-of-the-art records by significant margins on various benchmark datasets such as SVHN, CIFAR10, CIFAR100, and TinyImageNet.
Meta Mirror Descent: Optimiser Learning for Fast Convergence
Mar 05, 2022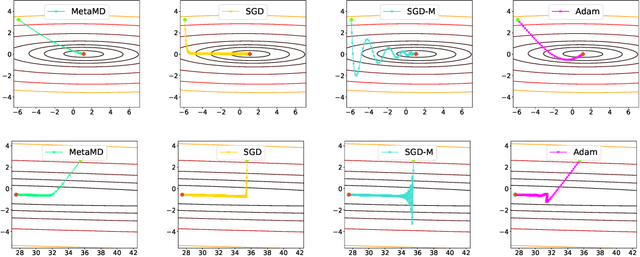
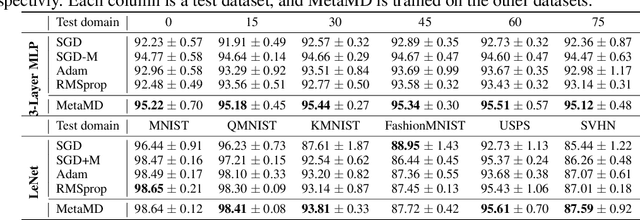
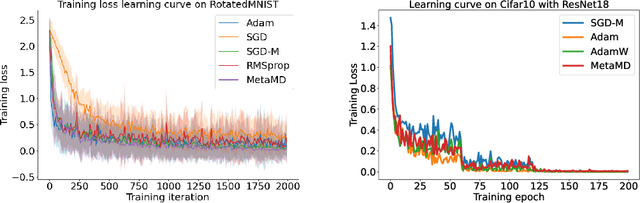
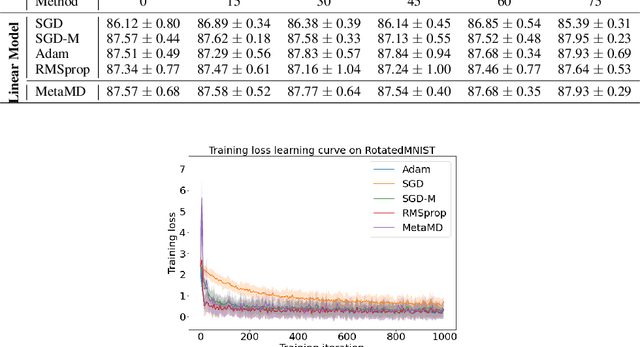
Optimisers are an essential component for training machine learning models, and their design influences learning speed and generalisation. Several studies have attempted to learn more effective gradient-descent optimisers via solving a bi-level optimisation problem where generalisation error is minimised with respect to optimiser parameters. However, most existing optimiser learning methods are intuitively motivated, without clear theoretical support. We take a different perspective starting from mirror descent rather than gradient descent, and meta-learning the corresponding Bregman divergence. Within this paradigm, we formalise a novel meta-learning objective of minimising the regret bound of learning. The resulting framework, termed Meta Mirror Descent (MetaMD), learns to accelerate optimisation speed. Unlike many meta-learned optimisers, it also supports convergence and generalisation guarantees and uniquely does so without requiring validation data. We evaluate our framework on a variety of tasks and architectures in terms of convergence rate and generalisation error and demonstrate strong performance.
Meta Learning Low Rank Covariance Factors for Energy-Based Deterministic Uncertainty
Oct 15, 2021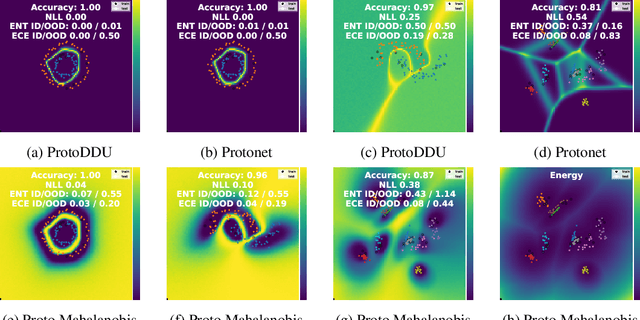
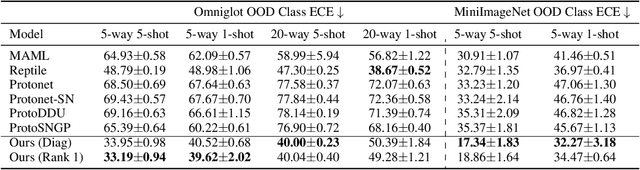
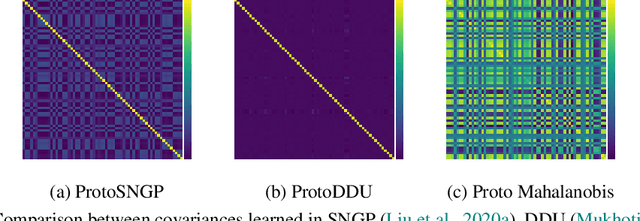
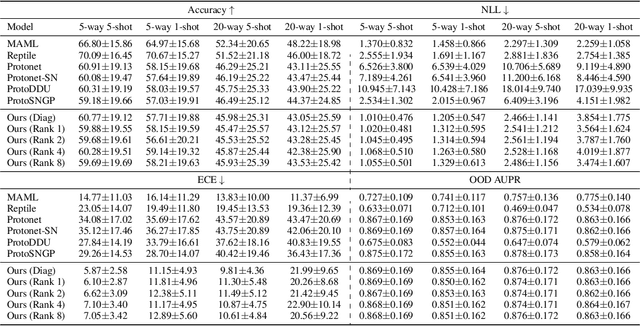
Numerous recent works utilize bi-Lipschitz regularization of neural network layers to preserve relative distances between data instances in the feature spaces of each layer. This distance sensitivity with respect to the data aids in tasks such as uncertainty calibration and out-of-distribution (OOD) detection. In previous works, features extracted with a distance sensitive model are used to construct feature covariance matrices which are used in deterministic uncertainty estimation or OOD detection. However, in cases where there is a distribution over tasks, these methods result in covariances which are sub-optimal, as they may not leverage all of the meta information which can be shared among tasks. With the use of an attentive set encoder, we propose to meta learn either diagonal or diagonal plus low-rank factors to efficiently construct task specific covariance matrices. Additionally, we propose an inference procedure which utilizes scaled energy to achieve a final predictive distribution which can better separate OOD data, and is well calibrated under a distributional dataset shift.
Sequential Reptile: Inter-Task Gradient Alignment for Multilingual Learning
Oct 06, 2021


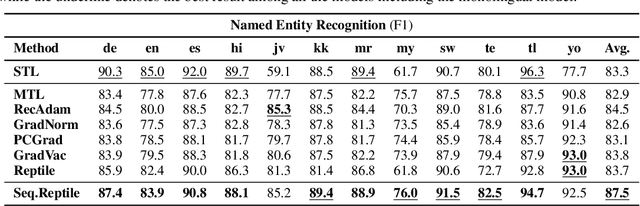
Multilingual models jointly pretrained on multiple languages have achieved remarkable performance on various multilingual downstream tasks. Moreover, models finetuned on a single monolingual downstream task have shown to generalize to unseen languages. In this paper, we first show that it is crucial for those tasks to align gradients between them in order to maximize knowledge transfer while minimizing negative transfer. Despite its importance, the existing methods for gradient alignment either have a completely different purpose, ignore inter-task alignment, or aim to solve continual learning problems in rather inefficient ways. As a result of the misaligned gradients between tasks, the model suffers from severe negative transfer in the form of catastrophic forgetting of the knowledge acquired from the pretraining. To overcome the limitations, we propose a simple yet effective method that can efficiently align gradients between tasks. Specifically, we perform each inner-optimization by sequentially sampling batches from all the tasks, followed by a Reptile outer update. Thanks to the gradients aligned between tasks by our method, the model becomes less vulnerable to negative transfer and catastrophic forgetting. We extensively validate our method on various multi-task learning and zero-shot cross-lingual transfer tasks, where our method largely outperforms all the relevant baselines we consider.
Online Hyperparameter Meta-Learning with Hypergradient Distillation
Oct 06, 2021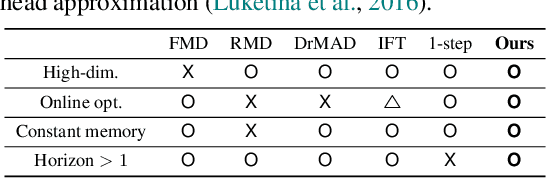
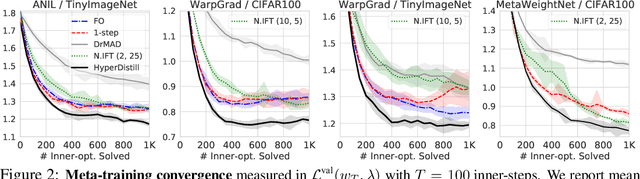
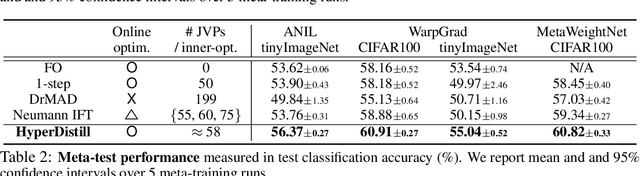
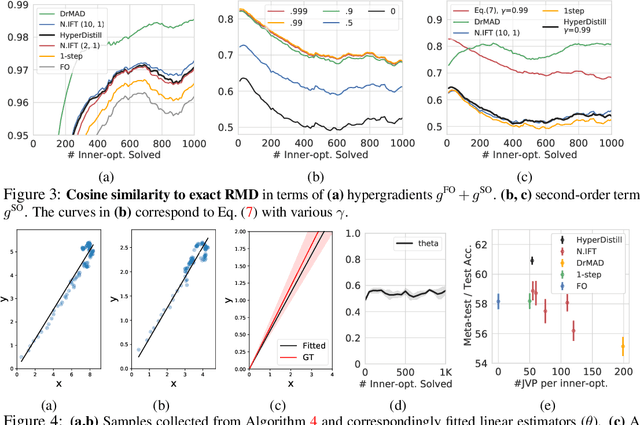
Many gradient-based meta-learning methods assume a set of parameters that do not participate in inner-optimization, which can be considered as hyperparameters. Although such hyperparameters can be optimized using the existing gradient-based hyperparameter optimization (HO) methods, they suffer from the following issues. Unrolled differentiation methods do not scale well to high-dimensional hyperparameters or horizon length, Implicit Function Theorem (IFT) based methods are restrictive for online optimization, and short horizon approximations suffer from short horizon bias. In this work, we propose a novel HO method that can overcome these limitations, by approximating the second-order term with knowledge distillation. Specifically, we parameterize a single Jacobian-vector product (JVP) for each HO step and minimize the distance from the true second-order term. Our method allows online optimization and also is scalable to the hyperparameter dimension and the horizon length. We demonstrate the effectiveness of our method on two different meta-learning methods and three benchmark datasets.
Large-Scale Meta-Learning with Continual Trajectory Shifting
Feb 14, 2021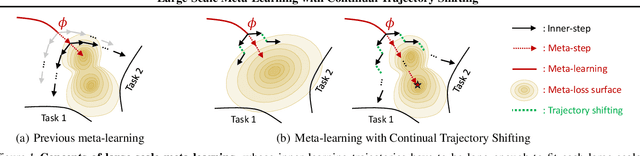
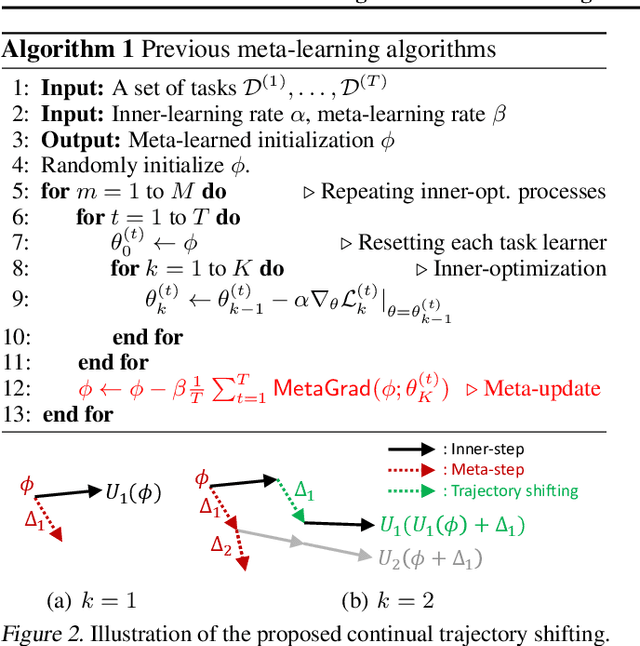
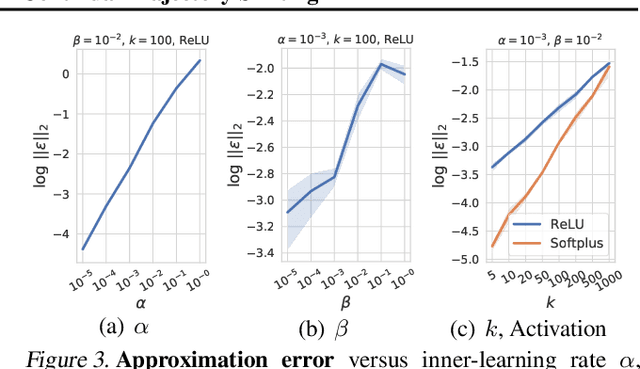

Meta-learning of shared initialization parameters has shown to be highly effective in solving few-shot learning tasks. However, extending the framework to many-shot scenarios, which may further enhance its practicality, has been relatively overlooked due to the technical difficulties of meta-learning over long chains of inner-gradient steps. In this paper, we first show that allowing the meta-learners to take a larger number of inner gradient steps better captures the structure of heterogeneous and large-scale task distributions, thus results in obtaining better initialization points. Further, in order to increase the frequency of meta-updates even with the excessively long inner-optimization trajectories, we propose to estimate the required shift of the task-specific parameters with respect to the change of the initialization parameters. By doing so, we can arbitrarily increase the frequency of meta-updates and thus greatly improve the meta-level convergence as well as the quality of the learned initializations. We validate our method on a heterogeneous set of large-scale tasks and show that the algorithm largely outperforms the previous first-order meta-learning methods in terms of both generalization performance and convergence, as well as multi-task learning and fine-tuning baselines.