 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood hacking in probabilistic program synthesis
Mar 25, 2026When language models are trained by reinforcement learning (RL) to write probabilistic programs, they can artificially inflate their marginal-likelihood reward by producing programs whose data distribution fails to normalise instead of fitting the data better. We call this failure likelihood hacking (LH). We formalise LH in a core probabilistic programming language (PPL) and give sufficient syntactic conditions for its prevention, proving that a safe language fragment $\mathcal{L}_{\text{safe}}$ satisfying these conditions cannot produce likelihood-hacking programs. Empirically, we show that GRPO-trained models generating PyMC code discover LH exploits within the first few training steps, driving violation rates well above the untrained-model baseline. We implement $\mathcal{L}_{\text{safe}}$'s conditions as $\texttt{SafeStan}$, a LH-resistant modification of Stan, and show empirically that it prevents LH under optimisation pressure. These results show that language-level safety constraints are both theoretically grounded and effective in practice for automated Bayesian model discovery.
Discrete diffusion samplers and bridges: Off-policy algorithms and applications in latent spaces
Feb 05, 2026Sampling from a distribution $p(x) \propto e^{-\mathcal{E}(x)}$ known up to a normalising constant is an important and challenging problem in statistics. Recent years have seen the rise of a new family of amortised sampling algorithms, commonly referred to as diffusion samplers, that enable fast and efficient sampling from an unnormalised density. Such algorithms have been widely studied for continuous-space sampling tasks; however, their application to problems in discrete space remains largely unexplored. Although some progress has been made in this area, discrete diffusion samplers do not take full advantage of ideas commonly used for continuous-space sampling. In this paper, we propose to bridge this gap by introducing off-policy training techniques for discrete diffusion samplers. We show that these techniques improve the performance of discrete samplers on both established and new synthetic benchmarks. Next, we generalise discrete diffusion samplers to the task of bridging between two arbitrary distributions, introducing data-to-energy Schrödinger bridge training for the discrete domain for the first time. Lastly, we showcase the application of the proposed diffusion samplers to data-free posterior sampling in the discrete latent spaces of image generative models.
A Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Forgetting is Everywhere
Nov 06, 2025A fundamental challenge in developing general learning algorithms is their tendency to forget past knowledge when adapting to new data. Addressing this problem requires a principled understanding of forgetting; yet, despite decades of study, no unified definition has emerged that provides insights into the underlying dynamics of learning. We propose an algorithm- and task-agnostic theory that characterises forgetting as a lack of self-consistency in a learner's predictive distribution over future experiences, manifesting as a loss of predictive information. Our theory naturally yields a general measure of an algorithm's propensity to forget. To validate the theory, we design a comprehensive set of experiments that span classification, regression, generative modelling, and reinforcement learning. We empirically demonstrate how forgetting is present across all learning settings and plays a significant role in determining learning efficiency. Together, these results establish a principled understanding of forgetting and lay the foundation for analysing and improving the information retention capabilities of general learning algorithms.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Fast Flow-based Visuomotor Policies via Conditional Optimal Transport Couplings
May 02, 2025Diffusion and flow matching policies have recently demonstrated remarkable performance in robotic applications by accurately capturing multimodal robot trajectory distributions. However, their computationally expensive inference, due to the numerical integration of an ODE or SDE, limits their applicability as real-time controllers for robots. We introduce a methodology that utilizes conditional Optimal Transport couplings between noise and samples to enforce straight solutions in the flow ODE for robot action generation tasks. We show that naively coupling noise and samples fails in conditional tasks and propose incorporating condition variables into the coupling process to improve few-step performance. The proposed few-step policy achieves a 4% higher success rate with a 10x speed-up compared to Diffusion Policy on a diverse set of simulation tasks. Moreover, it produces high-quality and diverse action trajectories within 1-2 steps on a set of real-world robot tasks. Our method also retains the same training complexity as Diffusion Policy and vanilla Flow Matching, in contrast to distillation-based approaches.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
Learning Decision Trees as Amortized Structure Inference
Mar 10, 2025Building predictive models for tabular data presents fundamental challenges, notably in scaling consistently, i.e., more resources translating to better performance, and generalizing systematically beyond the training data distribution. Designing decision tree models remains especially challenging given the intractably large search space, and most existing methods rely on greedy heuristics, while deep learning inductive biases expect a temporal or spatial structure not naturally present in tabular data. We propose a hybrid amortized structure inference approach to learn predictive decision tree ensembles given data, formulating decision tree construction as a sequential planning problem. We train a deep reinforcement learning (GFlowNet) policy to solve this problem, yielding a generative model that samples decision trees from the Bayesian posterior. We show that our approach, DT-GFN, outperforms state-of-the-art decision tree and deep learning methods on standard classification benchmarks derived from real-world data, robustness to distribution shifts, and anomaly detection, all while yielding interpretable models with shorter description lengths. Samples from the trained DT-GFN model can be ensembled to construct a random forest, and we further show that the performance of scales consistently in ensemble size, yielding ensembles of predictors that continue to generalize systematically.
In-Context Parametric Inference: Point or Distribution Estimators?
Feb 17, 2025Bayesian and frequentist inference are two fundamental paradigms in statistical estimation. Bayesian methods treat hypotheses as random variables, incorporating priors and updating beliefs via Bayes' theorem, whereas frequentist methods assume fixed but unknown hypotheses, relying on estimators like maximum likelihood. While extensive research has compared these approaches, the frequentist paradigm of obtaining point estimates has become predominant in deep learning, as Bayesian inference is challenging due to the computational complexity and the approximation gap of posterior estimation methods. However, a good understanding of trade-offs between the two approaches is lacking in the regime of amortized estimators, where in-context learners are trained to estimate either point values via maximum likelihood or maximum a posteriori estimation, or full posteriors using normalizing flows, score-based diffusion samplers, or diagonal Gaussian approximations, conditioned on observations. To help resolve this, we conduct a rigorous comparative analysis spanning diverse problem settings, from linear models to shallow neural networks, with a robust evaluation framework assessing both in-distribution and out-of-distribution generalization on tractable tasks. Our experiments indicate that amortized point estimators generally outperform posterior inference, though the latter remain competitive in some low-dimensional problems, and we further discuss why this might be the case.
Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models
Feb 10, 2025
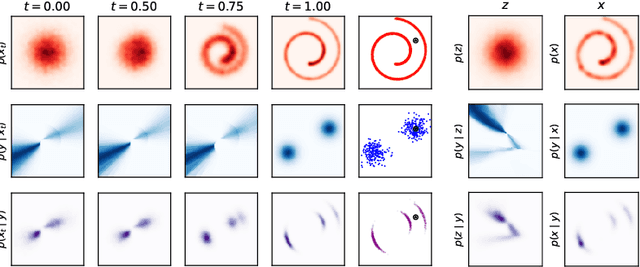


Any well-behaved generative model over a variable $\mathbf{x}$ can be expressed as a deterministic transformation of an exogenous ('outsourced') Gaussian noise variable $\mathbf{z}$: $\mathbf{x}=f_\theta(\mathbf{z})$. In such a model (e.g., a VAE, GAN, or continuous-time flow-based model), sampling of the target variable $\mathbf{x} \sim p_\theta(\mathbf{x})$ is straightforward, but sampling from a posterior distribution of the form $p(\mathbf{x}\mid\mathbf{y}) \propto p_\theta(\mathbf{x})r(\mathbf{x},\mathbf{y})$, where $r$ is a constraint function depending on an auxiliary variable $\mathbf{y}$, is generally intractable. We propose to amortize the cost of sampling from such posterior distributions with diffusion models that sample a distribution in the noise space ($\mathbf{z}$). These diffusion samplers are trained by reinforcement learning algorithms to enforce that the transformed samples $f_\theta(\mathbf{z})$ are distributed according to the posterior in the data space ($\mathbf{x}$). For many models and constraints of interest, the posterior in the noise space is smoother than the posterior in the data space, making it more amenable to such amortized inference. Our method enables conditional sampling under unconditional GAN, (H)VAE, and flow-based priors, comparing favorably both with current amortized and non-amortized inference methods. We demonstrate the proposed outsourced diffusion sampling in several experiments with large pretrained prior models: conditional image generation, reinforcement learning with human feedback, and protein structure generation.