 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Expressive Multi-Token Prediction with Probabilistic Circuits
Nov 14, 2025Multi-token prediction (MTP) is a prominent strategy to significantly speed up generation in large language models (LLMs), including byte-level LLMs, which are tokeniser-free but prohibitively slow. However, existing MTP methods often sacrifice expressiveness by assuming independence between future tokens. In this work, we investigate the trade-off between expressiveness and latency in MTP within the framework of probabilistic circuits (PCs). Our framework, named MTPC, allows one to explore different ways to encode the joint distributions over future tokens by selecting different circuit architectures, generalising classical models such as (hierarchical) mixture models, hidden Markov models and tensor networks. We show the efficacy of MTPC by retrofitting existing byte-level LLMs, such as EvaByte. Our experiments show that, when combined with speculative decoding, MTPC significantly speeds up generation compared to MTP with independence assumptions, while guaranteeing to retain the performance of the original verifier LLM. We also rigorously study the optimal trade-off between expressiveness and latency when exploring the possible parameterisations of MTPC, such as PC architectures and partial layer sharing between the verifier and draft LLMs.
Symbol Grounding in Neuro-Symbolic AI: A Gentle Introduction to Reasoning Shortcuts
Oct 16, 2025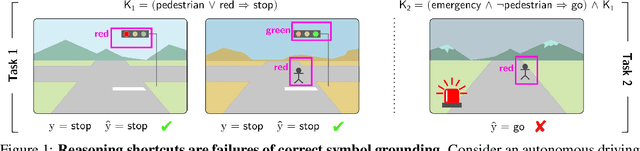

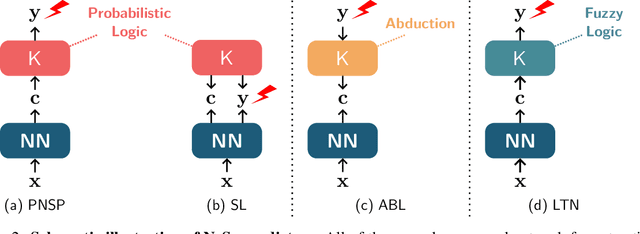
Neuro-symbolic (NeSy) AI aims to develop deep neural networks whose predictions comply with prior knowledge encoding, e.g. safety or structural constraints. As such, it represents one of the most promising avenues for reliable and trustworthy AI. The core idea behind NeSy AI is to combine neural and symbolic steps: neural networks are typically responsible for mapping low-level inputs into high-level symbolic concepts, while symbolic reasoning infers predictions compatible with the extracted concepts and the prior knowledge. Despite their promise, it was recently shown that - whenever the concepts are not supervised directly - NeSy models can be affected by Reasoning Shortcuts (RSs). That is, they can achieve high label accuracy by grounding the concepts incorrectly. RSs can compromise the interpretability of the model's explanations, performance in out-of-distribution scenarios, and therefore reliability. At the same time, RSs are difficult to detect and prevent unless concept supervision is available, which is typically not the case. However, the literature on RSs is scattered, making it difficult for researchers and practitioners to understand and tackle this challenging problem. This overview addresses this issue by providing a gentle introduction to RSs, discussing their causes and consequences in intuitive terms. It also reviews and elucidates existing theoretical characterizations of this phenomenon. Finally, it details methods for dealing with RSs, including mitigation and awareness strategies, and maps their benefits and limitations. By reformulating advanced material in a digestible form, this overview aims to provide a unifying perspective on RSs to lower the bar to entry for tackling them. Ultimately, we hope this overview contributes to the development of reliable NeSy and trustworthy AI models.
Neurosymbolic Reasoning Shortcuts under the Independence Assumption
Jul 15, 2025The ubiquitous independence assumption among symbolic concepts in neurosymbolic (NeSy) predictors is a convenient simplification: NeSy predictors use it to speed up probabilistic reasoning. Recent works like van Krieken et al. (2024) and Marconato et al. (2024) argued that the independence assumption can hinder learning of NeSy predictors and, more crucially, prevent them from correctly modelling uncertainty. There is, however, scepticism in the NeSy community around the scenarios in which the independence assumption actually limits NeSy systems (Faronius and Dos Martires, 2025). In this work, we settle this question by formally showing that assuming independence among symbolic concepts entails that a model can never represent uncertainty over certain concept combinations. Thus, the model fails to be aware of reasoning shortcuts, i.e., the pathological behaviour of NeSy predictors that predict correct downstream tasks but for the wrong reasons.
Neurosymbolic Diffusion Models
May 19, 2025Neurosymbolic (NeSy) predictors combine neural perception with symbolic reasoning to solve tasks like visual reasoning. However, standard NeSy predictors assume conditional independence between the symbols they extract, thus limiting their ability to model interactions and uncertainty - often leading to overconfident predictions and poor out-of-distribution generalisation. To overcome the limitations of the independence assumption, we introduce neurosymbolic diffusion models (NeSyDMs), a new class of NeSy predictors that use discrete diffusion to model dependencies between symbols. Our approach reuses the independence assumption from NeSy predictors at each step of the diffusion process, enabling scalable learning while capturing symbol dependencies and uncertainty quantification. Across both synthetic and real-world benchmarks - including high-dimensional visual path planning and rule-based autonomous driving - NeSyDMs achieve state-of-the-art accuracy among NeSy predictors and demonstrate strong calibration.
Noise to the Rescue: Escaping Local Minima in Neurosymbolic Local Search
Mar 03, 2025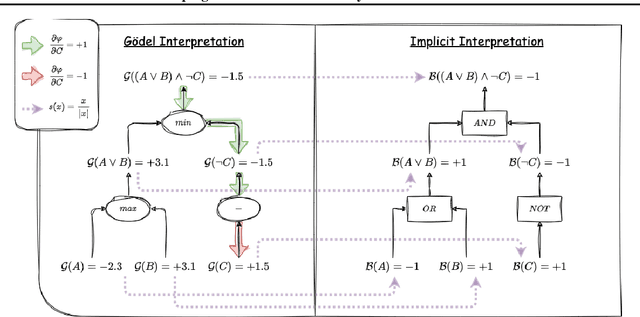

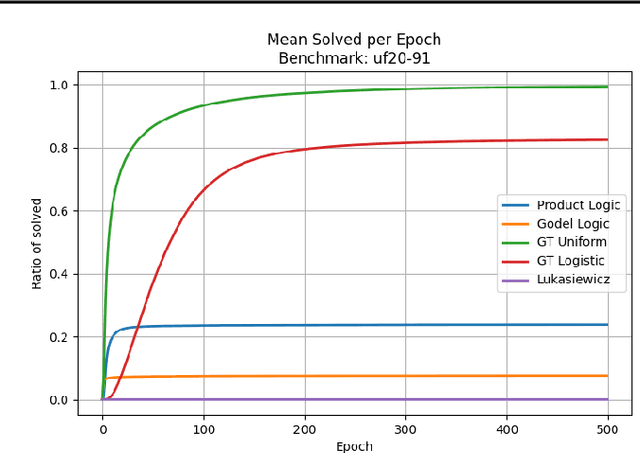

Deep learning has achieved remarkable success across various domains, largely thanks to the efficiency of backpropagation (BP). However, BP's reliance on differentiability poses challenges in neurosymbolic learning, where discrete computation is combined with neural models. We show that applying BP to Godel logic, which represents conjunction and disjunction as min and max, is equivalent to a local search algorithm for SAT solving, enabling the optimisation of discrete Boolean formulas without sacrificing differentiability. However, deterministic local search algorithms get stuck in local optima. Therefore, we propose the Godel Trick, which adds noise to the model's logits to escape local optima. We evaluate the Godel Trick on SATLIB, and demonstrate its ability to solve a broad range of SAT problems. Additionally, we apply it to neurosymbolic models and achieve state-of-the-art performance on Visual Sudoku, all while avoiding expensive probabilistic reasoning. These results highlight the Godel Trick's potential as a robust, scalable approach for integrating symbolic reasoning with neural architectures.
Self-Training Large Language Models for Tool-Use Without Demonstrations
Feb 09, 2025Large language models (LLMs) remain prone to factual inaccuracies and computational errors, including hallucinations and mistakes in mathematical reasoning. Recent work augmented LLMs with tools to mitigate these shortcomings, but often requires curated gold tool-use demonstrations. In this paper, we investigate whether LLMs can learn to use tools without demonstrations. First, we analyse zero-shot prompting strategies to guide LLMs in tool utilisation. Second, we propose a self-training method to synthesise tool-use traces using the LLM itself. We compare supervised fine-tuning and preference fine-tuning techniques for fine-tuning the model on datasets constructed using existing Question Answering (QA) datasets, i.e., TriviaQA and GSM8K. Experiments show that tool-use enhances performance on a long-tail knowledge task: 3.7% on PopQA, which is used solely for evaluation, but leads to mixed results on other datasets, i.e., TriviaQA, GSM8K, and NQ-Open. Our findings highlight the potential and challenges of integrating external tools into LLMs without demonstrations.
Mixtures of In-Context Learners
Nov 05, 2024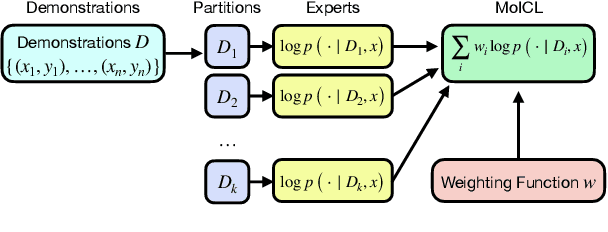
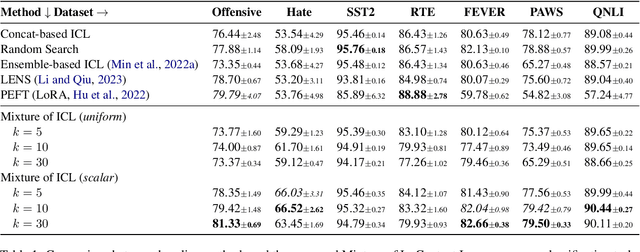
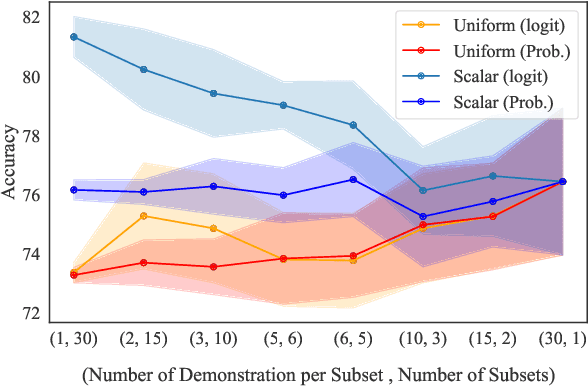

In-context learning (ICL) adapts LLMs by providing demonstrations without fine-tuning the model parameters; however, it does not differentiate between demonstrations and quadratically increases the complexity of Transformer LLMs, exhausting the memory. As a solution, we propose Mixtures of In-Context Learners (MoICL), a novel approach to treat subsets of demonstrations as experts and learn a weighting function to merge their output distributions based on a training set. In our experiments, we show performance improvements on 5 out of 7 classification datasets compared to a set of strong baselines (up to +13\% compared to ICL and LENS). Moreover, we enhance the Pareto frontier of ICL by reducing the inference time needed to achieve the same performance with fewer demonstrations. Finally, MoICL is more robust to out-of-domain (up to +11\%), imbalanced (up to +49\%), or noisy demonstrations (up to +38\%) or can filter these out from datasets. Overall, MoICL is a more expressive approach to learning from demonstrations without exhausting the context window or memory.
A Benchmark Suite for Systematically Evaluating Reasoning Shortcuts
Jun 14, 2024



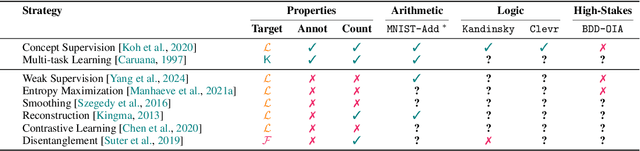
The advent of powerful neural classifiers has increased interest in problems that require both learning and reasoning. These problems are critical for understanding important properties of models, such as trustworthiness, generalization, interpretability, and compliance to safety and structural constraints. However, recent research observed that tasks requiring both learning and reasoning on background knowledge often suffer from reasoning shortcuts (RSs): predictors can solve the downstream reasoning task without associating the correct concepts to the high-dimensional data. To address this issue, we introduce rsbench, a comprehensive benchmark suite designed to systematically evaluate the impact of RSs on models by providing easy access to highly customizable tasks affected by RSs. Furthermore, rsbench implements common metrics for evaluating concept quality and introduces novel formal verification procedures for assessing the presence of RSs in learning tasks. Using rsbench, we highlight that obtaining high quality concepts in both purely neural and neuro-symbolic models is a far-from-solved problem. rsbench is available at: https://unitn-sml.github.io/rsbench.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
ULLER: A Unified Language for Learning and Reasoning
May 01, 2024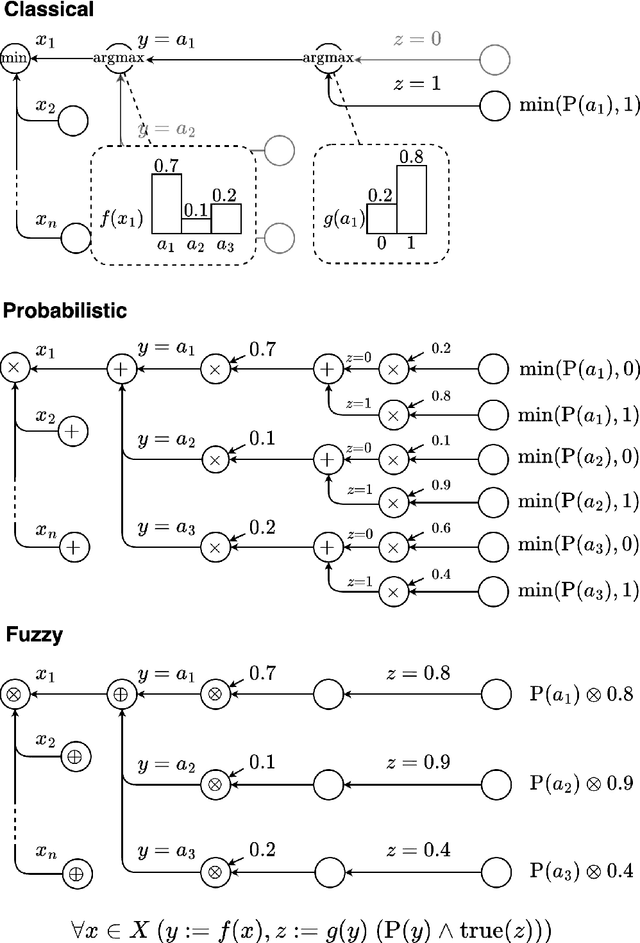
The field of neuro-symbolic artificial intelligence (NeSy), which combines learning and reasoning, has recently experienced significant growth. There now are a wide variety of NeSy frameworks, each with its own specific language for expressing background knowledge and how to relate it to neural networks. This heterogeneity hinders accessibility for newcomers and makes comparing different NeSy frameworks challenging. We propose a unified language for NeSy, which we call ULLER, a Unified Language for LEarning and Reasoning. ULLER encompasses a wide variety of settings, while ensuring that knowledge described in it can be used in existing NeSy systems. ULLER has a neuro-symbolic first-order syntax for which we provide example semantics including classical, fuzzy, and probabilistic logics. We believe ULLER is a first step towards making NeSy research more accessible and comparable, paving the way for libraries that streamline training and evaluation across a multitude of semantics, knowledge bases, and NeSy systems.