 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtures of In-Context Learners
Paper and Code
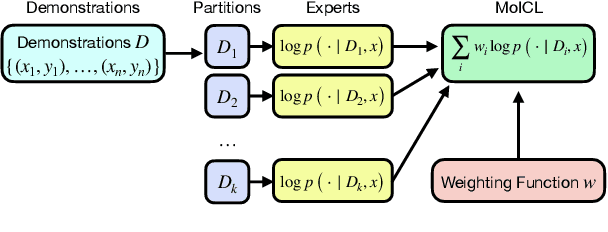
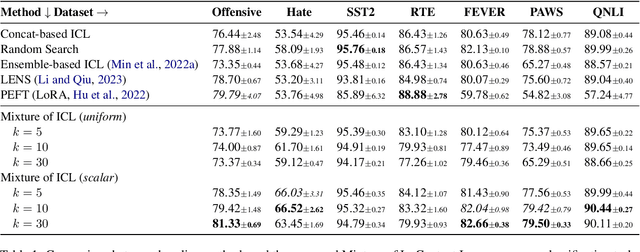
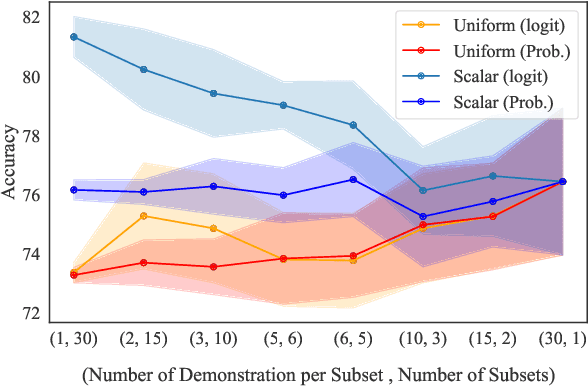

In-context learning (ICL) adapts LLMs by providing demonstrations without fine-tuning the model parameters; however, it does not differentiate between demonstrations and quadratically increases the complexity of Transformer LLMs, exhausting the memory. As a solution, we propose Mixtures of In-Context Learners (MoICL), a novel approach to treat subsets of demonstrations as experts and learn a weighting function to merge their output distributions based on a training set. In our experiments, we show performance improvements on 5 out of 7 classification datasets compared to a set of strong baselines (up to +13\% compared to ICL and LENS). Moreover, we enhance the Pareto frontier of ICL by reducing the inference time needed to achieve the same performance with fewer demonstrations. Finally, MoICL is more robust to out-of-domain (up to +11\%), imbalanced (up to +49\%), or noisy demonstrations (up to +38\%) or can filter these out from datasets. Overall, MoICL is a more expressive approach to learning from demonstrations without exhausting the context window or memory.