 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Expressive Multi-Token Prediction with Probabilistic Circuits
Nov 14, 2025Multi-token prediction (MTP) is a prominent strategy to significantly speed up generation in large language models (LLMs), including byte-level LLMs, which are tokeniser-free but prohibitively slow. However, existing MTP methods often sacrifice expressiveness by assuming independence between future tokens. In this work, we investigate the trade-off between expressiveness and latency in MTP within the framework of probabilistic circuits (PCs). Our framework, named MTPC, allows one to explore different ways to encode the joint distributions over future tokens by selecting different circuit architectures, generalising classical models such as (hierarchical) mixture models, hidden Markov models and tensor networks. We show the efficacy of MTPC by retrofitting existing byte-level LLMs, such as EvaByte. Our experiments show that, when combined with speculative decoding, MTPC significantly speeds up generation compared to MTP with independence assumptions, while guaranteeing to retain the performance of the original verifier LLM. We also rigorously study the optimal trade-off between expressiveness and latency when exploring the possible parameterisations of MTPC, such as PC architectures and partial layer sharing between the verifier and draft LLMs.
Neurosymbolic Reasoning Shortcuts under the Independence Assumption
Jul 15, 2025The ubiquitous independence assumption among symbolic concepts in neurosymbolic (NeSy) predictors is a convenient simplification: NeSy predictors use it to speed up probabilistic reasoning. Recent works like van Krieken et al. (2024) and Marconato et al. (2024) argued that the independence assumption can hinder learning of NeSy predictors and, more crucially, prevent them from correctly modelling uncertainty. There is, however, scepticism in the NeSy community around the scenarios in which the independence assumption actually limits NeSy systems (Faronius and Dos Martires, 2025). In this work, we settle this question by formally showing that assuming independence among symbolic concepts entails that a model can never represent uncertainty over certain concept combinations. Thus, the model fails to be aware of reasoning shortcuts, i.e., the pathological behaviour of NeSy predictors that predict correct downstream tasks but for the wrong reasons.
Neurosymbolic Diffusion Models
May 19, 2025Neurosymbolic (NeSy) predictors combine neural perception with symbolic reasoning to solve tasks like visual reasoning. However, standard NeSy predictors assume conditional independence between the symbols they extract, thus limiting their ability to model interactions and uncertainty - often leading to overconfident predictions and poor out-of-distribution generalisation. To overcome the limitations of the independence assumption, we introduce neurosymbolic diffusion models (NeSyDMs), a new class of NeSy predictors that use discrete diffusion to model dependencies between symbols. Our approach reuses the independence assumption from NeSy predictors at each step of the diffusion process, enabling scalable learning while capturing symbol dependencies and uncertainty quantification. Across both synthetic and real-world benchmarks - including high-dimensional visual path planning and rule-based autonomous driving - NeSyDMs achieve state-of-the-art accuracy among NeSy predictors and demonstrate strong calibration.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
Training Plug-n-Play Knowledge Modules with Deep Context Distillation
Mar 11, 2025Dynamically integrating new or rapidly evolving information after (Large) Language Model pre-training remains challenging, particularly in low-data scenarios or when dealing with private and specialized documents. In-context learning and retrieval-augmented generation (RAG) face limitations, including their high inference costs and their inability to capture global document information. In this paper, we propose a way of modularizing knowledge by training document-level Knowledge Modules (KMs). KMs are lightweight components implemented as parameter-efficient LoRA modules, which are trained to store information about new documents and can be easily plugged into models on demand. We show that next-token prediction performs poorly as the training objective for KMs. We instead propose Deep Context Distillation: we learn KMs parameters such as to simulate hidden states and logits of a teacher that takes the document in context. Our method outperforms standard next-token prediction and pre-instruction training techniques, across two datasets. Finally, we highlight synergies between KMs and retrieval-augmented generation.
A Grounded Typology of Word Classes
Dec 13, 2024We propose a grounded approach to meaning in language typology. We treat data from perceptual modalities, such as images, as a language-agnostic representation of meaning. Hence, we can quantify the function--form relationship between images and captions across languages. Inspired by information theory, we define "groundedness", an empirical measure of contextual semantic contentfulness (formulated as a difference in surprisal) which can be computed with multilingual multimodal language models. As a proof of concept, we apply this measure to the typology of word classes. Our measure captures the contentfulness asymmetry between functional (grammatical) and lexical (content) classes across languages, but contradicts the view that functional classes do not convey content. Moreover, we find universal trends in the hierarchy of groundedness (e.g., nouns > adjectives > verbs), and show that our measure partly correlates with psycholinguistic concreteness norms in English. We release a dataset of groundedness scores for 30 languages. Our results suggest that the grounded typology approach can provide quantitative evidence about semantic function in language.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
Mixtures of In-Context Learners
Nov 05, 2024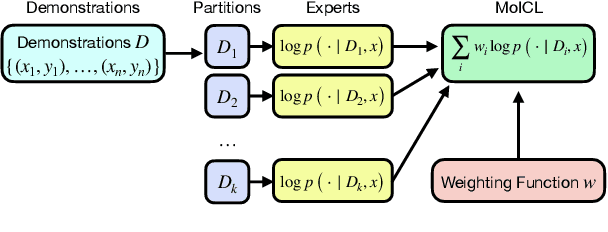
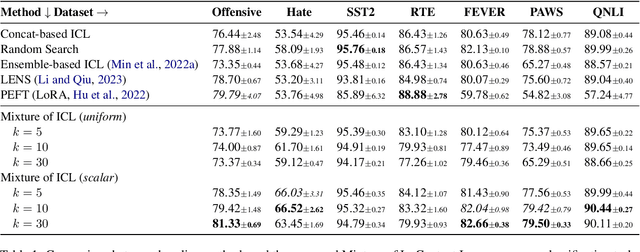
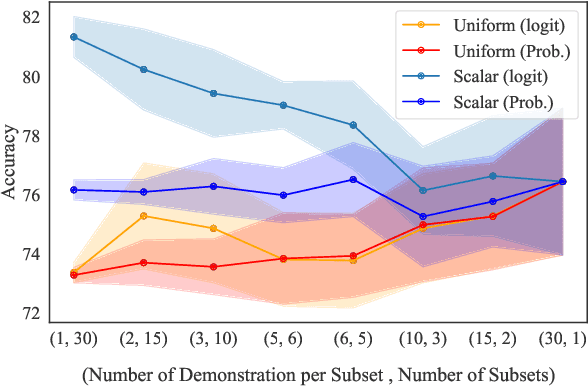

In-context learning (ICL) adapts LLMs by providing demonstrations without fine-tuning the model parameters; however, it does not differentiate between demonstrations and quadratically increases the complexity of Transformer LLMs, exhausting the memory. As a solution, we propose Mixtures of In-Context Learners (MoICL), a novel approach to treat subsets of demonstrations as experts and learn a weighting function to merge their output distributions based on a training set. In our experiments, we show performance improvements on 5 out of 7 classification datasets compared to a set of strong baselines (up to +13\% compared to ICL and LENS). Moreover, we enhance the Pareto frontier of ICL by reducing the inference time needed to achieve the same performance with fewer demonstrations. Finally, MoICL is more robust to out-of-domain (up to +11\%), imbalanced (up to +49\%), or noisy demonstrations (up to +38\%) or can filter these out from datasets. Overall, MoICL is a more expressive approach to learning from demonstrations without exhausting the context window or memory.
Multi-Head Adapter Routing for Data-Efficient Fine-Tuning
Nov 07, 2022Parameter-efficient fine-tuning (PEFT) methods can adapt large language models to downstream tasks by training a small amount of newly added parameters. In multi-task settings, PEFT adapters typically train on each task independently, inhibiting transfer across tasks, or on the concatenation of all tasks, which can lead to negative interference. To address this, Polytropon (Ponti et al.) jointly learns an inventory of PEFT adapters and a routing function to share variable-size sets of adapters across tasks. Subsequently, adapters can be re-combined and fine-tuned on novel tasks even with limited data. In this paper, we investigate to what extent the ability to control which adapters are active for each task leads to sample-efficient generalization. Thus, we propose less expressive variants where we perform weighted averaging of the adapters before few-shot adaptation (Poly-mu) instead of learning a routing function. Moreover, we introduce more expressive variants where finer-grained task-adapter allocation is learned through a multi-head routing function (Poly-S). We test these variants on three separate benchmarks for multi-task learning. We find that Poly-S achieves gains on all three (up to 5.3 points on average) over strong baselines, while incurring a negligible additional cost in parameter count. In particular, we find that instruction tuning, where models are fully fine-tuned on natural language instructions for each task, is inferior to modular methods such as Polytropon and our proposed variants.
Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
May 08, 2022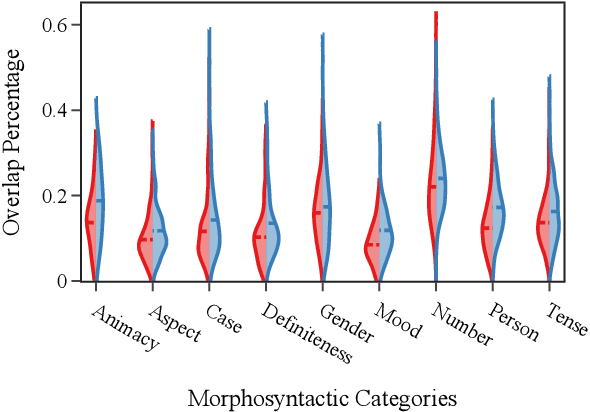
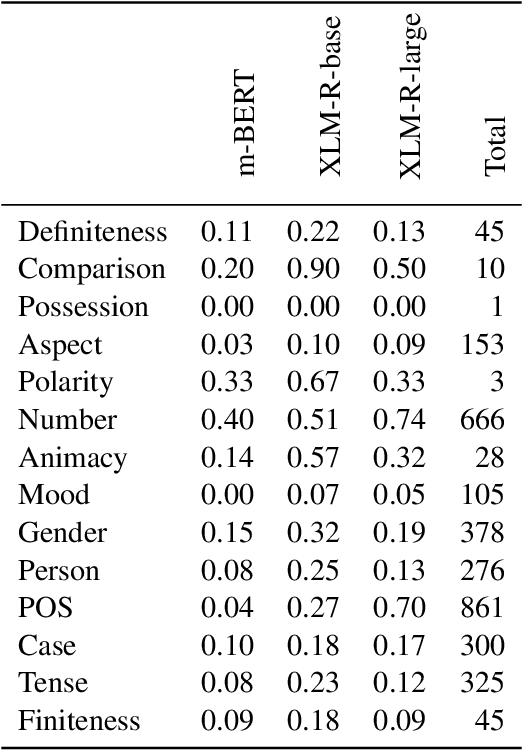
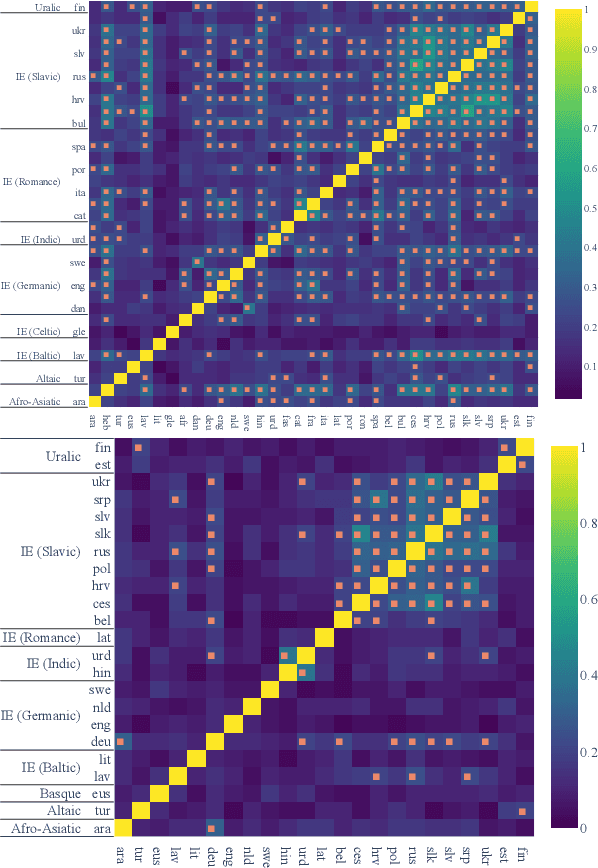
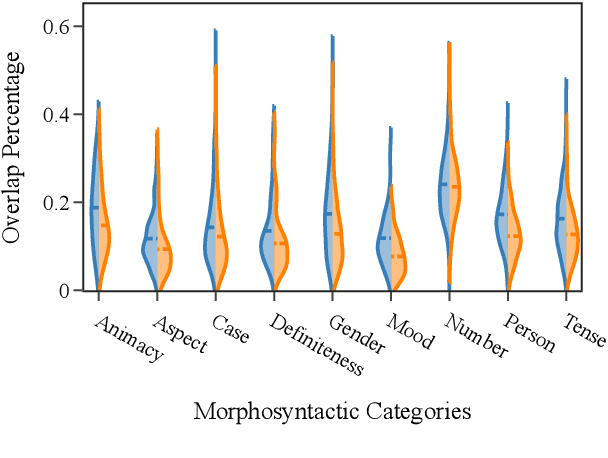
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.