 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainNet: Structured Metaphor and Metonymy in WordNet
Mar 29, 2024



The senses of a word exhibit rich internal structure. In a typical lexicon, this structure is overlooked: a word's senses are encoded as a list without inter-sense relations. We present ChainNet, a lexical resource which for the first time explicitly identifies these structures. ChainNet expresses how senses in the Open English Wordnet are derived from one another: every nominal sense of a word is either connected to another sense by metaphor or metonymy, or is disconnected in the case of homonymy. Because WordNet senses are linked to resources which capture information about their meaning, ChainNet represents the first dataset of grounded metaphor and metonymy.
Homonymy Information for English WordNet
Dec 16, 2022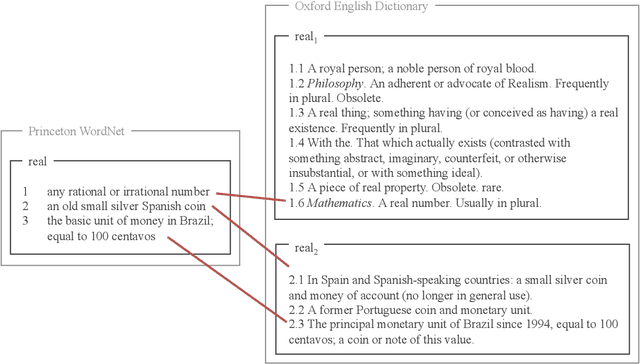
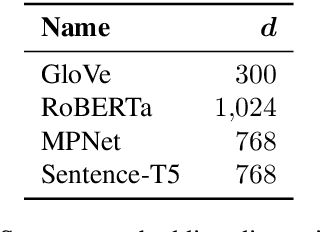

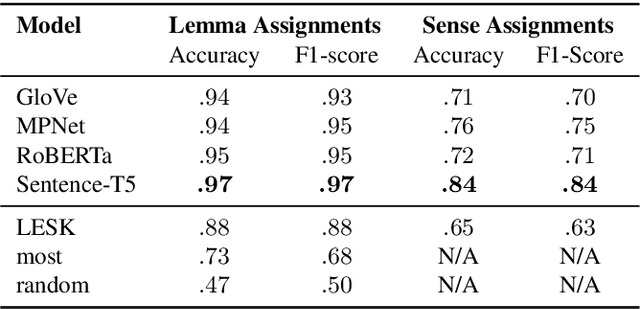
A widely acknowledged shortcoming of WordNet is that it lacks a distinction between word meanings which are systematically related (polysemy), and those which are coincidental (homonymy). Several previous works have attempted to fill this gap, by inferring this information using computational methods. We revisit this task, and exploit recent advances in language modelling to synthesise homonymy annotation for Princeton WordNet. Previous approaches treat the problem using clustering methods; by contrast, our method works by linking WordNet to the Oxford English Dictionary, which contains the information we need. To perform this alignment, we pair definitions based on their proximity in an embedding space produced by a Transformer model. Despite the simplicity of this approach, our best model attains an F1 of .97 on an evaluation set that we annotate. The outcome of our work is a high-quality homonymy annotation layer for Princeton WordNet, which we release.
Metaphorical Polysemy Detection: Conventional Metaphor meets Word Sense Disambiguation
Dec 16, 2022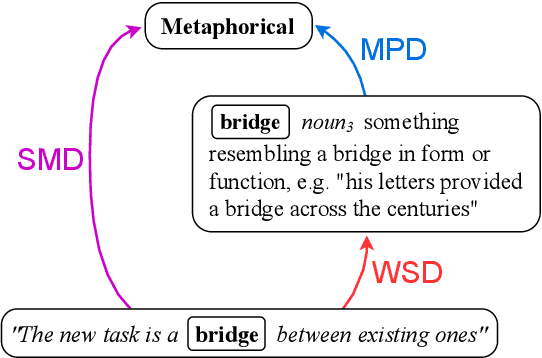


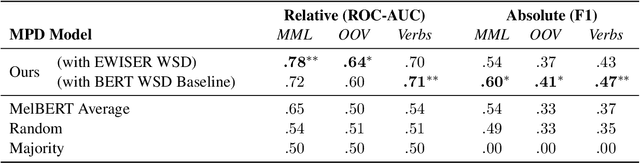
Linguists distinguish between novel and conventional metaphor, a distinction which the metaphor detection task in NLP does not take into account. Instead, metaphoricity is formulated as a property of a token in a sentence, regardless of metaphor type. In this paper, we investigate the limitations of treating conventional metaphors in this way, and advocate for an alternative which we name 'metaphorical polysemy detection' (MPD). In MPD, only conventional metaphoricity is treated, and it is formulated as a property of word senses in a lexicon. We develop the first MPD model, which learns to identify conventional metaphors in the English WordNet. To train it, we present a novel training procedure that combines metaphor detection with word sense disambiguation (WSD). For evaluation, we manually annotate metaphor in two subsets of WordNet. Our model significantly outperforms a strong baseline based on a state-of-the-art metaphor detection model, attaining an ROC-AUC score of .78 (compared to .65) on one of the sets. Additionally, when paired with a WSD model, our approach outperforms a state-of-the-art metaphor detection model at identifying conventional metaphors in text (.659 F1 compared to .626).
UniMorph 4.0: Universal Morphology
May 10, 2022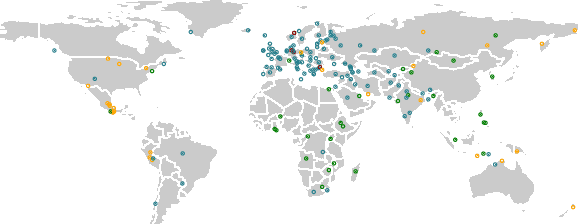

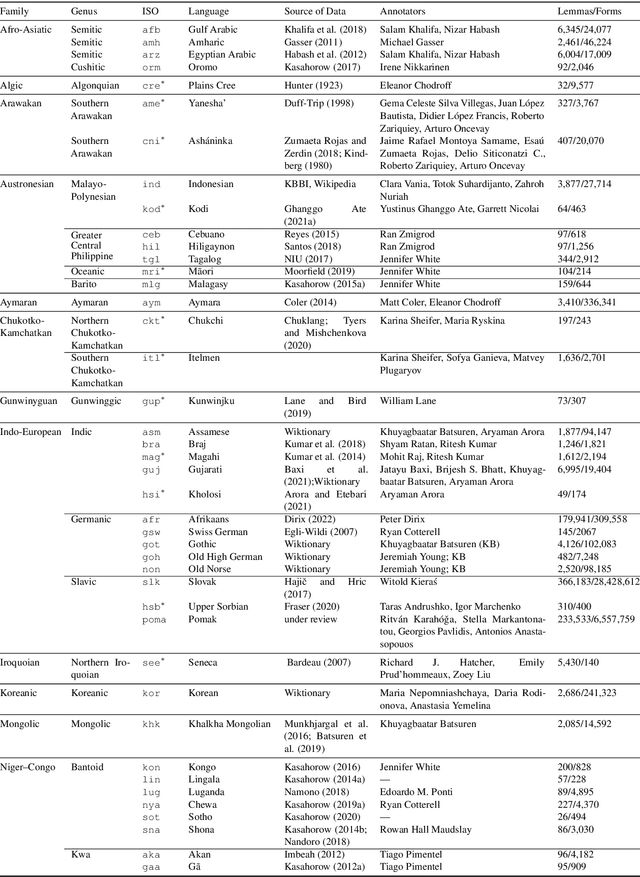
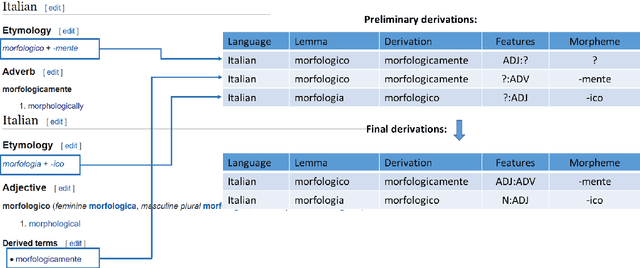
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Do Syntactic Probes Probe Syntax? Experiments with Jabberwocky Probing
Jun 04, 2021



Analysing whether neural language models encode linguistic information has become popular in NLP. One method of doing so, which is frequently cited to support the claim that models like BERT encode syntax, is called probing; probes are small supervised models trained to extract linguistic information from another model's output. If a probe is able to predict a particular structure, it is argued that the model whose output it is trained on must have implicitly learnt to encode it. However, drawing a generalisation about a model's linguistic knowledge about a specific phenomena based on what a probe is able to learn may be problematic: in this work, we show that semantic cues in training data means that syntactic probes do not properly isolate syntax. We generate a new corpus of semantically nonsensical but syntactically well-formed Jabberwocky sentences, which we use to evaluate two probes trained on normal data. We train the probes on several popular language models (BERT, GPT, and RoBERTa), and find that in all settings they perform worse when evaluated on these data, for one probe by an average of 15.4 UUAS points absolute. Although in most cases they still outperform the baselines, their lead is reduced substantially, e.g. by 53% in the case of BERT for one probe. This begs the question: what empirical scores constitute knowing syntax?
Speakers Fill Lexical Semantic Gaps with Context
Oct 05, 2020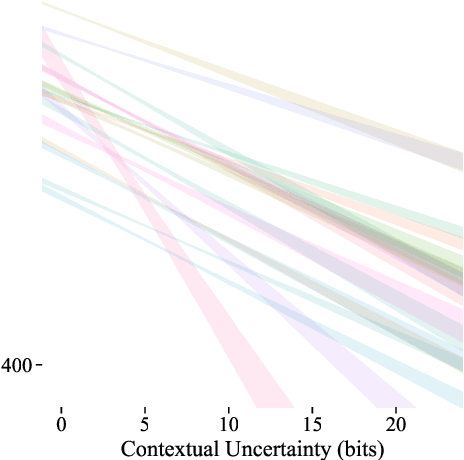
Lexical ambiguity is widespread in language, allowing for the reuse of economical word forms and therefore making language more efficient. If ambiguous words cannot be disambiguated from context, however, this gain in efficiency might make language less clear---resulting in frequent miscommunication. For a language to be clear and efficiently encoded, we posit that the lexical ambiguity of a word type should correlate with how much information context provides about it, on average. To investigate whether this is the case, we operationalise the lexical ambiguity of a word as the entropy of meanings it can take, and provide two ways to estimate this---one which requires human annotation (using WordNet), and one which does not (using BERT), making it readily applicable to a large number of languages. We validate these measures by showing that, on six high-resource languages, there are significant Pearson correlations between our BERT-based estimate of ambiguity and the number of synonyms a word has in WordNet (e.g. $\rho = 0.40$ in English). We then test our main hypothesis---that a word's lexical ambiguity should negatively correlate with its contextual uncertainty---and find significant correlations on all 18 typologically diverse languages we analyse. This suggests that, in the presence of ambiguity, speakers compensate by making contexts more informative.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020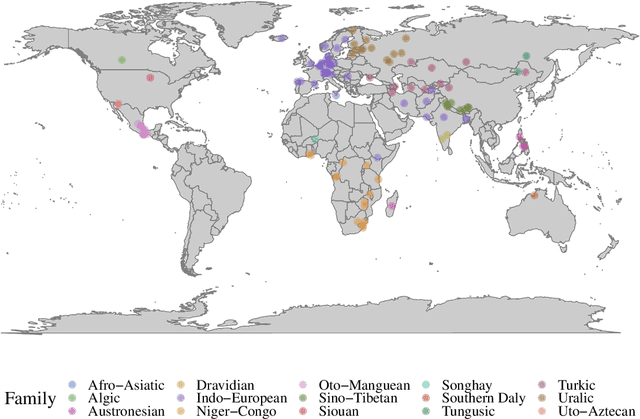
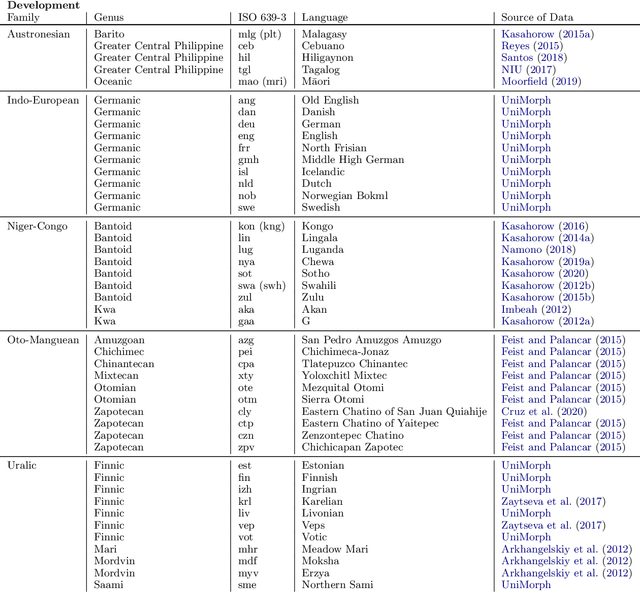
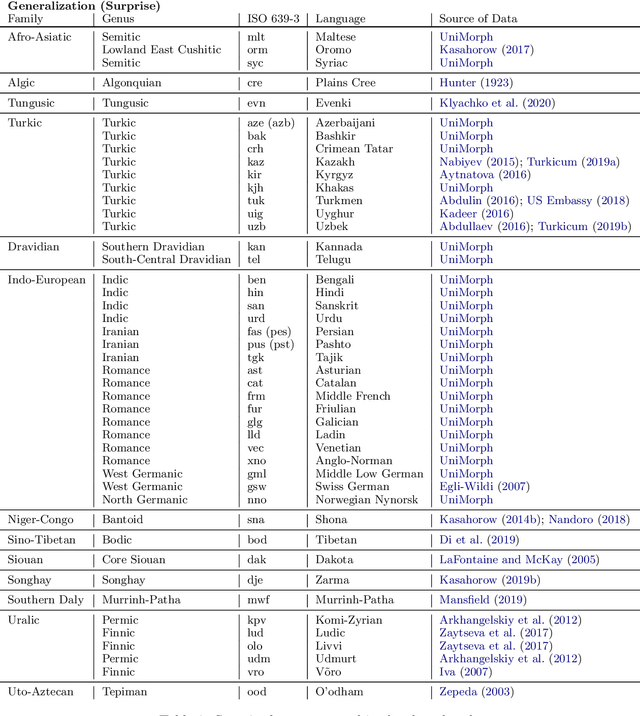
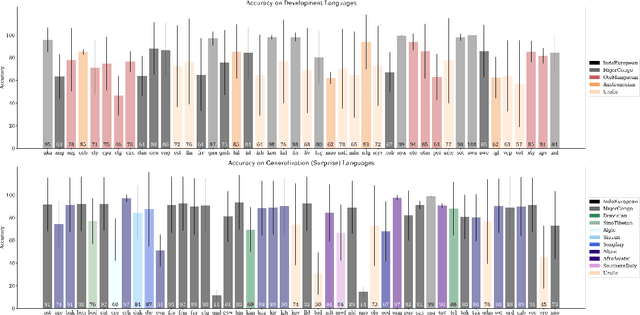
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
A Tale of a Probe and a Parser
May 12, 2020


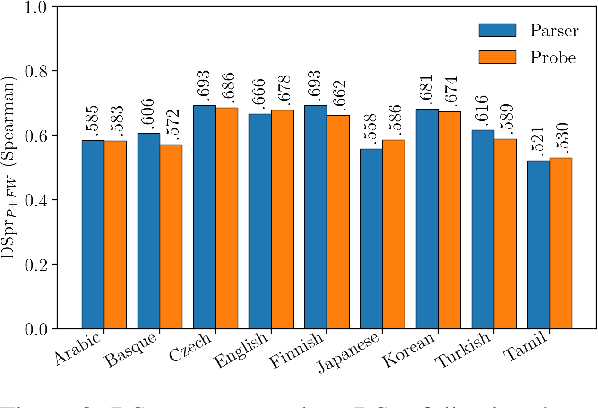
Measuring what linguistic information is encoded in neural models of language has become popular in NLP. Researchers approach this enterprise by training "probes" - supervised models designed to extract linguistic structure from another model's output. One such probe is the structural probe (Hewitt and Manning, 2019), designed to quantify the extent to which syntactic information is encoded in contextualised word representations. The structural probe has a novel design, unattested in the parsing literature, the precise benefit of which is not immediately obvious. To explore whether syntactic probes would do better to make use of existing techniques, we compare the structural probe to a more traditional parser with an identical lightweight parameterisation. The parser outperforms structural probe on UUAS in seven of nine analysed languages, often by a substantial amount (e.g. by 11.1 points in English). Under a second less common metric, however, there is the opposite trend - the structural probe outperforms the parser. This begs the question: which metric should we prefer?
Information-Theoretic Probing for Linguistic Structure
Apr 07, 2020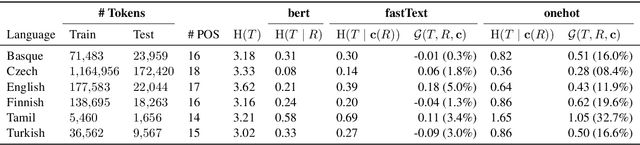
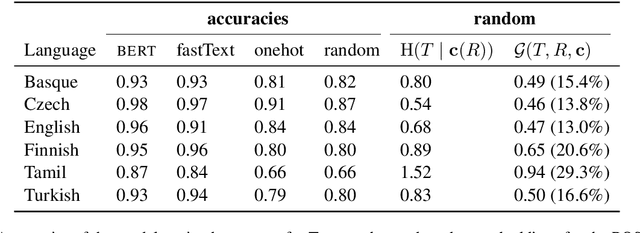
The success of neural networks on a diverse set of NLP tasks has led researchers to question how much do these networks actually know about natural language. Probes are a natural way of assessing this. When probing, a researcher chooses a linguistic task and trains a supervised model to predict annotation in that linguistic task from the network's learned representations. If the probe does well, the researcher may conclude that the representations encode knowledge related to the task. A commonly held belief is that using simpler models as probes is better; the logic is that such models will identify linguistic structure, but not learn the task itself. We propose an information-theoretic formalization of probing as estimating mutual information that contradicts this received wisdom: one should always select the highest performing probe one can, even if it is more complex, since it will result in a tighter estimate. The empirical portion of our paper focuses on obtaining tight estimates for how much information BERT knows about parts of speech in a set of five typologically diverse languages that are often underrepresented in parsing research, plus English, totaling six languages. We find BERT accounts for only at most 5% more information than traditional, type-based word embeddings.
It's All in the Name: Mitigating Gender Bias with Name-Based Counterfactual Data Substitution
Sep 02, 2019

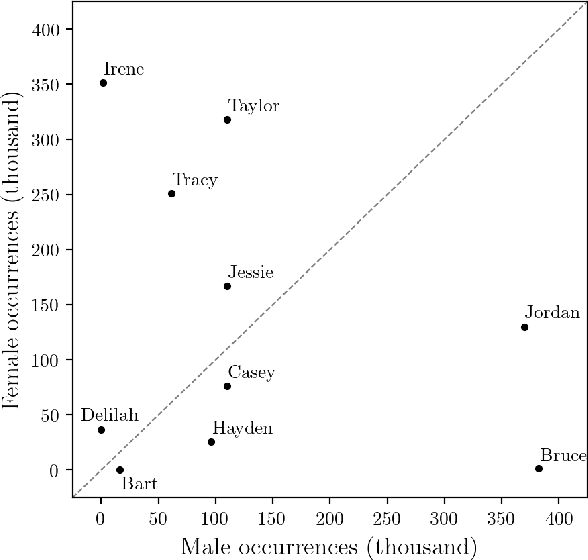
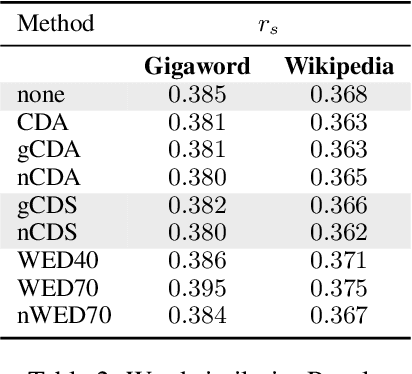
This paper treats gender bias latent in word embeddings. Previous mitigation attempts rely on the operationalisation of gender bias as a projection over a linear subspace. An alternative approach is Counterfactual Data Augmentation (CDA), in which a corpus is duplicated and augmented to remove bias, e.g. by swapping all inherently-gendered words in the copy. We perform an empirical comparison of these approaches on the English Gigaword and Wikipedia, and find that whilst both successfully reduce direct bias and perform well in tasks which quantify embedding quality, CDA variants outperform projection-based methods at the task of drawing non-biased gender analogies by an average of 19% across both corpora. We propose two improvements to CDA: Counterfactual Data Substitution (CDS), a variant of CDA in which potentially biased text is randomly substituted to avoid duplication, and the Names Intervention, a novel name-pairing technique that vastly increases the number of words being treated. CDA/S with the Names Intervention is the only approach which is able to mitigate indirect gender bias: following debiasing, previously biased words are significantly less clustered according to gender (cluster purity is reduced by 49%), thus improving on the state-of-the-art for bias mitigation.