 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNow You (Still) See Me: Detecting Evasive Steganographic Payloads in LLMs
Jun 08, 2026Large language models can be fine-tuned to encode prompt-borne secrets into fluent, seemingly benign outputs. This creates a steganographic exfiltration risk that is difficult to detect with output-level steganalysis. Recent work proposes mechanistic detection using linear probes that recover the secret from internal activations. We show that this defense can be systematically evaded, but that detectability can be recovered through a targeted data-level intervention. First, we extend the detection setup to include a non-linear MLP probe. We then adversarially fine-tune steganographic trojans across five base models: Qwen3-8B, Llama-3.1-8B, Ministral-8B, Qwen3-14B, and Phi-4-14B. The resulting models retain $58$--$79\%$ exact-match secret recovery while evading both ridge and held-out MLP probes, with $1$--$8\%$ average capability degradation across six benchmarks. We then give an information-theoretic characterization of this evasion. Successful evasion preserves recoverability while reducing low-order extractability of the secret from the content-aligned representation, forcing the payload into synergistic interaction with residual degrees of freedom. This motivates a recontextualization dataset that restricts these residual degrees of freedom. On this distribution, both ridge and MLP detectability are restored across all five evasive trojans. Overall, our findings show that activation-based steganography detection is vulnerable to adaptive evasion, but also that theory-guided evaluation distributions can expose otherwise hidden payloads.
Tokenisation via Convex Relaxations
May 21, 2026Tokenisation is an integral part of the current NLP pipeline. Current tokenisation algorithms such as BPE and Unigram are greedy algorithms -- they make locally optimal decisions without considering the resulting vocabulary as a whole. We instead formulate tokeniser construction as a linear program and solve it using convex optimisation tools, yielding a new algorithm we call ConvexTok. We find ConvexTok consistently improves intrinsic tokenisation metrics and the bits-per-byte (BpB) achieved by language models; it also improves downstream task performance, but less consistently. Furthermore, ConvexTok allows the user to certify how far their tokeniser is from optimal, with respect to a certain objective, via a lower bound, and we empirically find it to be within 1\% of optimal at common vocabulary sizes.
What Language is This? Ask Your Tokenizer
Feb 19, 2026Language Identification (LID) is an important component of many multilingual natural language processing pipelines, where it facilitates corpus curation, training data analysis, and cross-lingual evaluation of large language models. Despite near-perfect performance on high-resource languages, existing systems remain brittle in low-resource and closely related language settings. We introduce UniLID, a simple and efficient LID method based on the UnigramLM tokenization algorithm, leveraging its probabilistic framing, parameter estimation technique and inference strategy. In short, we learn language-conditional unigram distributions over a shared tokenizer vocabulary but treat segmentation as a language-specific phenomenon. Our formulation is data- and compute-efficient, supports incremental addition of new languages without retraining existing models, and can naturally be integrated into existing language model tokenization pipelines. Empirical evaluations against widely used baselines, including fastText, GlotLID, and CLD3, show that UniLID achieves competitive performance on standard benchmarks, substantially improves sample efficiency in low-resource settings - surpassing 70% accuracy with as few as five labeled samples per language - and delivers large gains on fine-grained dialect identification.
Operationalising the Superficial Alignment Hypothesis via Task Complexity
Feb 17, 2026The superficial alignment hypothesis (SAH) posits that large language models learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.
What Do Prosody and Text Convey? Characterizing How Meaningful Information is Distributed Across Multiple Channels
Dec 18, 2025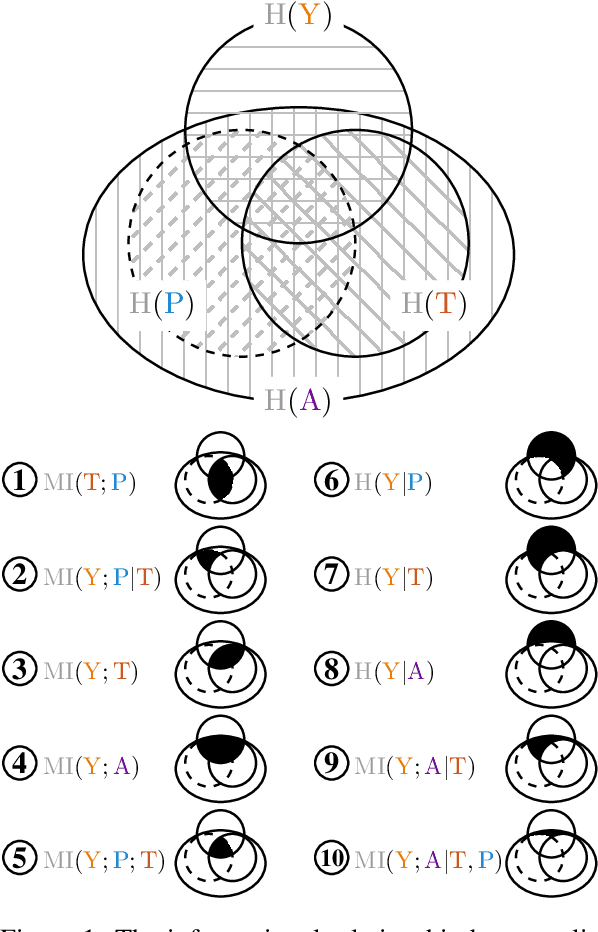
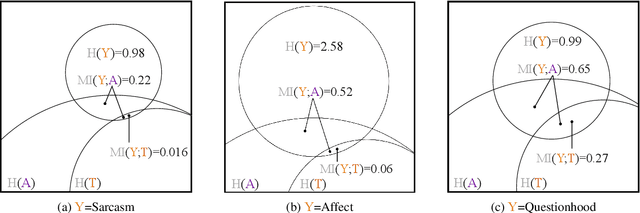
Prosody -- the melody of speech -- conveys critical information often not captured by the words or text of a message. In this paper, we propose an information-theoretic approach to quantify how much information is expressed by prosody alone and not by text, and crucially, what that information is about. Our approach applies large speech and language models to estimate the mutual information between a particular dimension of an utterance's meaning (e.g., its emotion) and any of its communication channels (e.g., audio or text). We then use this approach to quantify how much information is conveyed by audio and text about sarcasm, emotion, and questionhood, using speech from television and podcasts. We find that for sarcasm and emotion the audio channel -- and by implication the prosodic channel -- transmits over an order of magnitude more information about these features than the text channel alone, at least when long-term context beyond the current sentence is unavailable. For questionhood, prosody provides comparatively less additional information. We conclude by outlining a program applying our approach to more dimensions of meaning, communication channels, and languages.
Do Generalisation Results Generalise?
Dec 08, 2025



A large language model's (LLM's) out-of-distribution (OOD) generalisation ability is crucial to its deployment. Previous work assessing LLMs' generalisation performance, however, typically focuses on a single out-of-distribution dataset. This approach may fail to precisely evaluate the capabilities of the model, as the data shifts encountered once a model is deployed are much more diverse. In this work, we investigate whether OOD generalisation results generalise. More specifically, we evaluate a model's performance across multiple OOD testsets throughout a finetuning run; we then evaluate the partial correlation of performances across these testsets, regressing out in-domain performance. This allows us to assess how correlated are generalisation performances once in-domain performance is controlled for. Analysing OLMo2 and OPT, we observe no overarching trend in generalisation results: the existence of a positive or negative correlation between any two OOD testsets depends strongly on the specific choice of model analysed.
Tokenisation over Bounded Alphabets is Hard
Nov 19, 2025
Recent works have shown that tokenisation is NP-complete. However, these works assume tokenisation is applied to inputs with unboundedly large alphabets -- an unrealistic assumption, given that in practice tokenisers operate over fixed-size alphabets, such as bytes or Unicode characters. We close this gap by analysing tokenisation over bounded $n$-ary alphabets, considering two natural variants: bottom-up tokenisation and direct tokenisation, where we must, respectively, select a sequence of merge operations or a vocabulary whose application optimally compresses a dataset. First, we note that proving hardness results for an $n$-ary alphabet proves the same results for alphabets of any larger size. We then prove that even with binary alphabets, both variants are not only NP-complete, but admit no polynomial-time approximation scheme (unless P=NP). We further show that direct tokenisation remains NP-complete even when applied to unary alphabets. While unary alphabets may not be practically useful, this result establishes that the computational intractability of tokenisation is not an artifact of large alphabets or complex constructions, but a fundamental barrier. Overall, our results explain why practical algorithms such as BPE and UnigramLM are heuristic, and points toward approximation algorithms being an important path going forward for tokenisation research.
Convergence and Divergence of Language Models under Different Random Seeds
Sep 30, 2025



In this paper, we investigate the convergence of language models (LMs) trained under different random seeds, measuring convergence as the expected per-token Kullback--Leibler (KL) divergence across seeds. By comparing LM convergence as a function of model size and training checkpoint, we identify a four-phase convergence pattern: (i) an initial uniform phase, (ii) a sharp-convergence phase, (iii) a sharp-divergence phase, and (iv) a slow-reconvergence phase. Further, we observe that larger models reconverge faster in later training stages, while smaller models never actually reconverge; these results suggest that a certain model size may be necessary to learn stable distributions. Restricting our analysis to specific token frequencies or part-of-speech (PoS) tags further reveals that convergence is uneven across linguistic categories: frequent tokens and function words converge faster and more reliably than their counterparts (infrequent tokens and content words). Overall, our findings highlight factors that influence the stability of the learned distributions in model training.
Using Information Theory to Characterize Prosodic Typology: The Case of Tone, Pitch-Accent and Stress-Accent
May 12, 2025This paper argues that the relationship between lexical identity and prosody -- one well-studied parameter of linguistic variation -- can be characterized using information theory. We predict that languages that use prosody to make lexical distinctions should exhibit a higher mutual information between word identity and prosody, compared to languages that don't. We test this hypothesis in the domain of pitch, which is used to make lexical distinctions in tonal languages, like Cantonese. We use a dataset of speakers reading sentences aloud in ten languages across five language families to estimate the mutual information between the text and their pitch curves. We find that, across languages, pitch curves display similar amounts of entropy. However, these curves are easier to predict given their associated text in the tonal languages, compared to pitch- and stress-accent languages, and thus the mutual information is higher in these languages, supporting our hypothesis. Our results support perspectives that view linguistic typology as gradient, rather than categorical.
The time scale of redundancy between prosody and linguistic context
Mar 14, 2025In spoken language, speakers transmit information not only using words, but also via a rich array of non-verbal signals, which include prosody -- the auditory features of speech. However, previous studies have shown that prosodic features exhibit significant redundancy with both past and future words. Here, we examine the time scale of this relationship: How many words in the past (or future) contribute to predicting prosody? We find that this scale differs for past and future words. Prosody's redundancy with past words extends across approximately 3-8 words, whereas redundancy with future words is limited to just 1-2 words. These findings indicate that the prosody-future relationship reflects local word dependencies or short-scale processes such as next word prediction, while the prosody-past relationship unfolds over a longer time scale. The latter suggests that prosody serves to emphasize earlier information that may be challenging for listeners to process given limited cognitive resources in real-time communication. Our results highlight the role of prosody in shaping efficient communication.