 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe time scale of redundancy between prosody and linguistic context
Mar 14, 2025In spoken language, speakers transmit information not only using words, but also via a rich array of non-verbal signals, which include prosody -- the auditory features of speech. However, previous studies have shown that prosodic features exhibit significant redundancy with both past and future words. Here, we examine the time scale of this relationship: How many words in the past (or future) contribute to predicting prosody? We find that this scale differs for past and future words. Prosody's redundancy with past words extends across approximately 3-8 words, whereas redundancy with future words is limited to just 1-2 words. These findings indicate that the prosody-future relationship reflects local word dependencies or short-scale processes such as next word prediction, while the prosody-past relationship unfolds over a longer time scale. The latter suggests that prosody serves to emphasize earlier information that may be challenging for listeners to process given limited cognitive resources in real-time communication. Our results highlight the role of prosody in shaping efficient communication.
WhisBERT: Multimodal Text-Audio Language Modeling on 100M Words
Dec 07, 2023

Training on multiple modalities of input can augment the capabilities of a language model. Here, we ask whether such a training regime can improve the quality and efficiency of these systems as well. We focus on text--audio and introduce Whisbert, which is inspired by the text--image approach of FLAVA (Singh et al., 2022). In accordance with Babylm guidelines (Warstadt et al., 2023), we pretrain Whisbert on a dataset comprising only 100 million words plus their corresponding speech from the word-aligned version of the People's Speech dataset (Galvez et al., 2021). To assess the impact of multimodality, we compare versions of the model that are trained on text only and on both audio and text simultaneously. We find that while Whisbert is able to perform well on multimodal masked modeling and surpasses the Babylm baselines in most benchmark tasks, it struggles to optimize its complex objective and outperform its text-only Whisbert baseline.
Quantifying the redundancy between prosody and text
Nov 28, 2023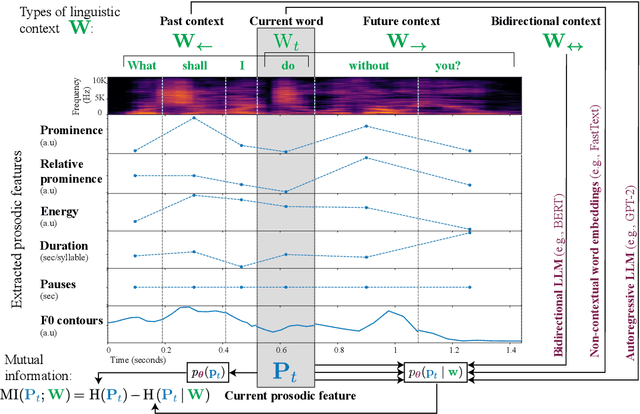
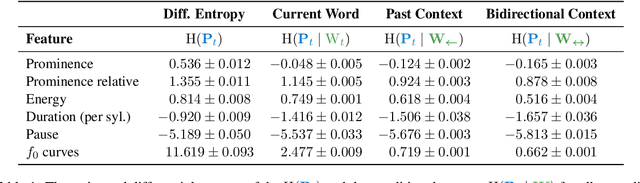
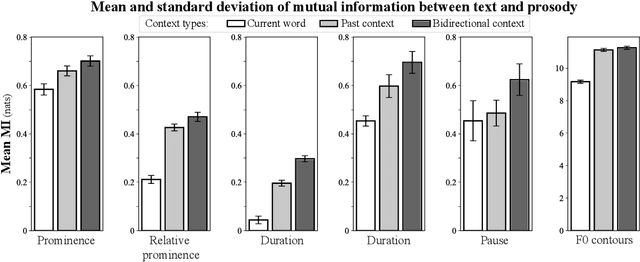
Prosody -- the suprasegmental component of speech, including pitch, loudness, and tempo -- carries critical aspects of meaning. However, the relationship between the information conveyed by prosody vs. by the words themselves remains poorly understood. We use large language models (LLMs) to estimate how much information is redundant between prosody and the words themselves. Using a large spoken corpus of English audiobooks, we extract prosodic features aligned to individual words and test how well they can be predicted from LLM embeddings, compared to non-contextual word embeddings. We find a high degree of redundancy between the information carried by the words and prosodic information across several prosodic features, including intensity, duration, pauses, and pitch contours. Furthermore, a word's prosodic information is redundant with both the word itself and the context preceding as well as following it. Still, we observe that prosodic features can not be fully predicted from text, suggesting that prosody carries information above and beyond the words. Along with this paper, we release a general-purpose data processing pipeline for quantifying the relationship between linguistic information and extra-linguistic features.
FABRIC: Personalizing Diffusion Models with Iterative Feedback
Jul 19, 2023In an era where visual content generation is increasingly driven by machine learning, the integration of human feedback into generative models presents significant opportunities for enhancing user experience and output quality. This study explores strategies for incorporating iterative human feedback into the generative process of diffusion-based text-to-image models. We propose FABRIC, a training-free approach applicable to a wide range of popular diffusion models, which exploits the self-attention layer present in the most widely used architectures to condition the diffusion process on a set of feedback images. To ensure a rigorous assessment of our approach, we introduce a comprehensive evaluation methodology, offering a robust mechanism to quantify the performance of generative visual models that integrate human feedback. We show that generation results improve over multiple rounds of iterative feedback through exhaustive analysis, implicitly optimizing arbitrary user preferences. The potential applications of these findings extend to fields such as personalized content creation and customization.
A Deep Learning Approach for the Segmentation of Electroencephalography Data in Eye Tracking Applications
Jun 17, 2022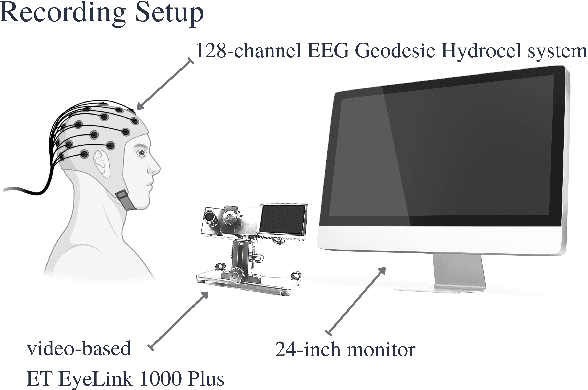
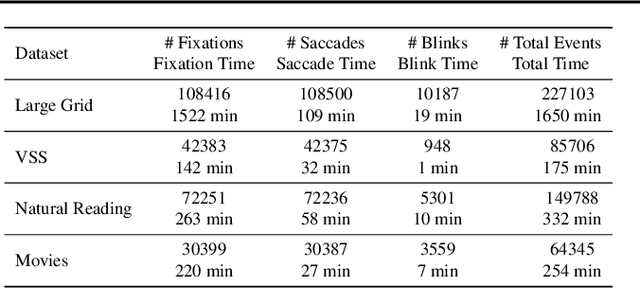
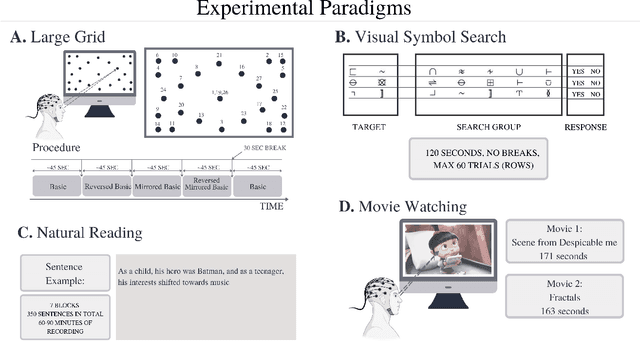
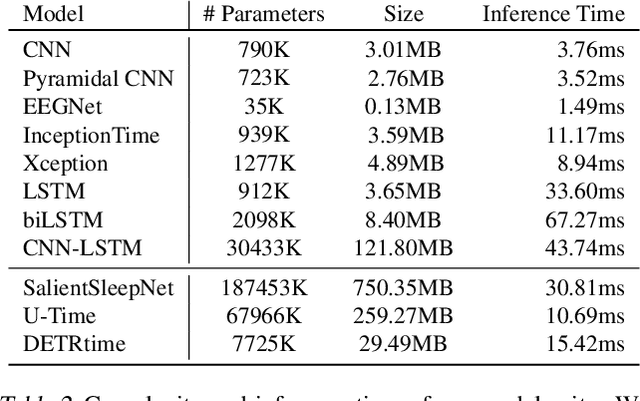
The collection of eye gaze information provides a window into many critical aspects of human cognition, health and behaviour. Additionally, many neuroscientific studies complement the behavioural information gained from eye tracking with the high temporal resolution and neurophysiological markers provided by electroencephalography (EEG). One of the essential eye-tracking software processing steps is the segmentation of the continuous data stream into events relevant to eye-tracking applications, such as saccades, fixations, and blinks. Here, we introduce DETRtime, a novel framework for time-series segmentation that creates ocular event detectors that do not require additionally recorded eye-tracking modality and rely solely on EEG data. Our end-to-end deep learning-based framework brings recent advances in Computer Vision to the forefront of the times series segmentation of EEG data. DETRtime achieves state-of-the-art performance in ocular event detection across diverse eye-tracking experiment paradigms. In addition to that, we provide evidence that our model generalizes well in the task of EEG sleep stage segmentation.
EEGEyeNet: a Simultaneous Electroencephalography and Eye-tracking Dataset and Benchmark for Eye Movement Prediction
Nov 10, 2021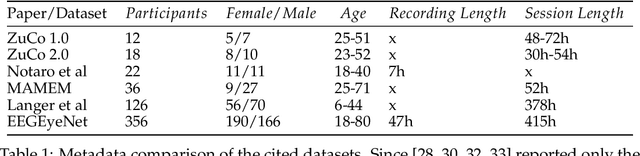
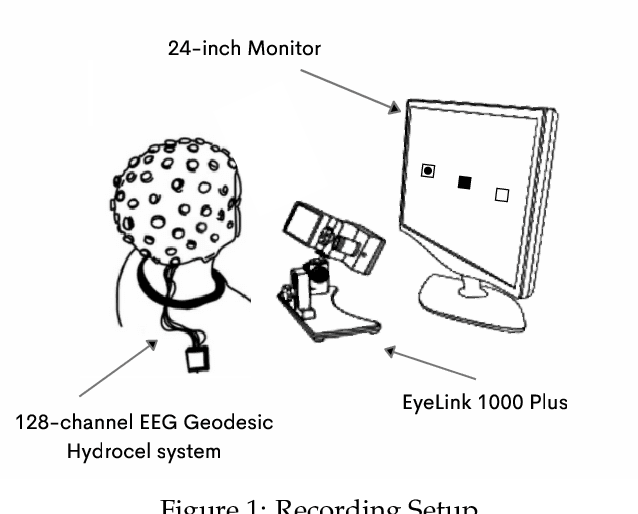
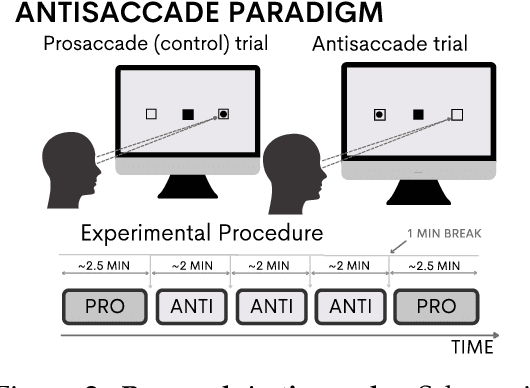
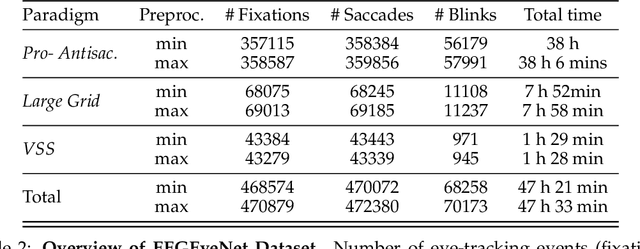
We present a new dataset and benchmark with the goal of advancing research in the intersection of brain activities and eye movements. Our dataset, EEGEyeNet, consists of simultaneous Electroencephalography (EEG) and Eye-tracking (ET) recordings from 356 different subjects collected from three different experimental paradigms. Using this dataset, we also propose a benchmark to evaluate gaze prediction from EEG measurements. The benchmark consists of three tasks with an increasing level of difficulty: left-right, angle-amplitude and absolute position. We run extensive experiments on this benchmark in order to provide solid baselines, both based on classical machine learning models and on large neural networks. We release our complete code and data and provide a simple and easy-to-use interface to evaluate new methods.