 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Alignment Between Language Model Layers and Human Sentence Processing
Apr 20, 2026A recent study (Kuribayashi et al., 2025) has shown that human sentence processing behavior, typically measured on syntactically unchallenging constructions, can be effectively modeled using surprisal from early layers of large language models (LLMs). This raises the question of whether such advantages of internal layers extend to more syntactically challenging constructions, where surprisal has been reported to underestimate human cognitive effort. In this paper, we begin by exploring internal layers that better estimate human cognitive effort observed in syntactic ambiguity processing in English. Our experiments show that, in contrast to naturalistic reading, later layers better estimate such a cognitive effort, but still underestimate the human data. This dual alignment sheds light on different modes of sentence processing in humans and LMs: naturalistic reading employs a somewhat weak prediction akin to earlier layers of LMs, while syntactically challenging processing requires more fully-contextualized representations, better modeled by later layers of LMs. Motivated by these findings, we also explore several probability-update measures using shallow and deep layers of LMs, showing a complementary advantage to single-layer's surprisal in reading time modeling.
BabyLM Turns 4 and Goes Multilingual: Call for Papers for the 2026 BabyLM Workshop
Feb 24, 2026The goal of the BabyLM is to stimulate new research connections between cognitive modeling and language model pretraining. We invite contributions in this vein to the BabyLM Workshop, which will also include the 4th iteration of the BabyLM Challenge. As in previous years, the challenge features two ``standard'' tracks (Strict and Strict-Small), in which participants must train language models on under 100M or 10M words of data, respectively. This year, we move beyond our previous English-only pretraining datasets with a new Multilingual track, focusing on English, Dutch, and Chinese. For the workshop, we call for papers related to the overall theme of BabyLM, which includes training efficiency, small-scale training datasets, cognitive modeling, model evaluation, and architecture innovation.
What Do Prosody and Text Convey? Characterizing How Meaningful Information is Distributed Across Multiple Channels
Dec 18, 2025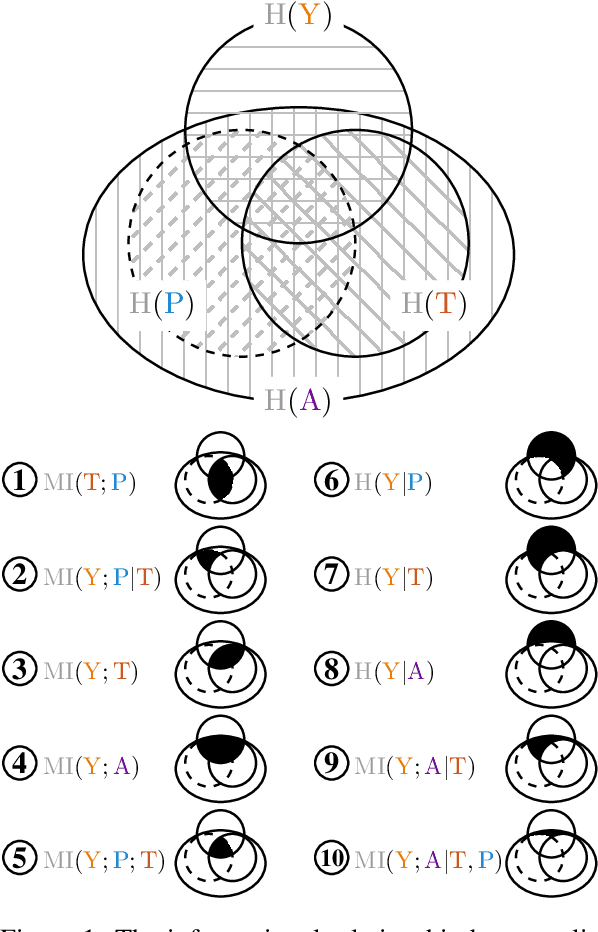
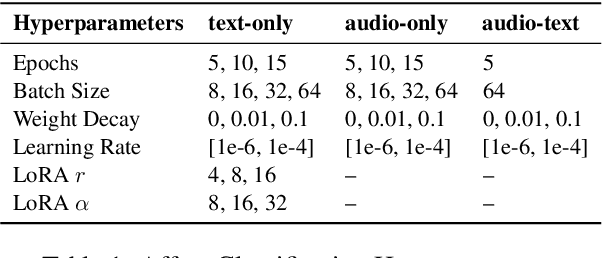
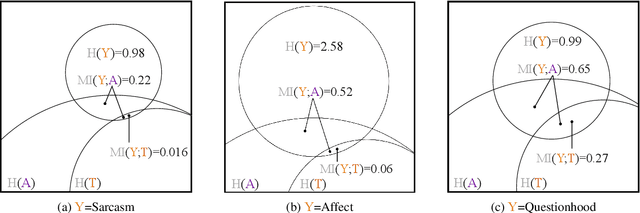
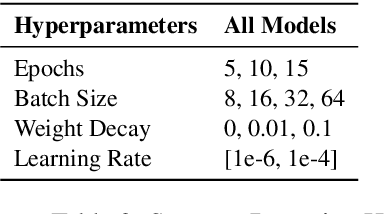
Prosody -- the melody of speech -- conveys critical information often not captured by the words or text of a message. In this paper, we propose an information-theoretic approach to quantify how much information is expressed by prosody alone and not by text, and crucially, what that information is about. Our approach applies large speech and language models to estimate the mutual information between a particular dimension of an utterance's meaning (e.g., its emotion) and any of its communication channels (e.g., audio or text). We then use this approach to quantify how much information is conveyed by audio and text about sarcasm, emotion, and questionhood, using speech from television and podcasts. We find that for sarcasm and emotion the audio channel -- and by implication the prosodic channel -- transmits over an order of magnitude more information about these features than the text channel alone, at least when long-term context beyond the current sentence is unavailable. For questionhood, prosody provides comparatively less additional information. We conclude by outlining a program applying our approach to more dimensions of meaning, communication channels, and languages.
The Harmonic Structure of Information Contours
Jun 04, 2025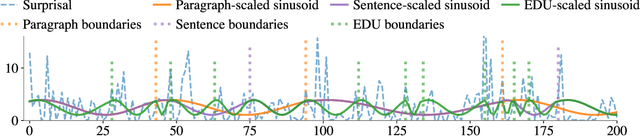
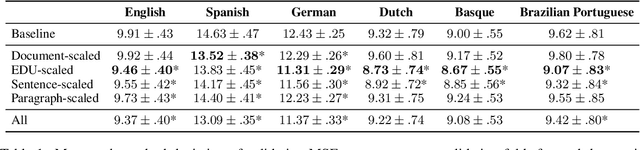
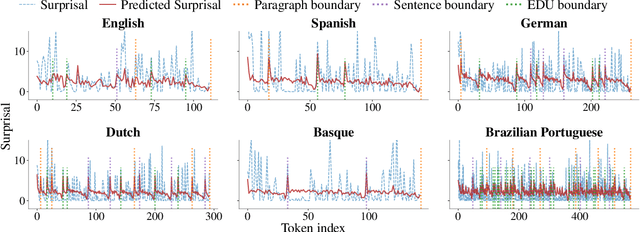
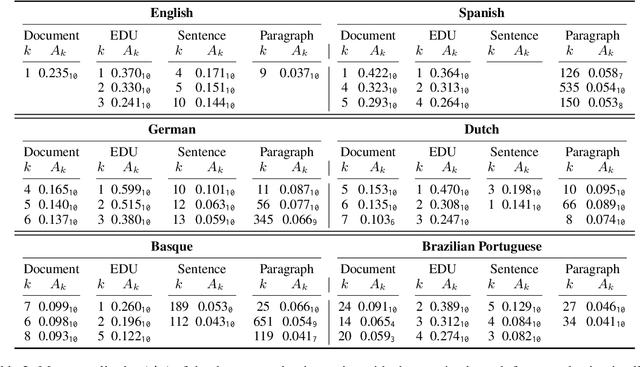
The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Using Information Theory to Characterize Prosodic Typology: The Case of Tone, Pitch-Accent and Stress-Accent
May 12, 2025This paper argues that the relationship between lexical identity and prosody -- one well-studied parameter of linguistic variation -- can be characterized using information theory. We predict that languages that use prosody to make lexical distinctions should exhibit a higher mutual information between word identity and prosody, compared to languages that don't. We test this hypothesis in the domain of pitch, which is used to make lexical distinctions in tonal languages, like Cantonese. We use a dataset of speakers reading sentences aloud in ten languages across five language families to estimate the mutual information between the text and their pitch curves. We find that, across languages, pitch curves display similar amounts of entropy. However, these curves are easier to predict given their associated text in the tonal languages, compared to pitch- and stress-accent languages, and thus the mutual information is higher in these languages, supporting our hypothesis. Our results support perspectives that view linguistic typology as gradient, rather than categorical.
Towards Developmentally Plausible Rewards: Communicative Success as a Learning Signal for Interactive Language Models
May 09, 2025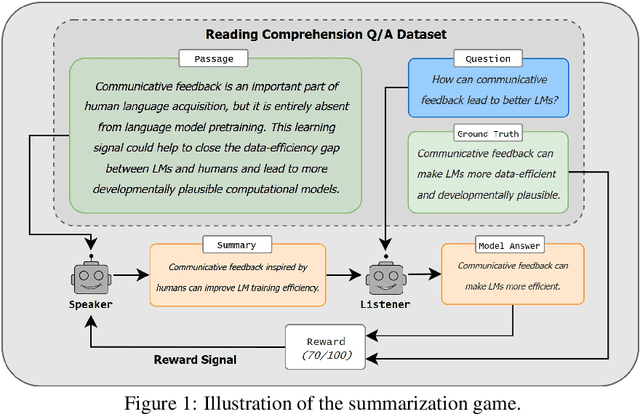

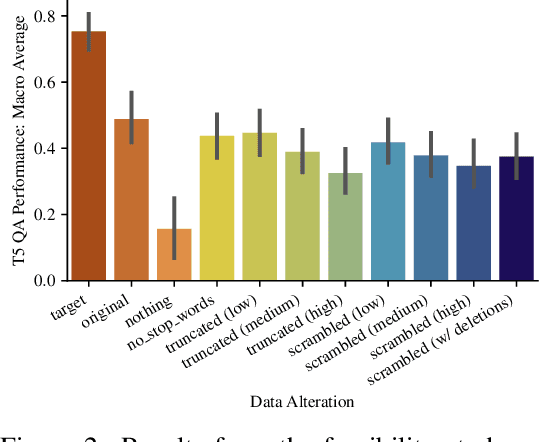
We propose a method for training language models in an interactive setting inspired by child language acquisition. In our setting, a speaker attempts to communicate some information to a listener in a single-turn dialogue and receives a reward if communicative success is achieved. Unlike earlier related work using image--caption data for interactive reference games, we operationalize communicative success in a more abstract language-only question--answering setting. First, we present a feasibility study demonstrating that our reward provides an indirect signal about grammaticality. Second, we conduct experiments using reinforcement learning to fine-tune language models. We observe that cognitively plausible constraints on the communication channel lead to interpretable changes in speaker behavior. However, we do not yet see improvements on linguistic evaluations from our training regime. We outline potential modifications to the task design and training configuration that could better position future work to use our methodology to observe the benefits of interaction on language learning in computational cognitive models.
Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Apr 10, 2025



Children can acquire language from less than 100 million words of input. Large language models are far less data-efficient: they typically require 3 or 4 orders of magnitude more data and still do not perform as well as humans on many evaluations. These intensive resource demands limit the ability of researchers to train new models and use existing models as developmentally plausible cognitive models. The BabyLM Challenge is a communal effort in which participants compete to optimize language model training on a fixed data budget. Submissions are compared on various evaluation tasks targeting grammatical ability, downstream task performance, and generalization. Participants can submit to up to three tracks with progressively looser data restrictions. From over 30 submissions, we extract concrete recommendations on how best to train data-efficient language models, and on where future efforts should (and perhaps should not) focus. The winning submissions using the LTG-BERT architecture (Samuel et al., 2023) outperformed models trained on trillions of words. Other submissions achieved strong results through training on shorter input sequences or training a student model on a pretrained teacher. Curriculum learning attempts, which accounted for a large number of submissions, were largely unsuccessful, though some showed modest improvements.
* Published in Proceedings of BabyLM. Please cite the published version on ACL anthology: http://aclanthology.org/2023.conll-babylm.1/
The time scale of redundancy between prosody and linguistic context
Mar 14, 2025In spoken language, speakers transmit information not only using words, but also via a rich array of non-verbal signals, which include prosody -- the auditory features of speech. However, previous studies have shown that prosodic features exhibit significant redundancy with both past and future words. Here, we examine the time scale of this relationship: How many words in the past (or future) contribute to predicting prosody? We find that this scale differs for past and future words. Prosody's redundancy with past words extends across approximately 3-8 words, whereas redundancy with future words is limited to just 1-2 words. These findings indicate that the prosody-future relationship reflects local word dependencies or short-scale processes such as next word prediction, while the prosody-past relationship unfolds over a longer time scale. The latter suggests that prosody serves to emphasize earlier information that may be challenging for listeners to process given limited cognitive resources in real-time communication. Our results highlight the role of prosody in shaping efficient communication.
Can Language Models Learn Typologically Implausible Languages?
Feb 17, 2025Grammatical features across human languages show intriguing correlations often attributed to learning biases in humans. However, empirical evidence has been limited to experiments with highly simplified artificial languages, and whether these correlations arise from domain-general or language-specific biases remains a matter of debate. Language models (LMs) provide an opportunity to study artificial language learning at a large scale and with a high degree of naturalism. In this paper, we begin with an in-depth discussion of how LMs allow us to better determine the role of domain-general learning biases in language universals. We then assess learnability differences for LMs resulting from typologically plausible and implausible languages closely following the word-order universals identified by linguistic typologists. We conduct a symmetrical cross-lingual study training and testing LMs on an array of highly naturalistic but counterfactual versions of the English (head-initial) and Japanese (head-final) languages. Compared to similar work, our datasets are more naturalistic and fall closer to the boundary of plausibility. Our experiments show that these LMs are often slower to learn these subtly implausible languages, while ultimately achieving similar performance on some metrics regardless of typological plausibility. These findings lend credence to the conclusion that LMs do show some typologically-aligned learning preferences, and that the typological patterns may result from, at least to some degree, domain-general learning biases.
A Distributional Perspective on Word Learning in Neural Language Models
Feb 09, 2025Language models (LMs) are increasingly being studied as models of human language learners. Due to the nascency of the field, it is not well-established whether LMs exhibit similar learning dynamics to humans, and there are few direct comparisons between learning trajectories in humans and models. Word learning trajectories for children are relatively well-documented, and recent work has tried to extend these investigations to language models. However, there are no widely agreed-upon metrics for word learning in language models. We take a distributional approach to this problem, defining lexical knowledge in terms of properties of the learned distribution for a target word. We argue that distributional signatures studied in prior work fail to capture key distributional information. Thus, we propose an array of signatures that improve on earlier approaches by capturing knowledge of both where the target word can and cannot occur as well as gradient preferences about the word's appropriateness. We obtain learning trajectories for a selection of small language models we train from scratch, study the relationship between different distributional signatures, compare how well they align with human word learning trajectories and interpretable lexical features, and address basic methodological questions about estimating these distributional signatures. Our metrics largely capture complementary information, suggesting that it is important not to rely on a single metric. However, across all metrics, language models' learning trajectories fail to correlate with those of children.