 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Harmonic Structure of Information Contours
Jun 04, 2025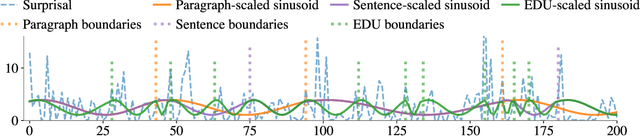
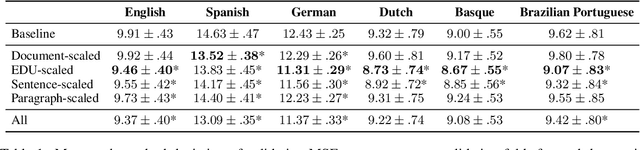
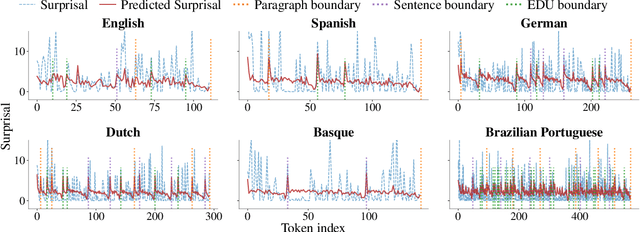
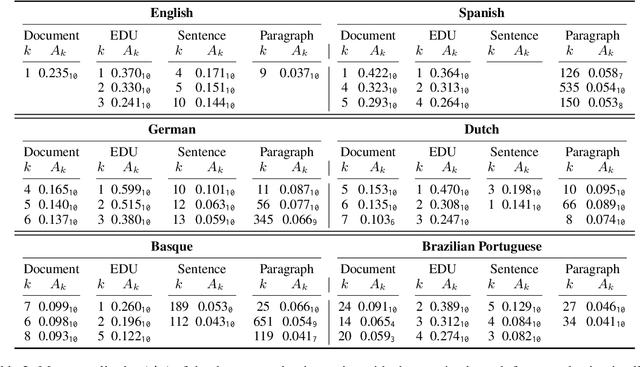
The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Reverse-Engineering the Reader
Oct 16, 2024Numerous previous studies have sought to determine to what extent language models, pretrained on natural language text, can serve as useful models of human cognition. In this paper, we are interested in the opposite question: whether we can directly optimize a language model to be a useful cognitive model by aligning it to human psychometric data. To achieve this, we introduce a novel alignment technique in which we fine-tune a language model to implicitly optimize the parameters of a linear regressor that directly predicts humans' reading times of in-context linguistic units, e.g., phonemes, morphemes, or words, using surprisal estimates derived from the language model. Using words as a test case, we evaluate our technique across multiple model sizes and datasets and find that it improves language models' psychometric predictive power. However, we find an inverse relationship between psychometric power and a model's performance on downstream NLP tasks as well as its perplexity on held-out test data. While this latter trend has been observed before (Oh et al., 2022; Shain et al., 2024), we are the first to induce it by manipulating a model's alignment to psychometric data.
Reading Task Classification Using EEG and Eye-Tracking Data
Dec 12, 2021
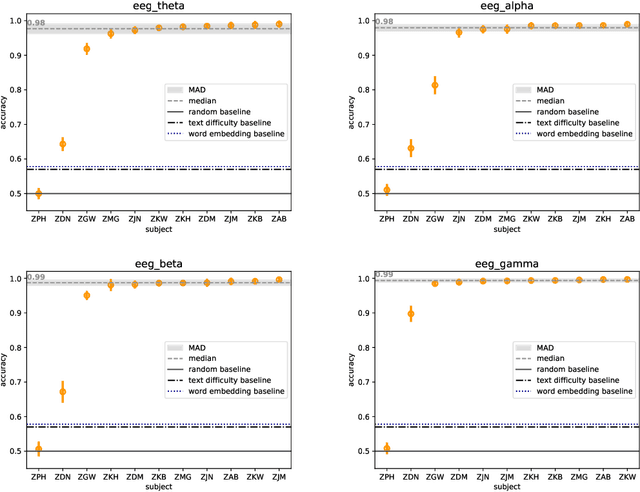
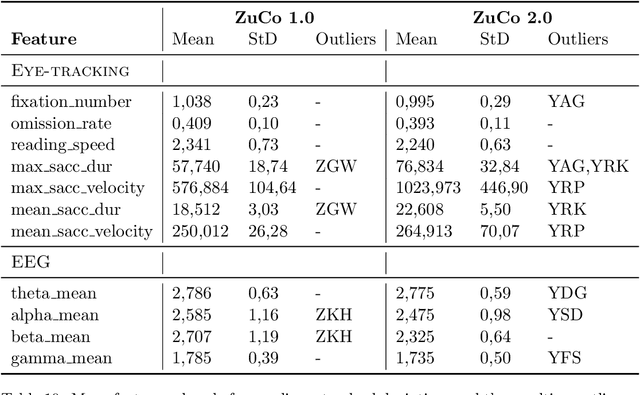
The Zurich Cognitive Language Processing Corpus (ZuCo) provides eye-tracking and EEG signals from two reading paradigms, normal reading and task-specific reading. We analyze whether machine learning methods are able to classify these two tasks using eye-tracking and EEG features. We implement models with aggregated sentence-level features as well as fine-grained word-level features. We test the models in within-subject and cross-subject evaluation scenarios. All models are tested on the ZuCo 1.0 and ZuCo 2.0 data subsets, which are characterized by differing recording procedures and thus allow for different levels of generalizability. Finally, we provide a series of control experiments to analyze the results in more detail.
Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation
Jun 16, 2021



Policy gradient algorithms have found wide adoption in NLP, but have recently become subject to criticism, doubting their suitability for NMT. Choshen et al. (2020) identify multiple weaknesses and suspect that their success is determined by the shape of output distributions rather than the reward. In this paper, we revisit these claims and study them under a wider range of configurations. Our experiments on in-domain and cross-domain adaptation reveal the importance of exploration and reward scaling, and provide empirical counter-evidence to these claims.