 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Limits of Large Language Models in Multilingual Legal Reasoning
Sep 26, 2025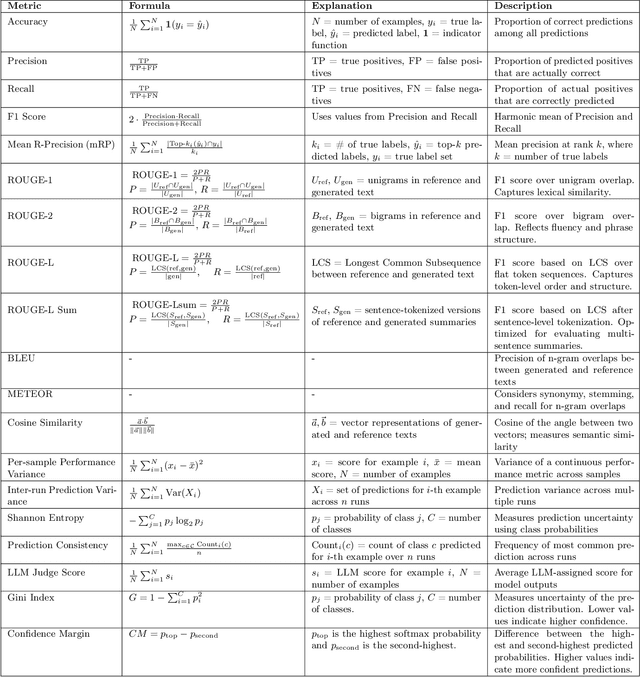
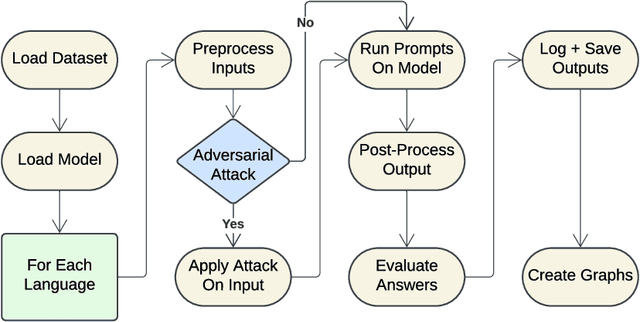

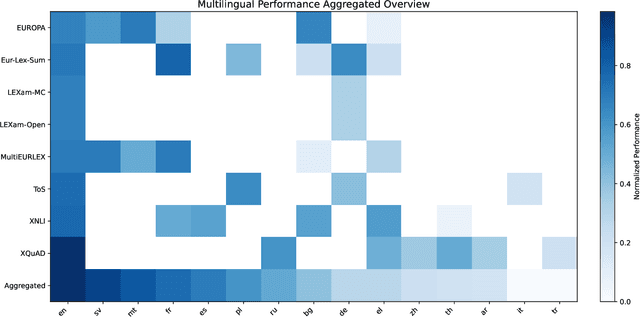
In an era dominated by Large Language Models (LLMs), understanding their capabilities and limitations, especially in high-stakes fields like law, is crucial. While LLMs such as Meta's LLaMA, OpenAI's ChatGPT, Google's Gemini, DeepSeek, and other emerging models are increasingly integrated into legal workflows, their performance in multilingual, jurisdictionally diverse, and adversarial contexts remains insufficiently explored. This work evaluates LLaMA and Gemini on multilingual legal and non-legal benchmarks, and assesses their adversarial robustness in legal tasks through character and word-level perturbations. We use an LLM-as-a-Judge approach for human-aligned evaluation. We moreover present an open-source, modular evaluation pipeline designed to support multilingual, task-diverse benchmarking of any combination of LLMs and datasets, with a particular focus on legal tasks, including classification, summarization, open questions, and general reasoning. Our findings confirm that legal tasks pose significant challenges for LLMs with accuracies often below 50% on legal reasoning benchmarks such as LEXam, compared to over 70% on general-purpose tasks like XNLI. In addition, while English generally yields more stable results, it does not always lead to higher accuracy. Prompt sensitivity and adversarial vulnerability is also shown to persist across languages. Finally, a correlation is found between the performance of a language and its syntactic similarity to English. We also observe that LLaMA is weaker than Gemini, with the latter showing an average advantage of about 24 percentage points across the same task. Despite improvements in newer LLMs, challenges remain in deploying them reliably for critical, multilingual legal applications.
Evaluating Webcam-based Gaze Data as an Alternative for Human Rationale Annotations
Feb 29, 2024Rationales in the form of manually annotated input spans usually serve as ground truth when evaluating explainability methods in NLP. They are, however, time-consuming and often biased by the annotation process. In this paper, we debate whether human gaze, in the form of webcam-based eye-tracking recordings, poses a valid alternative when evaluating importance scores. We evaluate the additional information provided by gaze data, such as total reading times, gaze entropy, and decoding accuracy with respect to human rationale annotations. We compare WebQAmGaze, a multilingual dataset for information-seeking QA, with attention and explainability-based importance scores for 4 different multilingual Transformer-based language models (mBERT, distil-mBERT, XLMR, and XLMR-L) and 3 languages (English, Spanish, and German). Our pipeline can easily be applied to other tasks and languages. Our findings suggest that gaze data offers valuable linguistic insights that could be leveraged to infer task difficulty and further show a comparable ranking of explainability methods to that of human rationales.
Longer Fixations, More Computation: Gaze-Guided Recurrent Neural Networks
Oct 31, 2023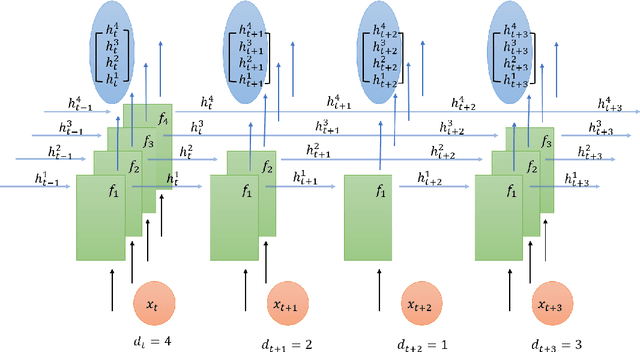
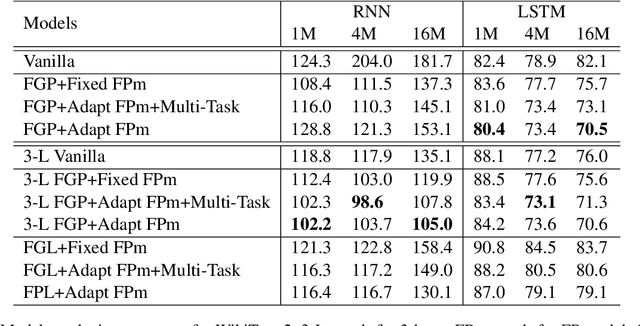
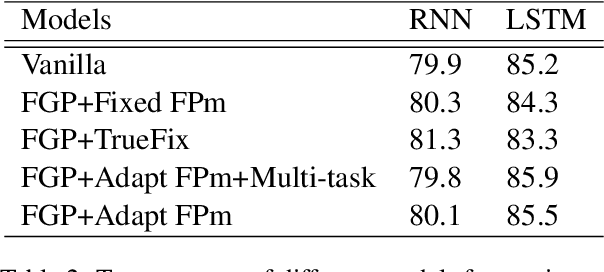

Humans read texts at a varying pace, while machine learning models treat each token in the same way in terms of a computational process. Therefore, we ask, does it help to make models act more like humans? In this paper, we convert this intuition into a set of novel models with fixation-guided parallel RNNs or layers and conduct various experiments on language modeling and sentiment analysis tasks to test their effectiveness, thus providing empirical validation for this intuition. Our proposed models achieve good performance on the language modeling task, considerably surpassing the baseline model. In addition, we find that, interestingly, the fixation duration predicted by neural networks bears some resemblance to humans' fixation. Without any explicit guidance, the model makes similar choices to humans. We also investigate the reasons for the differences between them, which explain why "model fixations" are often more suitable than human fixations, when used to guide language models.
WebQAmGaze: A Multilingual Webcam Eye-Tracking-While-Reading Dataset
Apr 14, 2023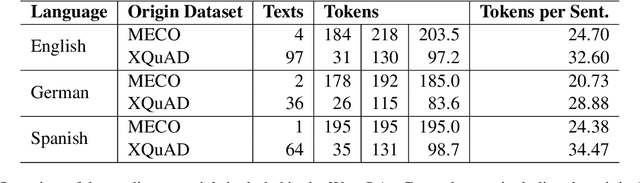
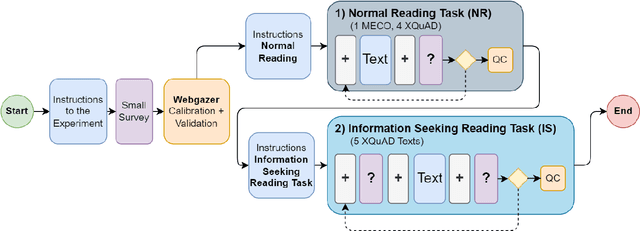
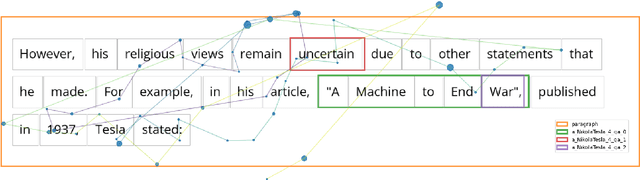
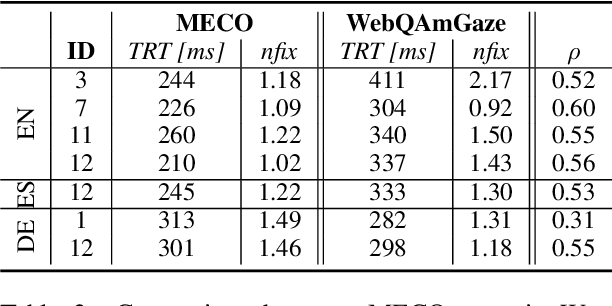
We create WebQAmGaze, a multilingual low-cost eye-tracking-while-reading dataset, designed to support the development of fair and transparent NLP models. WebQAmGaze includes webcam eye-tracking data from 332 participants naturally reading English, Spanish, and German texts. Each participant performs two reading tasks composed of five texts, a normal reading and an information-seeking task. After preprocessing the data, we find that fixations on relevant spans seem to indicate correctness when answering the comprehension questions. Additionally, we perform a comparative analysis of the data collected to high-quality eye-tracking data. The results show a moderate correlation between the features obtained with the webcam-ET compared to those of a commercial ET device. We believe this data can advance webcam-based reading studies and open a way to cheaper and more accessible data collection. WebQAmGaze is useful to learn about the cognitive processes behind question answering (QA) and to apply these insights to computational models of language understanding.
Cross-Lingual Transfer of Cognitive Processing Complexity
Feb 27, 2023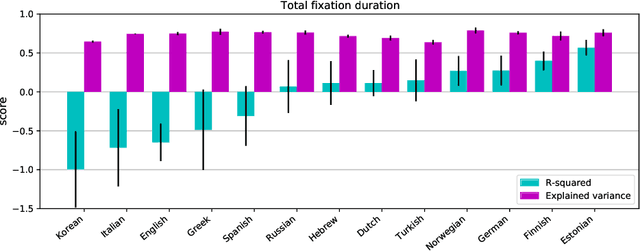
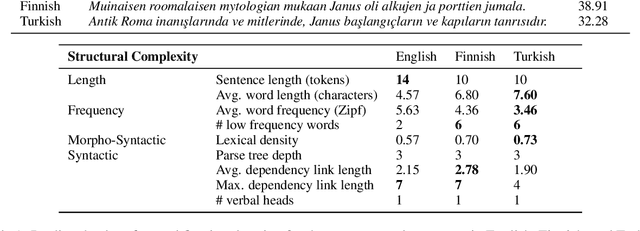
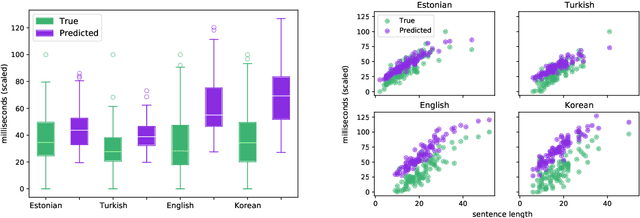
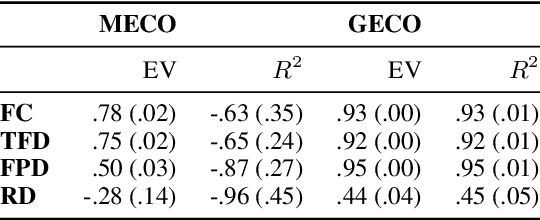
When humans read a text, their eye movements are influenced by the structural complexity of the input sentences. This cognitive phenomenon holds across languages and recent studies indicate that multilingual language models utilize structural similarities between languages to facilitate cross-lingual transfer. We use sentence-level eye-tracking patterns as a cognitive indicator for structural complexity and show that the multilingual model XLM-RoBERTa can successfully predict varied patterns for 13 typologically diverse languages, despite being fine-tuned only on English data. We quantify the sensitivity of the model to structural complexity and distinguish a range of complexity characteristics. Our results indicate that the model develops a meaningful bias towards sentence length but also integrates cross-lingual differences. We conduct a control experiment with randomized word order and find that the model seems to additionally capture more complex structural information.
Synthesizing Human Gaze Feedback for Improved NLP Performance
Feb 11, 2023



Integrating human feedback in models can improve the performance of natural language processing (NLP) models. Feedback can be either explicit (e.g. ranking used in training language models) or implicit (e.g. using human cognitive signals in the form of eyetracking). Prior eye tracking and NLP research reveal that cognitive processes, such as human scanpaths, gleaned from human gaze patterns aid in the understanding and performance of NLP models. However, the collection of real eyetracking data for NLP tasks is challenging due to the requirement of expensive and precise equipment coupled with privacy invasion issues. To address this challenge, we propose ScanTextGAN, a novel model for generating human scanpaths over text. We show that ScanTextGAN-generated scanpaths can approximate meaningful cognitive signals in human gaze patterns. We include synthetically generated scanpaths in four popular NLP tasks spanning six different datasets as proof of concept and show that the models augmented with generated scanpaths improve the performance of all downstream NLP tasks.
Every word counts: A multilingual analysis of individual human alignment with model attention
Oct 05, 2022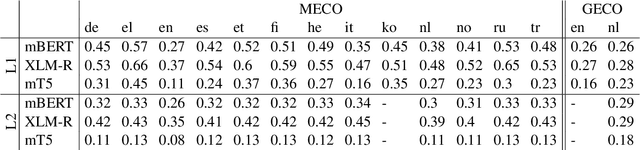
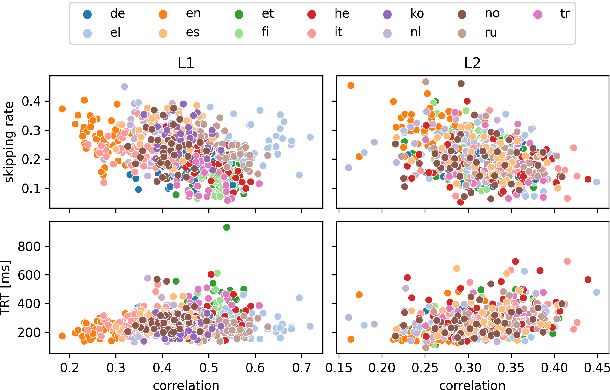
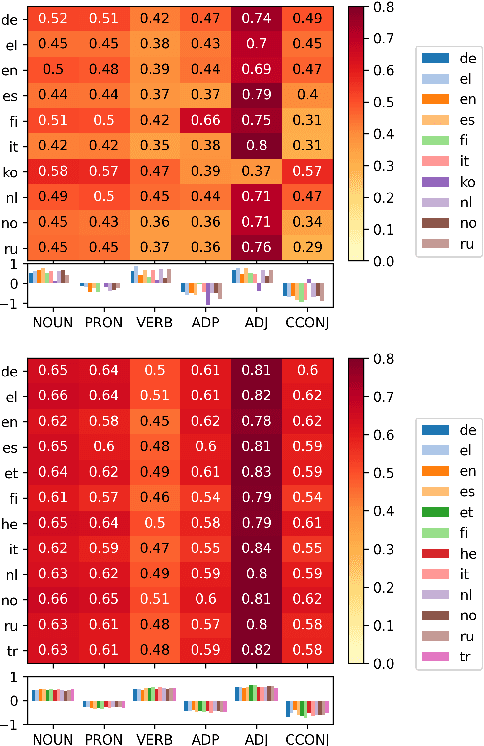
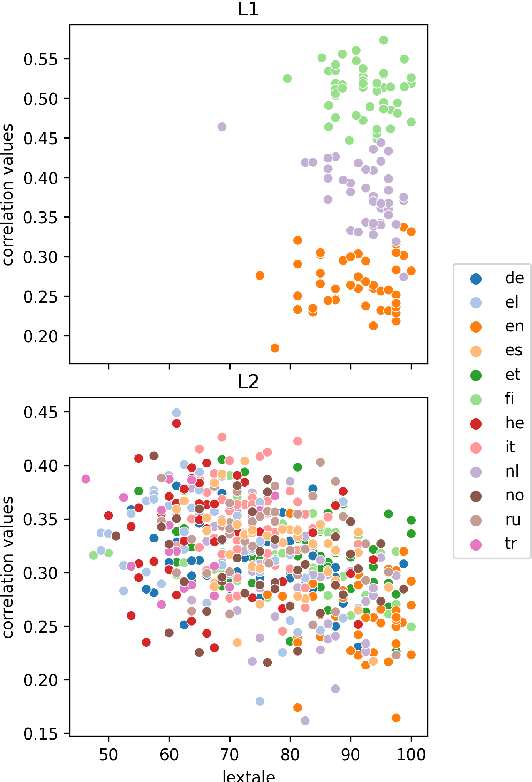
Human fixation patterns have been shown to correlate strongly with Transformer-based attention. Those correlation analyses are usually carried out without taking into account individual differences between participants and are mostly done on monolingual datasets making it difficult to generalise findings. In this paper, we analyse eye-tracking data from speakers of 13 different languages reading both in their native language (L1) and in English as language learners (L2). We find considerable differences between languages but also that individual reading behaviour such as skipping rate, total reading time and vocabulary knowledge (LexTALE) influence the alignment between humans and models to an extent that should be considered in future studies.
The Copenhagen Corpus of Eye Tracking Recordings from Natural Reading of Danish Texts
Apr 28, 2022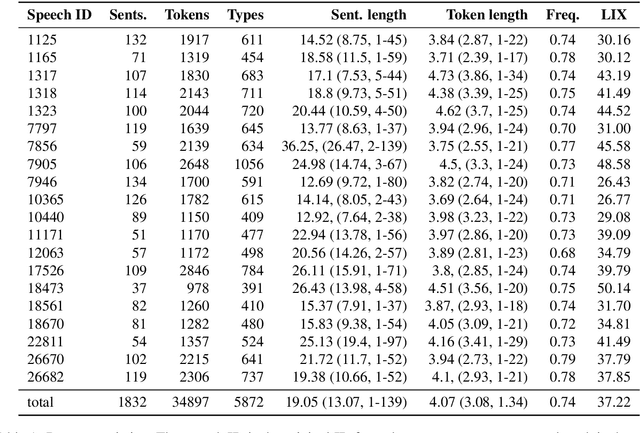
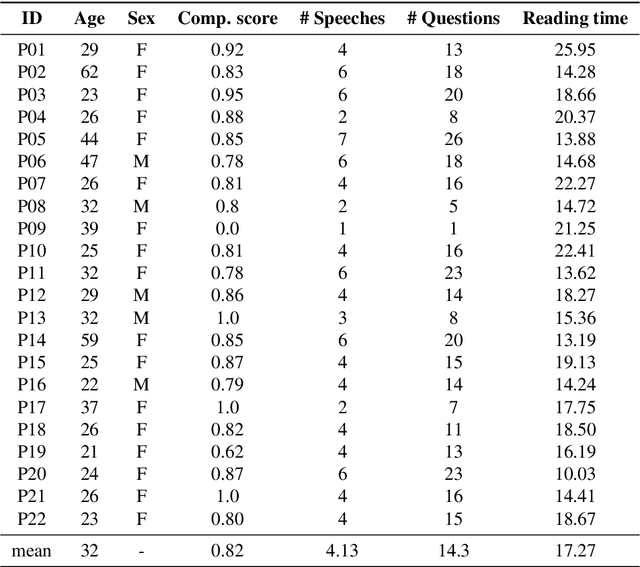
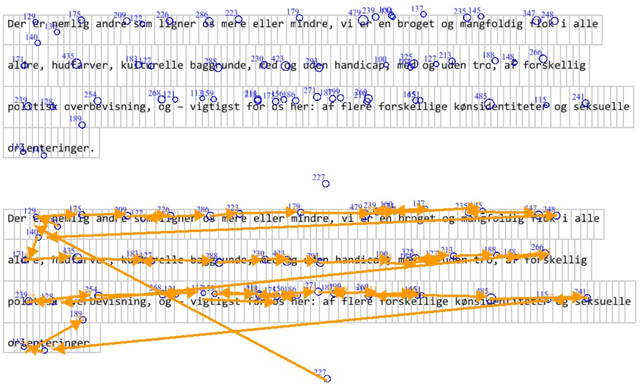
Eye movement recordings from reading are one of the richest signals of human language processing. Corpora of eye movements during reading of contextualized running text is a way of making such records available for natural language processing purposes. Such corpora already exist in some languages. We present CopCo, the Copenhagen Corpus of eye tracking recordings from natural reading of Danish texts. It is the first eye tracking corpus of its kind for the Danish language. CopCo includes 1,832 sentences with 34,897 tokens of Danish text extracted from a collection of speech manuscripts. This first release of the corpus contains eye tracking data from 22 participants. It will be extended continuously with more participants and texts from other genres. We assess the data quality of the recorded eye movements and find that the extracted features are in line with related research. The dataset available here: https://osf.io/ud8s5/.
Dynamic Human Evaluation for Relative Model Comparisons
Dec 15, 2021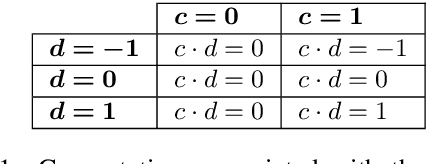
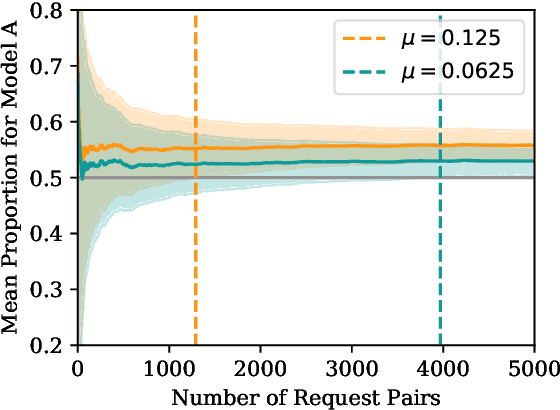
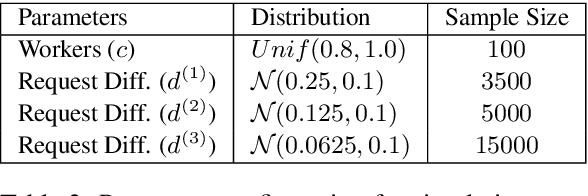
Collecting human judgements is currently the most reliable evaluation method for natural language generation systems. Automatic metrics have reported flaws when applied to measure quality aspects of generated text and have been shown to correlate poorly with human judgements. However, human evaluation is time and cost-intensive, and we lack consensus on designing and conducting human evaluation experiments. Thus there is a need for streamlined approaches for efficient collection of human judgements when evaluating natural language generation systems. Therefore, we present a dynamic approach to measure the required number of human annotations when evaluating generated outputs in relative comparison settings. We propose an agent-based framework of human evaluation to assess multiple labelling strategies and methods to decide the better model in a simulation and a crowdsourcing case study. The main results indicate that a decision about the superior model can be made with high probability across different labelling strategies, where assigning a single random worker per task requires the least overall labelling effort and thus the least cost.
Reading Task Classification Using EEG and Eye-Tracking Data
Dec 12, 2021
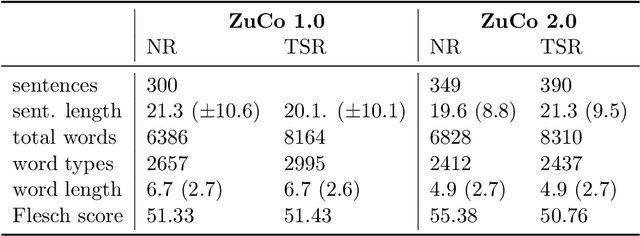
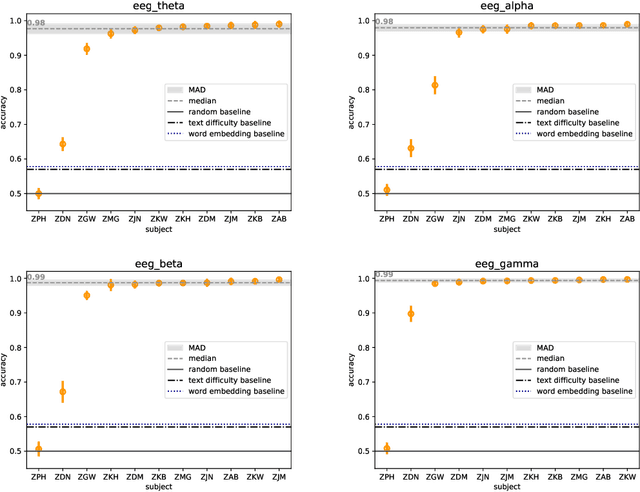
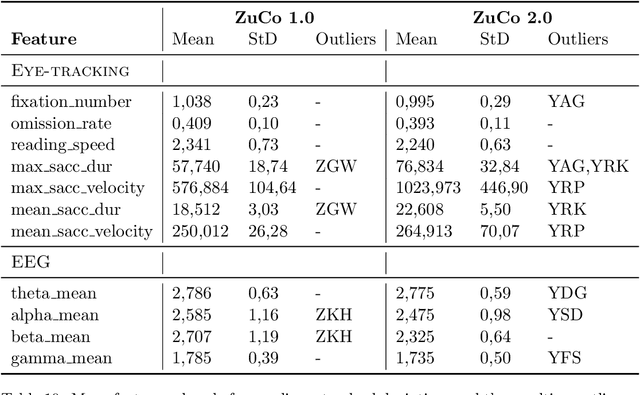
The Zurich Cognitive Language Processing Corpus (ZuCo) provides eye-tracking and EEG signals from two reading paradigms, normal reading and task-specific reading. We analyze whether machine learning methods are able to classify these two tasks using eye-tracking and EEG features. We implement models with aggregated sentence-level features as well as fine-grained word-level features. We test the models in within-subject and cross-subject evaluation scenarios. All models are tested on the ZuCo 1.0 and ZuCo 2.0 data subsets, which are characterized by differing recording procedures and thus allow for different levels of generalizability. Finally, we provide a series of control experiments to analyze the results in more detail.