 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Differences in Persuasive Language in LLM-Generated Text: Uncovering Stereotypical Gender Patterns
Jan 09, 2026Large language models (LLMs) are increasingly used for everyday communication tasks, including drafting interpersonal messages intended to influence and persuade. Prior work has shown that LLMs can successfully persuade humans and amplify persuasive language. It is therefore essential to understand how user instructions affect the generation of persuasive language, and to understand whether the generated persuasive language differs, for example, when targeting different groups. In this work, we propose a framework for evaluating how persuasive language generation is affected by recipient gender, sender intent, or output language. We evaluate 13 LLMs and 16 languages using pairwise prompt instructions. We evaluate model responses on 19 categories of persuasive language using an LLM-as-judge setup grounded in social psychology and communication science. Our results reveal significant gender differences in the persuasive language generated across all models. These patterns reflect biases consistent with gender-stereotypical linguistic tendencies documented in social psychology and sociolinguistics.
Modelling Emotions in Face-to-Face Setting: The Interplay of Eye-Tracking, Personality, and Temporal Dynamics
Mar 18, 2025Accurate emotion recognition is pivotal for nuanced and engaging human-computer interactions, yet remains difficult to achieve, especially in dynamic, conversation-like settings. In this study, we showcase how integrating eye-tracking data, temporal dynamics, and personality traits can substantially enhance the detection of both perceived and felt emotions. Seventy-three participants viewed short, speech-containing videos from the CREMA-D dataset, while being recorded for eye-tracking signals (pupil size, fixation patterns), Big Five personality assessments, and self-reported emotional states. Our neural network models combined these diverse inputs including stimulus emotion labels for contextual cues and yielded marked performance gains compared to the state-of-the-art. Specifically, perceived valence predictions reached a macro F1-score of 0.76, and models incorporating personality traits and stimulus information demonstrated significant improvements in felt emotion accuracy. These results highlight the benefit of unifying physiological, individual and contextual factors to address the subjectivity and complexity of emotional expression. Beyond validating the role of user-specific data in capturing subtle internal states, our findings inform the design of future affective computing and human-agent systems, paving the way for more adaptive and cross-individual emotional intelligence in real-world interactions.
Can Humans Identify Domains?
Apr 02, 2024



Textual domain is a crucial property within the Natural Language Processing (NLP) community due to its effects on downstream model performance. The concept itself is, however, loosely defined and, in practice, refers to any non-typological property, such as genre, topic, medium or style of a document. We investigate the core notion of domains via human proficiency in identifying related intrinsic textual properties, specifically the concepts of genre (communicative purpose) and topic (subject matter). We publish our annotations in *TGeGUM*: A collection of 9.1k sentences from the GUM dataset (Zeldes, 2017) with single sentence and larger context (i.e., prose) annotations for one of 11 genres (source type), and its topic/subtopic as per the Dewey Decimal library classification system (Dewey, 1979), consisting of 10/100 hierarchical topics of increased granularity. Each instance is annotated by three annotators, for a total of 32.7k annotations, allowing us to examine the level of human disagreement and the relative difficulty of each annotation task. With a Fleiss' kappa of at most 0.53 on the sentence level and 0.66 at the prose level, it is evident that despite the ubiquity of domains in NLP, there is little human consensus on how to define them. By training classifiers to perform the same task, we find that this uncertainty also extends to NLP models.
The Copenhagen Corpus of Eye Tracking Recordings from Natural Reading of Danish Texts
Apr 28, 2022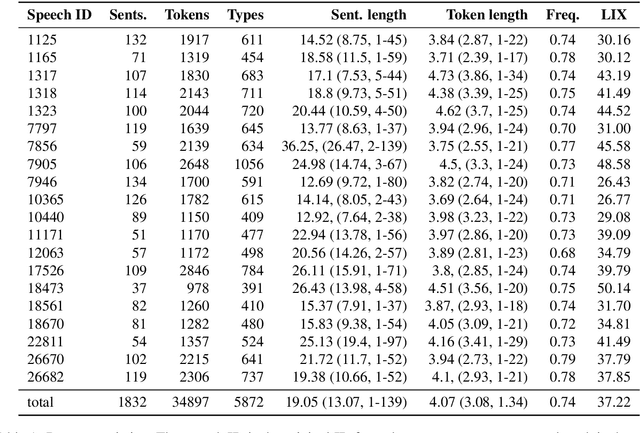
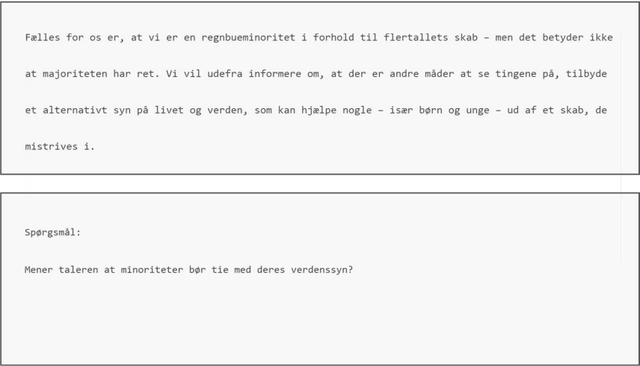
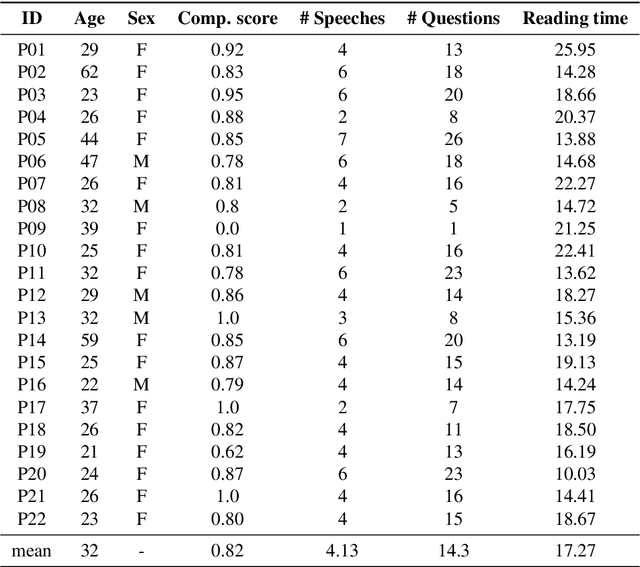
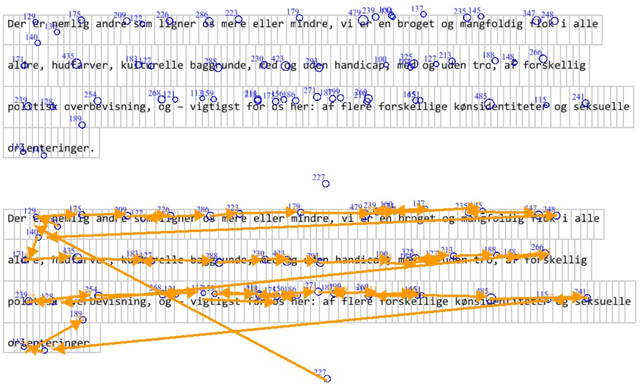
Eye movement recordings from reading are one of the richest signals of human language processing. Corpora of eye movements during reading of contextualized running text is a way of making such records available for natural language processing purposes. Such corpora already exist in some languages. We present CopCo, the Copenhagen Corpus of eye tracking recordings from natural reading of Danish texts. It is the first eye tracking corpus of its kind for the Danish language. CopCo includes 1,832 sentences with 34,897 tokens of Danish text extracted from a collection of speech manuscripts. This first release of the corpus contains eye tracking data from 22 participants. It will be extended continuously with more participants and texts from other genres. We assess the data quality of the recorded eye movements and find that the extracted features are in line with related research. The dataset available here: https://osf.io/ud8s5/.
Decoding EEG Brain Activity for Multi-Modal Natural Language Processing
Feb 17, 2021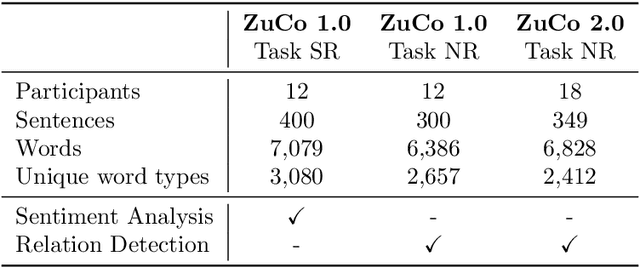
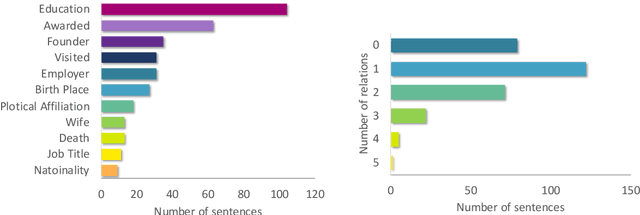
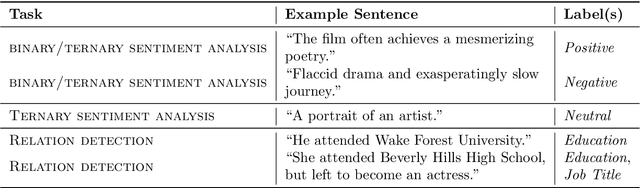
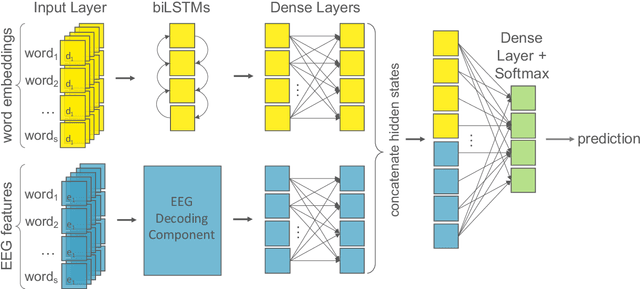
Until recently, human behavioral data from reading has mainly been of interest to researchers to understand human cognition. However, these human language processing signals can also be beneficial in machine learning-based natural language processing tasks. Using EEG brain activity to this purpose is largely unexplored as of yet. In this paper, we present the first large-scale study of systematically analyzing the potential of EEG brain activity data for improving natural language processing tasks, with a special focus on which features of the signal are most beneficial. We present a multi-modal machine learning architecture that learns jointly from textual input as well as from EEG features. We find that filtering the EEG signals into frequency bands is more beneficial than using the broadband signal. Moreover, for a range of word embedding types, EEG data improves binary and ternary sentiment classification and outperforms multiple baselines. For more complex tasks such as relation detection, further research is needed. Finally, EEG data shows to be particularly promising when limited training data is available.
Type B Reflexivization as an Unambiguous Testbed for Multilingual Multi-Task Gender Bias
Sep 28, 2020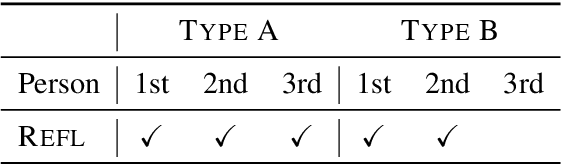
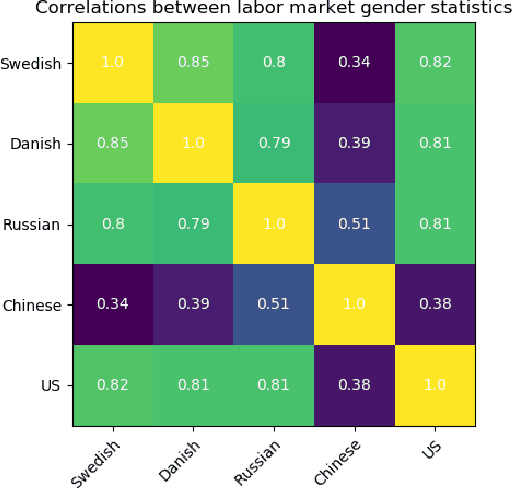


The one-sided focus on English in previous studies of gender bias in NLP misses out on opportunities in other languages: English challenge datasets such as GAP and WinoGender highlight model preferences that are "hallucinatory", e.g., disambiguating gender-ambiguous occurrences of 'doctor' as male doctors. We show that for languages with type B reflexivization, e.g., Swedish and Russian, we can construct multi-task challenge datasets for detecting gender bias that lead to unambiguously wrong model predictions: In these languages, the direct translation of 'the doctor removed his mask' is not ambiguous between a coreferential reading and a disjoint reading. Instead, the coreferential reading requires a non-gendered pronoun, and the gendered, possessive pronouns are anti-reflexive. We present a multilingual, multi-task challenge dataset, which spans four languages and four NLP tasks and focuses only on this phenomenon. We find evidence for gender bias across all task-language combinations and correlate model bias with national labor market statistics.
Human brain activity for machine attention
Jun 09, 2020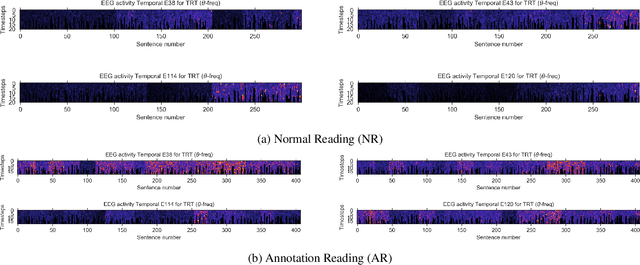

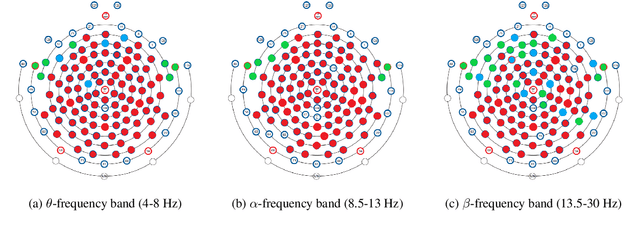
Cognitively inspired NLP leverages human-derived data to teach machines about language processing mechanisms. Recently, neural networks have been augmented with behavioral data to solve a range of NLP tasks spanning syntax and semantics. We are the first to exploit neuroscientific data, namely electroencephalography (EEG), to inform a neural attention model about language processing of the human brain with direct cognitive measures. Part of the challenge in working with EEG is that features are exceptionally rich and need extensive pre-processing to isolate signals specific to text processing. We devise a method for finding such EEG features to supervise machine attention through combining theoretically motivated cropping with random forest tree splits. This method considerably reduces the number of dimensions of the EEG data. We employ the method on a publicly available EEG corpus and demonstrate that the pre-processed EEG features are capable of distinguishing two reading tasks. We apply these features to regularise attention on relation classification and show that EEG is more informative than strong baselines. This improvement, however, is dependent on both the cognitive load of the task and the EEG frequency domain. Hence, informing neural attention models through EEG signals has benefits but requires further investigation to understand which dimensions are most useful across NLP tasks.
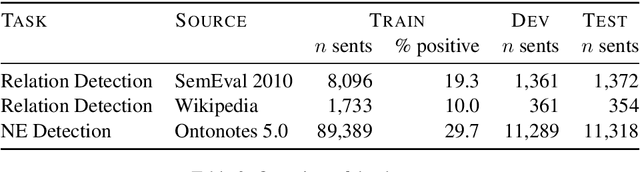
The Sensitivity of Language Models and Humans to Winograd Schema Perturbations
May 07, 2020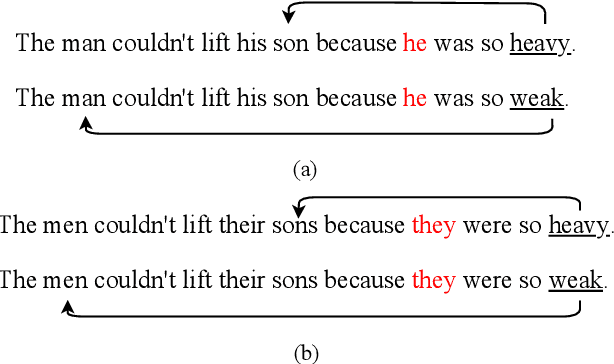

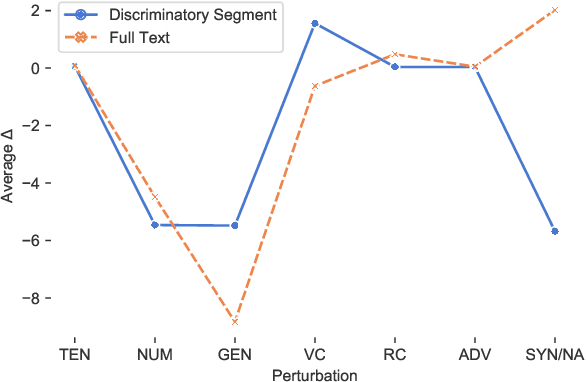
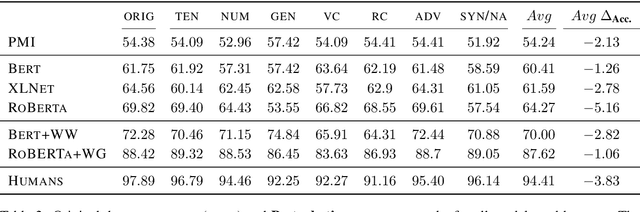
Large-scale pretrained language models are the major driving force behind recent improvements in performance on the Winograd Schema Challenge, a widely employed test of common sense reasoning ability. We show, however, with a new diagnostic dataset, that these models are sensitive to linguistic perturbations of the Winograd examples that minimally affect human understanding. Our results highlight interesting differences between humans and language models: language models are more sensitive to number or gender alternations and synonym replacements than humans, and humans are more stable and consistent in their predictions, maintain a much higher absolute performance, and perform better on non-associative instances than associative ones. Overall, humans are correct more often than out-of-the-box models, and the models are sometimes right for the wrong reasons. Finally, we show that fine-tuning on a large, task-specific dataset can offer a solution to these issues.
Advancing NLP with Cognitive Language Processing Signals
Apr 04, 2019

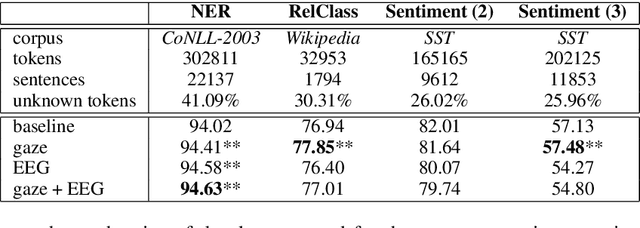

When we read, our brain processes language and generates cognitive processing data such as gaze patterns and brain activity. These signals can be recorded while reading. Cognitive language processing data such as eye-tracking features have shown improvements on single NLP tasks. We analyze whether using such human features can show consistent improvement across tasks and data sources. We present an extensive investigation of the benefits and limitations of using cognitive processing data for NLP. Specifically, we use gaze and EEG features to augment models of named entity recognition, relation classification, and sentiment analysis. These methods significantly outperform the baselines and show the potential and current limitations of employing human language processing data for NLP.