 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Meanings Meet: Investigating the Emergence and Quality of Shared Concept Spaces during Multilingual Language Model Training
Jan 30, 2026Training Large Language Models (LLMs) with high multilingual coverage is becoming increasingly important -- especially when monolingual resources are scarce. Recent studies have found that LLMs process multilingual inputs in shared concept spaces, thought to support generalization and cross-lingual transfer. However, these prior studies often do not use causal methods, lack deeper error analysis or focus on the final model only, leaving open how these spaces emerge during training. We investigate the development of language-agnostic concept spaces during pretraining of EuroLLM through the causal interpretability method of activation patching. We isolate cross-lingual concept representations, then inject them into a translation prompt to investigate how consistently translations can be altered, independently of the language. We find that shared concept spaces emerge early} and continue to refine, but that alignment with them is language-dependent}. Furthermore, in contrast to prior work, our fine-grained manual analysis reveals that some apparent gains in translation quality reflect shifts in behavior -- like selecting senses for polysemous words or translating instead of copying cross-lingual homographs -- rather than improved translation ability. Our findings offer new insight into the training dynamics of cross-lingual alignment and the conditions under which causal interpretability methods offer meaningful insights in multilingual contexts.
Analysing Differences in Persuasive Language in LLM-Generated Text: Uncovering Stereotypical Gender Patterns
Jan 09, 2026Large language models (LLMs) are increasingly used for everyday communication tasks, including drafting interpersonal messages intended to influence and persuade. Prior work has shown that LLMs can successfully persuade humans and amplify persuasive language. It is therefore essential to understand how user instructions affect the generation of persuasive language, and to understand whether the generated persuasive language differs, for example, when targeting different groups. In this work, we propose a framework for evaluating how persuasive language generation is affected by recipient gender, sender intent, or output language. We evaluate 13 LLMs and 16 languages using pairwise prompt instructions. We evaluate model responses on 19 categories of persuasive language using an LLM-as-judge setup grounded in social psychology and communication science. Our results reveal significant gender differences in the persuasive language generated across all models. These patterns reflect biases consistent with gender-stereotypical linguistic tendencies documented in social psychology and sociolinguistics.
DaKultur: Evaluating the Cultural Awareness of Language Models for Danish with Native Speakers
Apr 03, 2025Large Language Models (LLMs) have seen widespread societal adoption. However, while they are able to interact with users in languages beyond English, they have been shown to lack cultural awareness, providing anglocentric or inappropriate responses for underrepresented language communities. To investigate this gap and disentangle linguistic versus cultural proficiency, we conduct the first cultural evaluation study for the mid-resource language of Danish, in which native speakers prompt different models to solve tasks requiring cultural awareness. Our analysis of the resulting 1,038 interactions from 63 demographically diverse participants highlights open challenges to cultural adaptation: Particularly, how currently employed automatically translated data are insufficient to train or measure cultural adaptation, and how training on native-speaker data can more than double response acceptance rates. We release our study data as DaKultur - the first native Danish cultural awareness dataset.
SnakModel: Lessons Learned from Training an Open Danish Large Language Model
Dec 17, 2024



We present SnakModel, a Danish large language model (LLM) based on Llama2-7B, which we continuously pre-train on 13.6B Danish words, and further tune on 3.7M Danish instructions. As best practices for creating LLMs for smaller language communities have yet to be established, we examine the effects of early modeling and training decisions on downstream performance throughout the entire training pipeline, including (1) the creation of a strictly curated corpus of Danish text from diverse sources; (2) the language modeling and instruction-tuning training process itself, including the analysis of intermediate training dynamics, and ablations across different hyperparameters; (3) an evaluation on eight language and culturally-specific tasks. Across these experiments SnakModel achieves the highest overall performance, outperforming multiple contemporary Llama2-7B-based models. By making SnakModel, the majority of our pre-training corpus, and the associated code available under open licenses, we hope to foster further research and development in Danish Natural Language Processing, and establish training guidelines for languages with similar resource constraints.
Can Humans Identify Domains?
Apr 02, 2024



Textual domain is a crucial property within the Natural Language Processing (NLP) community due to its effects on downstream model performance. The concept itself is, however, loosely defined and, in practice, refers to any non-typological property, such as genre, topic, medium or style of a document. We investigate the core notion of domains via human proficiency in identifying related intrinsic textual properties, specifically the concepts of genre (communicative purpose) and topic (subject matter). We publish our annotations in *TGeGUM*: A collection of 9.1k sentences from the GUM dataset (Zeldes, 2017) with single sentence and larger context (i.e., prose) annotations for one of 11 genres (source type), and its topic/subtopic as per the Dewey Decimal library classification system (Dewey, 1979), consisting of 10/100 hierarchical topics of increased granularity. Each instance is annotated by three annotators, for a total of 32.7k annotations, allowing us to examine the level of human disagreement and the relative difficulty of each annotation task. With a Fleiss' kappa of at most 0.53 on the sentence level and 0.66 at the prose level, it is evident that despite the ubiquity of domains in NLP, there is little human consensus on how to define them. By training classifiers to perform the same task, we find that this uncertainty also extends to NLP models.
Subspace Chronicles: How Linguistic Information Emerges, Shifts and Interacts during Language Model Training
Oct 25, 2023Representational spaces learned via language modeling are fundamental to Natural Language Processing (NLP), however there has been limited understanding regarding how and when during training various types of linguistic information emerge and interact. Leveraging a novel information theoretic probing suite, which enables direct comparisons of not just task performance, but their representational subspaces, we analyze nine tasks covering syntax, semantics and reasoning, across 2M pre-training steps and five seeds. We identify critical learning phases across tasks and time, during which subspaces emerge, share information, and later disentangle to specialize. Across these phases, syntactic knowledge is acquired rapidly after 0.5% of full training. Continued performance improvements primarily stem from the acquisition of open-domain knowledge, while semantics and reasoning tasks benefit from later boosts to long-range contextualization and higher specialization. Measuring cross-task similarity further reveals that linguistically related tasks share information throughout training, and do so more during the critical phase of learning than before or after. Our findings have implications for model interpretability, multi-task learning, and learning from limited data.
Establishing Trustworthiness: Rethinking Tasks and Model Evaluation
Oct 23, 2023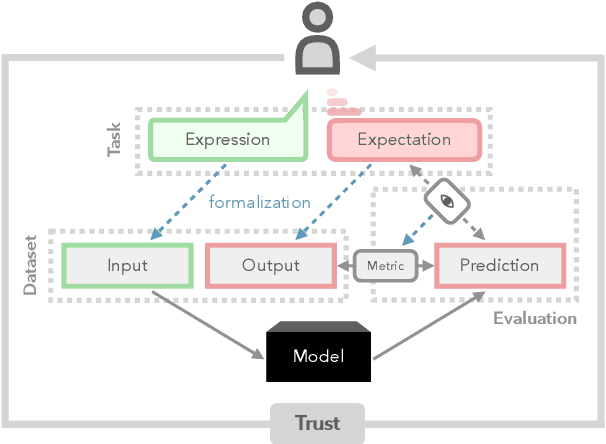
Language understanding is a multi-faceted cognitive capability, which the Natural Language Processing (NLP) community has striven to model computationally for decades. Traditionally, facets of linguistic intelligence have been compartmentalized into tasks with specialized model architectures and corresponding evaluation protocols. With the advent of large language models (LLMs) the community has witnessed a dramatic shift towards general purpose, task-agnostic approaches powered by generative models. As a consequence, the traditional compartmentalized notion of language tasks is breaking down, followed by an increasing challenge for evaluation and analysis. At the same time, LLMs are being deployed in more real-world scenarios, including previously unforeseen zero-shot setups, increasing the need for trustworthy and reliable systems. Therefore, we argue that it is time to rethink what constitutes tasks and model evaluation in NLP, and pursue a more holistic view on language, placing trustworthiness at the center. Towards this goal, we review existing compartmentalized approaches for understanding the origins of a model's functional capacity, and provide recommendations for more multi-faceted evaluation protocols.
Evidence > Intuition: Transferability Estimation for Encoder Selection
Oct 20, 2022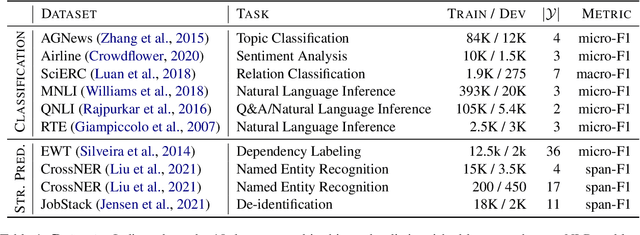
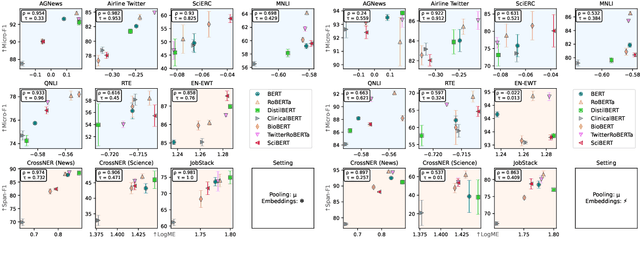
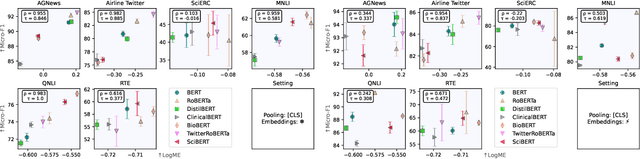
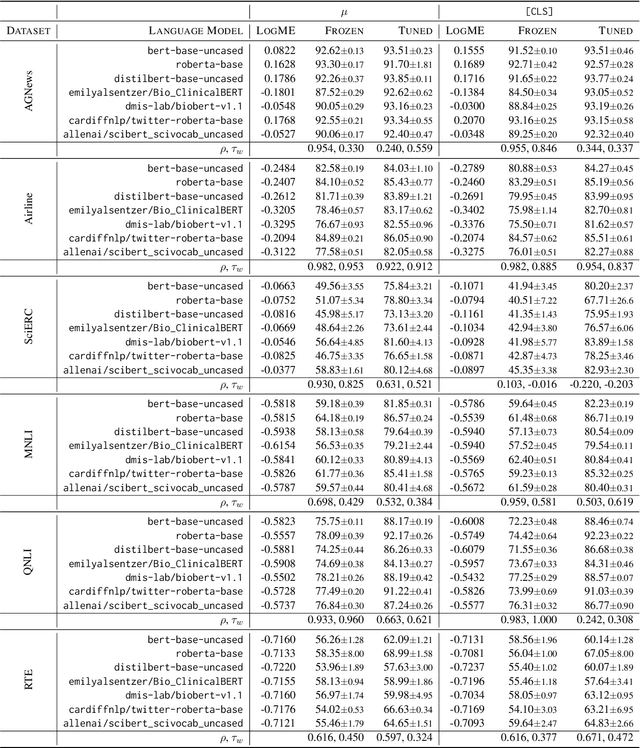
With the increase in availability of large pre-trained language models (LMs) in Natural Language Processing (NLP), it becomes critical to assess their fit for a specific target task a priori - as fine-tuning the entire space of available LMs is computationally prohibitive and unsustainable. However, encoder transferability estimation has received little to no attention in NLP. In this paper, we propose to generate quantitative evidence to predict which LM, out of a pool of models, will perform best on a target task without having to fine-tune all candidates. We provide a comprehensive study on LM ranking for 10 NLP tasks spanning the two fundamental problem types of classification and structured prediction. We adopt the state-of-the-art Logarithm of Maximum Evidence (LogME) measure from Computer Vision (CV) and find that it positively correlates with final LM performance in 94% of the setups. In the first study of its kind, we further compare transferability measures with the de facto standard of human practitioner ranking, finding that evidence from quantitative metrics is more robust than pure intuition and can help identify unexpected LM candidates.
Sort by Structure: Language Model Ranking as Dependency Probing
Jun 10, 2022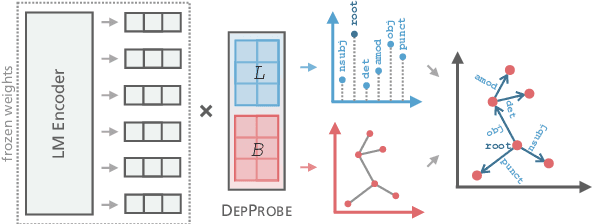
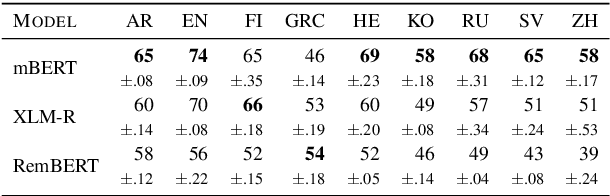
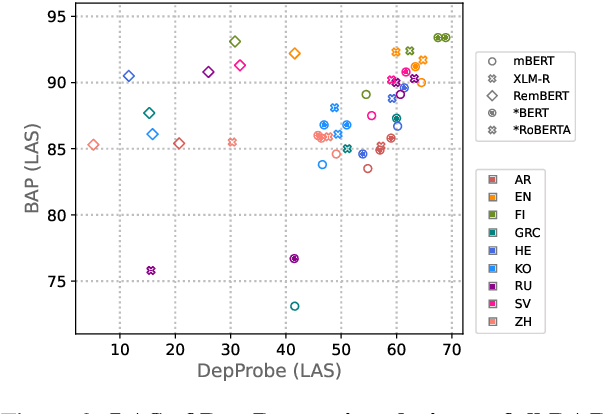
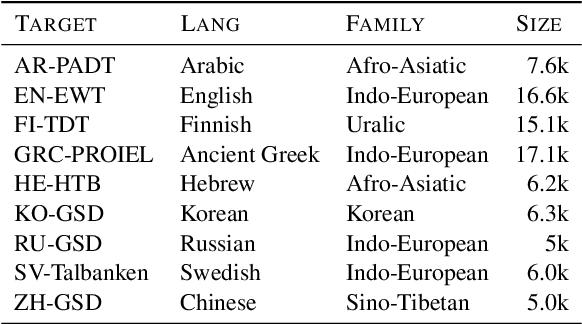
Making an informed choice of pre-trained language model (LM) is critical for performance, yet environmentally costly, and as such widely underexplored. The field of Computer Vision has begun to tackle encoder ranking, with promising forays into Natural Language Processing, however they lack coverage of linguistic tasks such as structured prediction. We propose probing to rank LMs, specifically for parsing dependencies in a given language, by measuring the degree to which labeled trees are recoverable from an LM's contextualized embeddings. Across 46 typologically and architecturally diverse LM-language pairs, our probing approach predicts the best LM choice 79% of the time using orders of magnitude less compute than training a full parser. Within this study, we identify and analyze one recently proposed decoupled LM - RemBERT - and find it strikingly contains less inherent dependency information, but often yields the best parser after full fine-tuning. Without this outlier our approach identifies the best LM in 89% of cases.
Experimental Standards for Deep Learning Research: A Natural Language Processing Perspective
Apr 13, 2022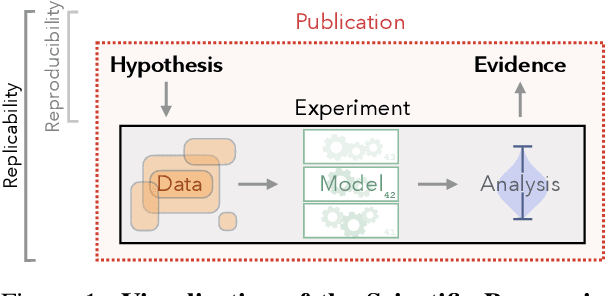

The field of Deep Learning (DL) has undergone explosive growth during the last decade, with a substantial impact on Natural Language Processing (NLP) as well. Yet, as with other fields employing DL techniques, there has been a lack of common experimental standards compared to more established disciplines. Starting from fundamental scientific principles, we distill ongoing discussions on experimental standards in DL into a single, widely-applicable methodology. Following these best practices is crucial to strengthening experimental evidence, improve reproducibility and enable scientific progress. These standards are further collected in a public repository to help them transparently adapt to future needs.