 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Extraction and Recognition of Implicit Discourse Relations in Speech and Text
Feb 04, 2026Implicit discourse relation classification is a challenging task, as it requires inferring meaning from context. While contextual cues can be distributed across modalities and vary across languages, they are not always captured by text alone. To address this, we introduce an automatic method for distantly related and unrelated language pairs to construct a multilingual and multimodal dataset for implicit discourse relations in English, French, and Spanish. For classification, we propose a multimodal approach that integrates textual and acoustic information through Qwen2-Audio, allowing joint modeling of text and audio for implicit discourse relation classification across languages. We find that while text-based models outperform audio-based models, integrating both modalities can enhance performance, and cross-lingual transfer can provide substantial improvements for low-resource languages.
A comparison of data filtering techniques for English-Polish LLM-based machine translation in the biomedical domain
Jan 27, 2025Large Language Models (LLMs) have become state-of-the-art in Machine Translation (MT), often trained on massive bilingual parallel corpora scraped from the web, that contain low-quality entries and redundant information, leading to significant computational challenges. Various data filtering methods exist to reduce dataset sizes, but their effectiveness largely varies based on specific language pairs and domains. This paper evaluates the impact of commonly used data filtering techniques, such as LASER, MUSE, and LaBSE, on English-Polish translation within the biomedical domain. By filtering the UFAL Medical Corpus, we created varying dataset sizes to fine-tune the mBART50 model, which was then evaluated using the SacreBLEU metric on the Khresmoi dataset, having the quality of translations assessed by bilingual speakers. Our results show that both LASER and MUSE can significantly reduce dataset sizes while maintaining or even enhancing performance. We recommend the use of LASER, as it consistently outperforms the other methods and provides the most fluent and natural-sounding translations.
Mention Attention for Pronoun Translation
Dec 19, 2024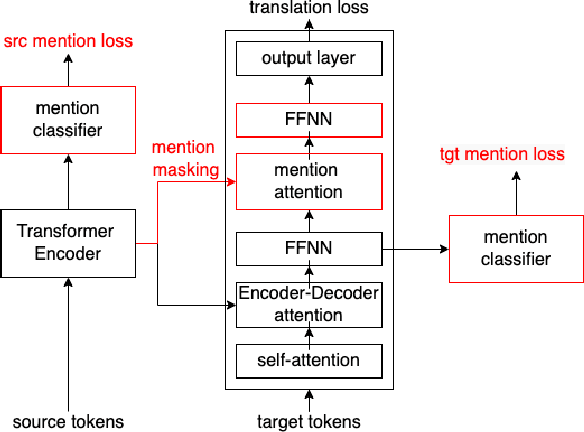

Most pronouns are referring expressions, computers need to resolve what do the pronouns refer to, and there are divergences on pronoun usage across languages. Thus, dealing with these divergences and translating pronouns is a challenge in machine translation. Mentions are referring candidates of pronouns and have closer relations with pronouns compared to general tokens. We assume that extracting additional mention features can help pronoun translation. Therefore, we introduce an additional mention attention module in the decoder to pay extra attention to source mentions but not non-mention tokens. Our mention attention module not only extracts features from source mentions, but also considers target-side context which benefits pronoun translation. In addition, we also introduce two mention classifiers to train models to recognize mentions, whose outputs guide the mention attention. We conduct experiments on the WMT17 English-German translation task, and evaluate our models on general translation and pronoun translation, using BLEU, APT, and contrastive evaluation metrics. Our proposed model outperforms the baseline Transformer model in terms of APT and BLEU scores, this confirms our hypothesis that we can improve pronoun translation by paying additional attention to source mentions, and shows that our introduced additional modules do not have negative effect on the general translation quality.
With Good MT There is No Need For End-to-End: A Case for Translate-then-Summarize Cross-lingual Summarization
Aug 31, 2024


Recent work has suggested that end-to-end system designs for cross-lingual summarization are competitive solutions that perform on par or even better than traditional pipelined designs. A closer look at the evidence reveals that this intuition is based on the results of only a handful of languages or using underpowered pipeline baselines. In this work, we compare these two paradigms for cross-lingual summarization on 39 source languages into English and show that a simple \textit{translate-then-summarize} pipeline design consistently outperforms even an end-to-end system with access to enormous amounts of parallel data. For languages where our pipeline model does not perform well, we show that system performance is highly correlated with publicly distributed BLEU scores, allowing practitioners to establish the feasibility of a language pair a priori. Contrary to recent publication trends, our result suggests that the combination of individual progress of monolingual summarization and translation tasks offers better performance than an end-to-end system, suggesting that end-to-end designs should be considered with care.
A Dataset for the Detection of Dehumanizing Language
Feb 13, 2024Dehumanization is a mental process that enables the exclusion and ill treatment of a group of people. In this paper, we present two data sets of dehumanizing text, a large, automatically collected corpus and a smaller, manually annotated data set. Both data sets include a combination of political discourse and dialogue from movie subtitles. Our methods give us a broad and varied amount of dehumanization data to work with, enabling further exploratory analysis and automatic classification of dehumanization patterns. Both data sets will be publicly released.
Parallel Data Helps Neural Entity Coreference Resolution
May 28, 2023Coreference resolution is the task of finding expressions that refer to the same entity in a text. Coreference models are generally trained on monolingual annotated data but annotating coreference is expensive and challenging. Hardmeier et al.(2013) have shown that parallel data contains latent anaphoric knowledge, but it has not been explored in end-to-end neural models yet. In this paper, we propose a simple yet effective model to exploit coreference knowledge from parallel data. In addition to the conventional modules learning coreference from annotations, we introduce an unsupervised module to capture cross-lingual coreference knowledge. Our proposed cross-lingual model achieves consistent improvements, up to 1.74 percentage points, on the OntoNotes 5.0 English dataset using 9 different synthetic parallel datasets. These experimental results confirm that parallel data can provide additional coreference knowledge which is beneficial to coreference resolution tasks.
deep-significance - Easy and Meaningful Statistical Significance Testing in the Age of Neural Networks
Apr 14, 2022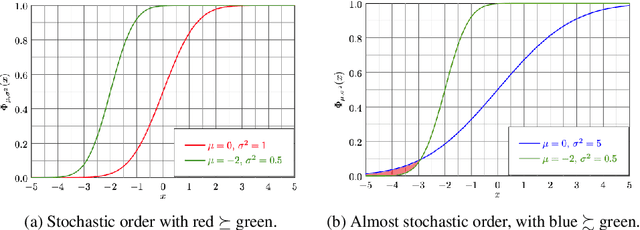
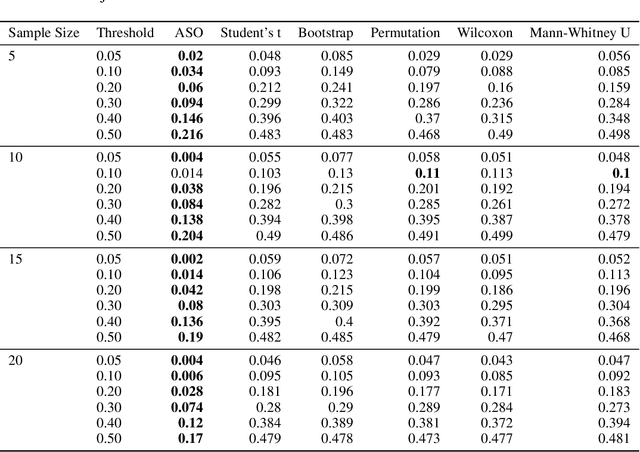
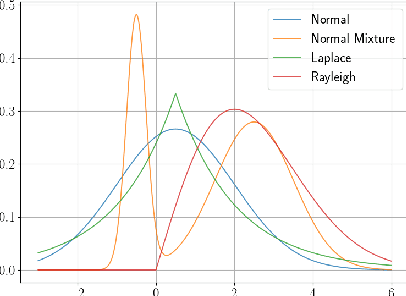
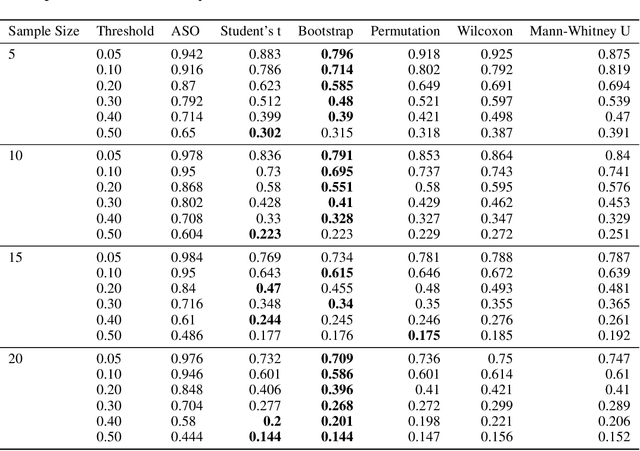
A lot of Machine Learning (ML) and Deep Learning (DL) research is of an empirical nature. Nevertheless, statistical significance testing (SST) is still not widely used. This endangers true progress, as seeming improvements over a baseline might be statistical flukes, leading follow-up research astray while wasting human and computational resources. Here, we provide an easy-to-use package containing different significance tests and utility functions specifically tailored towards research needs and usability.
Experimental Standards for Deep Learning Research: A Natural Language Processing Perspective
Apr 13, 2022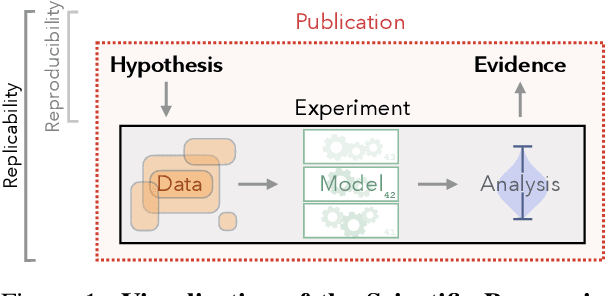

The field of Deep Learning (DL) has undergone explosive growth during the last decade, with a substantial impact on Natural Language Processing (NLP) as well. Yet, as with other fields employing DL techniques, there has been a lack of common experimental standards compared to more established disciplines. Starting from fundamental scientific principles, we distill ongoing discussions on experimental standards in DL into a single, widely-applicable methodology. Following these best practices is crucial to strengthening experimental evidence, improve reproducibility and enable scientific progress. These standards are further collected in a public repository to help them transparently adapt to future needs.
Unsupervised Discovery of Unaccusative and Unergative Verbs
Nov 01, 2021

We present an unsupervised method to detect English unergative and unaccusative verbs. These categories allow us to identify verbs participating in the causative-inchoative alternation without knowing the semantic roles of the verb. The method is based on the generation of intransitive sentence variants of candidate verbs and probing a language model. We obtained results on par with similar approaches, with the added benefit of not relying on annotated resources.
How to Write a Bias Statement: Recommendations for Submissions to the Workshop on Gender Bias in NLP
Apr 07, 2021At the Workshop on Gender Bias in NLP (GeBNLP), we'd like to encourage authors to give explicit consideration to the wider aspects of bias and its social implications. For the 2020 edition of the workshop, we therefore requested that all authors include an explicit bias statement in their work to clarify how their work relates to the social context in which NLP systems are used. The programme committee of the workshops included a number of reviewers with a background in the humanities and social sciences, in addition to NLP experts doing the bulk of the reviewing. Each paper was assigned one of those reviewers, and they were asked to pay specific attention to the provided bias statements in their reviews. This initiative was well received by the authors who submitted papers to the workshop, several of whom said they received useful suggestions and literature hints from the bias reviewers. We are therefore planning to keep this feature of the review process in future editions of the workshop.