 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Approach to Language Contact -- A Case Study of Persian
Jan 28, 2026We investigate structural traces of language contact in the intermediate representations of a monolingual language model. Focusing on Persian (Farsi) as a historically contact-rich language, we probe the representations of a Persian-trained model when exposed to languages with varying degrees and types of contact with Persian. Our methodology quantifies the amount of linguistic information encoded in intermediate representations and assesses how this information is distributed across model components for different morphosyntactic features. The results show that universal syntactic information is largely insensitive to historical contact, whereas morphological features such as Case and Gender are strongly shaped by language-specific structure, suggesting that contact effects in monolingual language models are selective and structurally constrained.
Syntactic Nuclei in Dependency Parsing -- A Multilingual Exploration
Jan 29, 2021
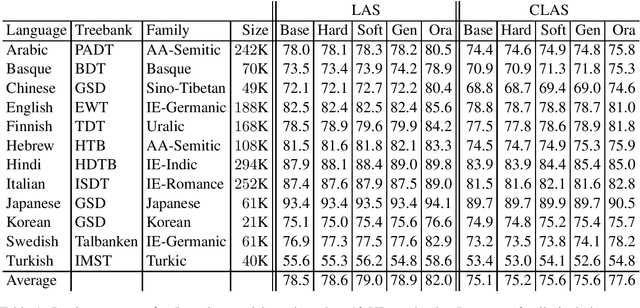
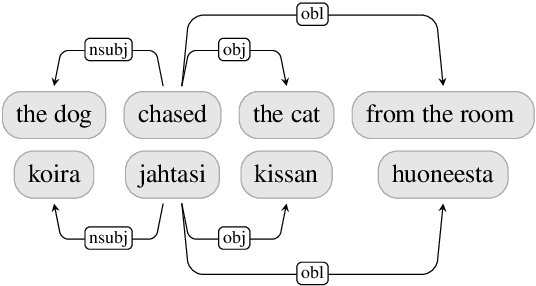
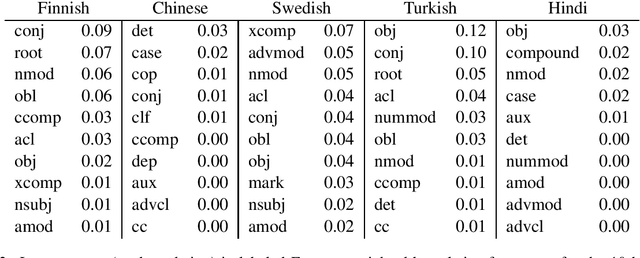
Standard models for syntactic dependency parsing take words to be the elementary units that enter into dependency relations. In this paper, we investigate whether there are any benefits from enriching these models with the more abstract notion of nucleus proposed by Tesni\`{e}re. We do this by showing how the concept of nucleus can be defined in the framework of Universal Dependencies and how we can use composition functions to make a transition-based dependency parser aware of this concept. Experiments on 12 languages show that nucleus composition gives small but significant improvements in parsing accuracy. Further analysis reveals that the improvement mainly concerns a small number of dependency relations, including nominal modifiers, relations of coordination, main predicates, and direct objects.
Cross-lingual Word Embeddings beyond Zero-shot Machine Translation
Nov 03, 2020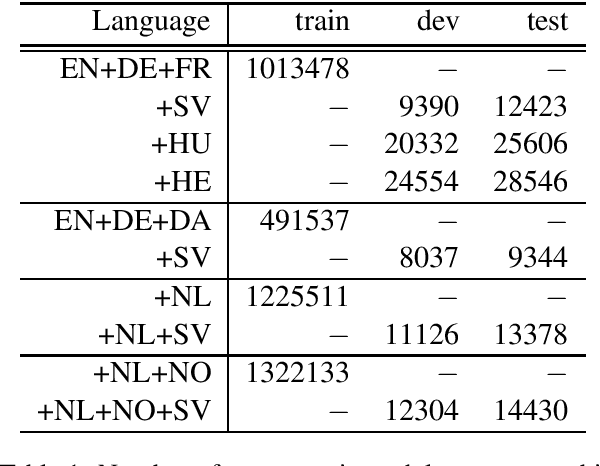
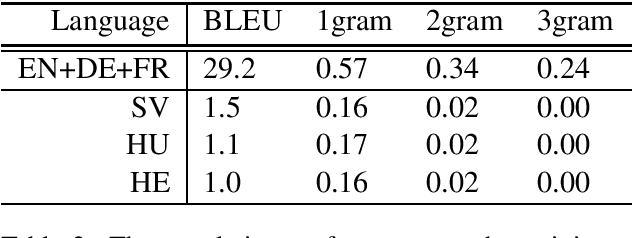
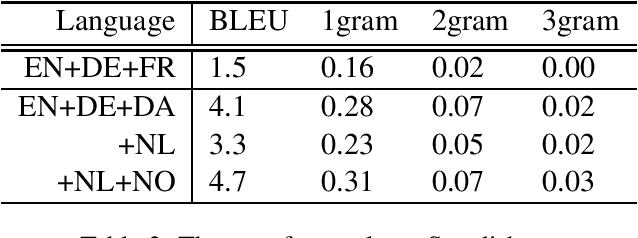
We explore the transferability of a multilingual neural machine translation model to unseen languages when the transfer is grounded solely on the cross-lingual word embeddings. Our experimental results show that the translation knowledge can transfer weakly to other languages and that the degree of transferability depends on the languages' relatedness. We also discuss the limiting aspects of the multilingual architectures that cause weak translation transfer and suggest how to mitigate the limitations.
An exploration of the encoding of grammatical gender in word embeddings
Aug 05, 2020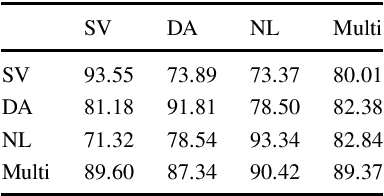

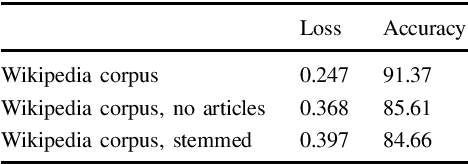
The vector representation of words, known as word embeddings, has opened a new research approach in the study of languages. These representations can capture different types of information about words. The grammatical gender of nouns is a typical classification of nouns based on their formal and semantic properties. The study of grammatical gender based on word embeddings can give insight into discussions on how grammatical genders are determined. In this research, we compare different sets of word embeddings according to the accuracy of a neural classifier determining the grammatical gender of nouns. It is found that the information about grammatical gender is encoded differently in Swedish, Danish, and Dutch embeddings. Our experimental results on the contextualized embeddings pointed out that adding more contextual (semantic) information to embeddings is detrimental to the classifier's performance. We also observed that removing morpho-syntactic features such as articles from the training corpora of embeddings decreases the classification performance dramatically, indicating a large portion of the information is encoded in the relationship between nouns and articles.
Word embedding and neural network on grammatical gender -- A case study of Swedish
Jul 28, 2020
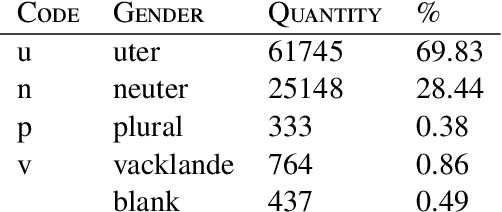
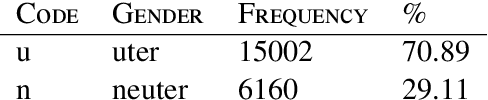
We analyze the information provided by the word embeddings about the grammatical gender in Swedish. We wish that this paper may serve as one of the bridges to connect the methods of computational linguistics and general linguistics. Taking nominal classification in Swedish as a case study, we first show how the information about grammatical gender in language can be captured by word embedding models and artificial neural networks. Then, we match our results with previous linguistic hypotheses on assignment and usage of grammatical gender in Swedish and analyze the errors made by the computational model from a linguistic perspective.
Greedy Transition-Based Dependency Parsing with Discrete and Continuous Supertag Features
Jul 09, 2020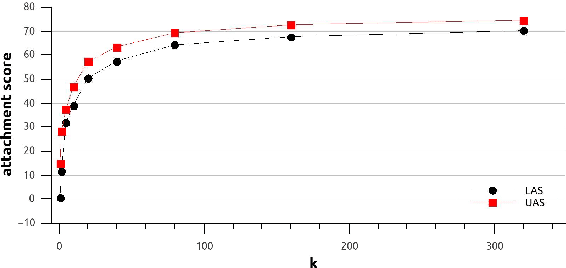
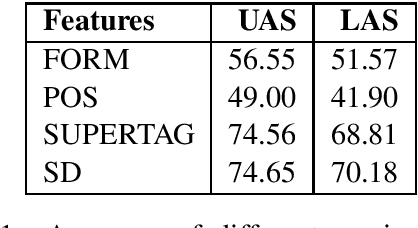
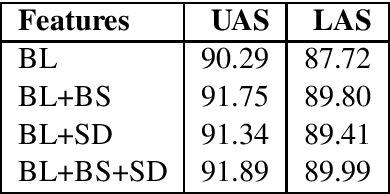
We study the effect of rich supertag features in greedy transition-based dependency parsing. While previous studies have shown that sparse boolean features representing the 1-best supertag of a word can improve parsing accuracy, we show that we can get further improvements by adding a continuous vector representation of the entire supertag distribution for a word. In this way, we achieve the best results for greedy transition-based parsing with supertag features with $88.6\%$ LAS and $90.9\%$ UASon the English Penn Treebank converted to Stanford Dependencies.
Principal Word Vectors
Jul 09, 2020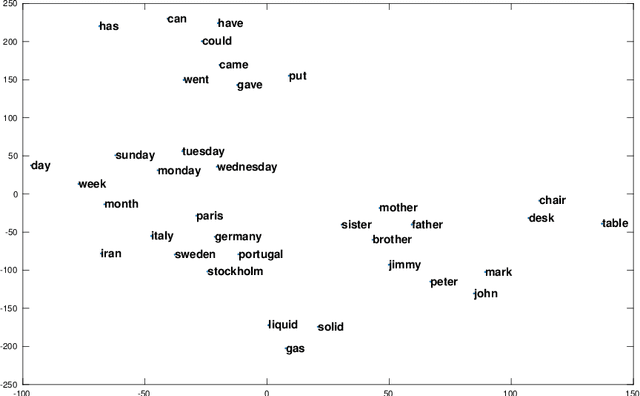

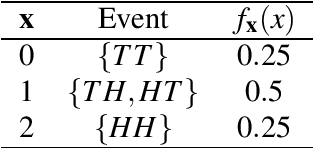
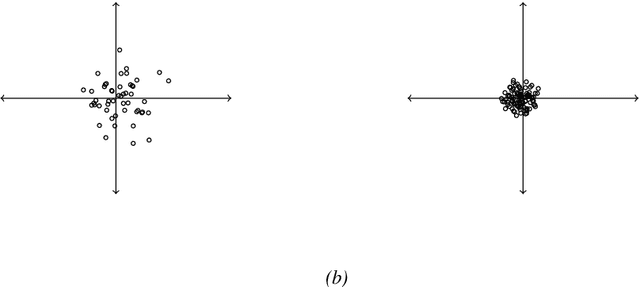
We generalize principal component analysis for embedding words into a vector space. The generalization is made in two major levels. The first is to generalize the concept of the corpus as a counting process which is defined by three key elements vocabulary set, feature (annotation) set, and context. This generalization enables the principal word embedding method to generate word vectors with regard to different types of contexts and different types of annotations provided for a corpus. The second is to generalize the transformation step used in most of the word embedding methods. To this end, we define two levels of transformations. The first is a quadratic transformation, which accounts for different types of weighting over the vocabulary units and contextual features. Second is an adaptive non-linear transformation, which reshapes the data distribution to be meaningful to principal component analysis. The effect of these generalizations on the word vectors is intrinsically studied with regard to the spread and the discriminability of the word vectors. We also provide an extrinsic evaluation of the contribution of the principal word vectors on a word similarity benchmark and the task of dependency parsing. Our experiments are finalized by a comparison between the principal word vectors and other sets of word vectors generated with popular word embedding methods. The results obtained from our intrinsic evaluation metrics show that the spread and the discriminability of the principal word vectors are higher than that of other word embedding methods. The results obtained from the extrinsic evaluation metrics show that the principal word vectors are better than some of the word embedding methods and on par with popular methods of word embedding.
Shifted Randomized Singular Value Decomposition
Nov 28, 2019
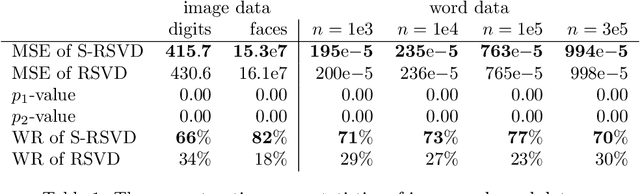

We extend the randomized singular value decomposition (SVD) algorithm \citep{Halko2011finding} to estimate the SVD of a shifted data matrix without explicitly constructing the matrix in the memory. With no loss in the accuracy of the original algorithm, the extended algorithm provides for a more efficient way of matrix factorization. The algorithm facilitates the low-rank approximation and principal component analysis (PCA) of off-center data matrices. When applied to different types of data matrices, our experimental results confirm the advantages of the extensions made to the original algorithm.