Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Transition-Based Dependency Parsing with Discrete and Continuous Supertag Features
Paper and Code
Jul 09, 2020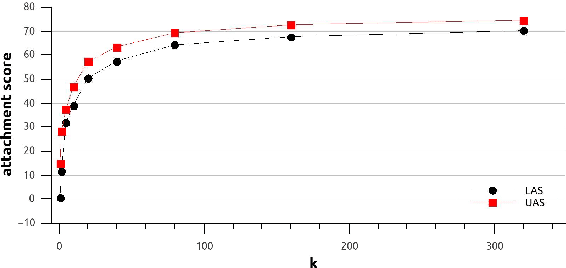
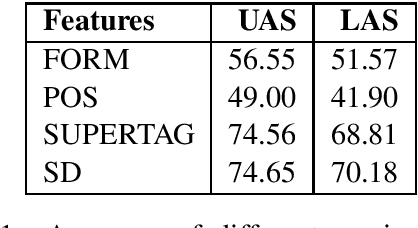
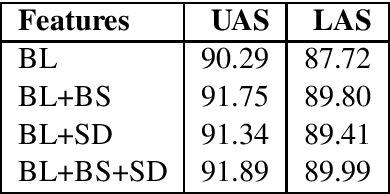
We study the effect of rich supertag features in greedy transition-based dependency parsing. While previous studies have shown that sparse boolean features representing the 1-best supertag of a word can improve parsing accuracy, we show that we can get further improvements by adding a continuous vector representation of the entire supertag distribution for a word. In this way, we achieve the best results for greedy transition-based parsing with supertag features with $88.6\%$ LAS and $90.9\%$ UASon the English Penn Treebank converted to Stanford Dependencies.
* This paper was originally submitted to EMNLP 2015 and has not been
previously published
View paper on