 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimate-Eval: A Comprehensive Benchmark for NLP Tasks Related to Climate Change
May 24, 2025Climate-Eval is a comprehensive benchmark designed to evaluate natural language processing models across a broad range of tasks related to climate change. Climate-Eval aggregates existing datasets along with a newly developed news classification dataset, created specifically for this release. This results in a benchmark of 25 tasks based on 13 datasets, covering key aspects of climate discourse, including text classification, question answering, and information extraction. Our benchmark provides a standardized evaluation suite for systematically assessing the performance of large language models (LLMs) on these tasks. Additionally, we conduct an extensive evaluation of open-source LLMs (ranging from 2B to 70B parameters) in both zero-shot and few-shot settings, analyzing their strengths and limitations in the domain of climate change.
Can LLMs Detect Intrinsic Hallucinations in Paraphrasing and Machine Translation?
Apr 29, 2025A frequently observed problem with LLMs is their tendency to generate output that is nonsensical, illogical, or factually incorrect, often referred to broadly as hallucination. Building on the recently proposed HalluciGen task for hallucination detection and generation, we evaluate a suite of open-access LLMs on their ability to detect intrinsic hallucinations in two conditional generation tasks: translation and paraphrasing. We study how model performance varies across tasks and language and we investigate the impact of model size, instruction tuning, and prompt choice. We find that performance varies across models but is consistent across prompts. Finally, we find that NLI models perform comparably well, suggesting that LLM-based detectors are not the only viable option for this specific task.
Overview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation
Dec 05, 2024



This paper introduces the counter-intuitive generalization results of overfitting pre-trained large language models (LLMs) on very small datasets. In the setting of open-ended text generation, it is well-documented that LLMs tend to generate repetitive and dull sequences, a phenomenon that is especially apparent when generating using greedy decoding. This issue persists even with state-of-the-art LLMs containing billions of parameters, trained via next-token prediction on large datasets. We find that by further fine-tuning these models to achieve a near-zero training loss on a small set of samples -- a process we refer to as hyperfitting -- the long-sequence generative capabilities are greatly enhanced. Greedy decoding with these Hyperfitted models even outperform Top-P sampling over long-sequences, both in terms of diversity and human preferences. This phenomenon extends to LLMs of various sizes, different domains, and even autoregressive image generation. We further find this phenomena to be distinctly different from that of Grokking and double descent. Surprisingly, our experiments indicate that hyperfitted models rarely fall into repeating sequences they were trained on, and even explicitly blocking these sequences results in high-quality output. All hyperfitted models produce extremely low-entropy predictions, often allocating nearly all probability to a single token.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024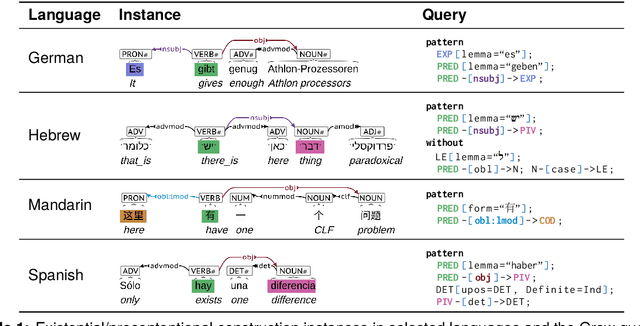
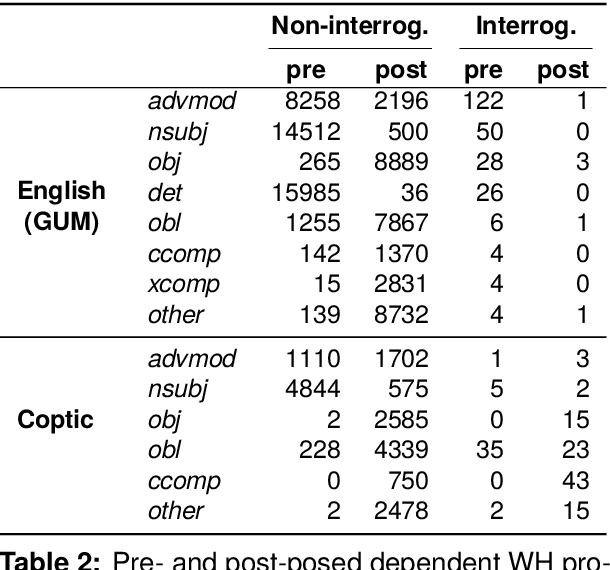
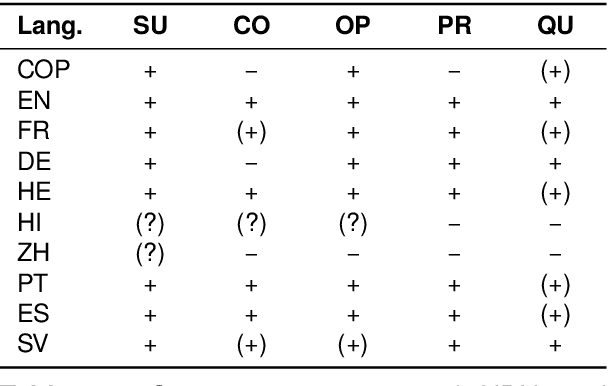
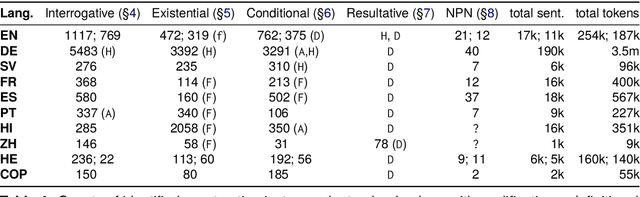
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
A Study of Continual Learning Under Language Shift
Nov 02, 2023The recent increase in data and model scale for language model pre-training has led to huge training costs. In scenarios where new data become available over time, updating a model instead of fully retraining it would therefore provide significant gains. In this paper, we study the benefits and downsides of updating a language model when new data comes from new languages - the case of continual learning under language shift. Starting from a monolingual English language model, we incrementally add data from Norwegian and Icelandic to investigate how forward and backward transfer effects depend on the pre-training order and characteristics of languages, for different model sizes and learning rate schedulers. Our results show that, while forward transfer is largely positive and independent of language order, backward transfer can be either positive or negative depending on the order and characteristics of new languages. To explain these patterns we explore several language similarity metrics and find that syntactic similarity appears to have the best correlation with our results.
Schrödinger's Tree -- On Syntax and Neural Language Models
Oct 17, 2021In the last half-decade, the field of natural language processing (NLP) has undergone two major transitions: the switch to neural networks as the primary modeling paradigm and the homogenization of the training regime (pre-train, then fine-tune). Amidst this process, language models have emerged as NLP's workhorse, displaying increasingly fluent generation capabilities and proving to be an indispensable means of knowledge transfer downstream. Due to the otherwise opaque, black-box nature of such models, researchers have employed aspects of linguistic theory in order to characterize their behavior. Questions central to syntax -- the study of the hierarchical structure of language -- have factored heavily into such work, shedding invaluable insights about models' inherent biases and their ability to make human-like generalizations. In this paper, we attempt to take stock of this growing body of literature. In doing so, we observe a lack of clarity across numerous dimensions, which influences the hypotheses that researchers form, as well as the conclusions they draw from their findings. To remedy this, we urge researchers make careful considerations when investigating coding properties, selecting representations, and evaluating via downstream tasks. Furthermore, we outline the implications of the different types of research questions exhibited in studies on syntax, as well as the inherent pitfalls of aggregate metrics. Ultimately, we hope that our discussion adds nuance to the prospect of studying language models and paves the way for a less monolithic perspective on syntax in this context.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021


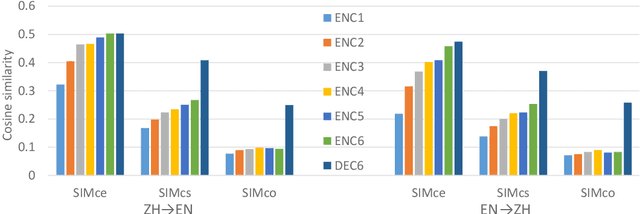
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.
Syntactic Nuclei in Dependency Parsing -- A Multilingual Exploration
Jan 29, 2021
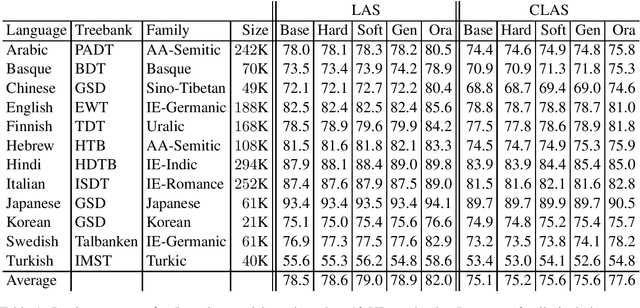
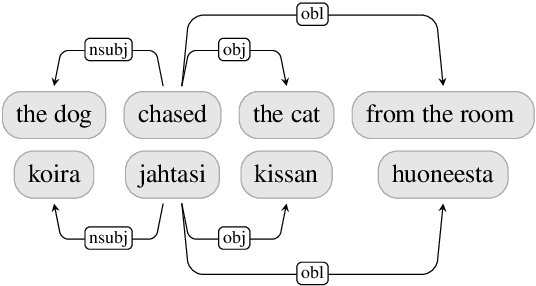
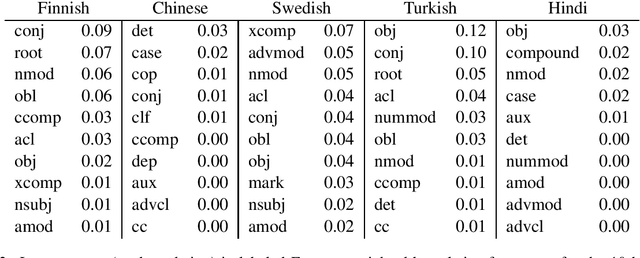
Standard models for syntactic dependency parsing take words to be the elementary units that enter into dependency relations. In this paper, we investigate whether there are any benefits from enriching these models with the more abstract notion of nucleus proposed by Tesni\`{e}re. We do this by showing how the concept of nucleus can be defined in the framework of Universal Dependencies and how we can use composition functions to make a transition-based dependency parser aware of this concept. Experiments on 12 languages show that nucleus composition gives small but significant improvements in parsing accuracy. Further analysis reveals that the improvement mainly concerns a small number of dependency relations, including nominal modifiers, relations of coordination, main predicates, and direct objects.
Attention Can Reflect Syntactic Structure (If You Let It)
Jan 26, 2021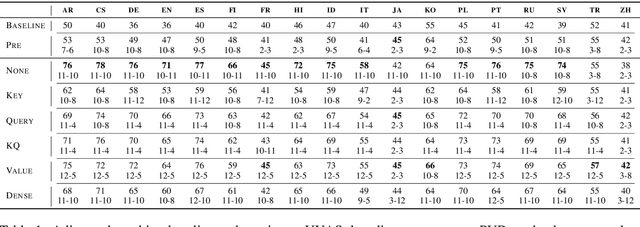
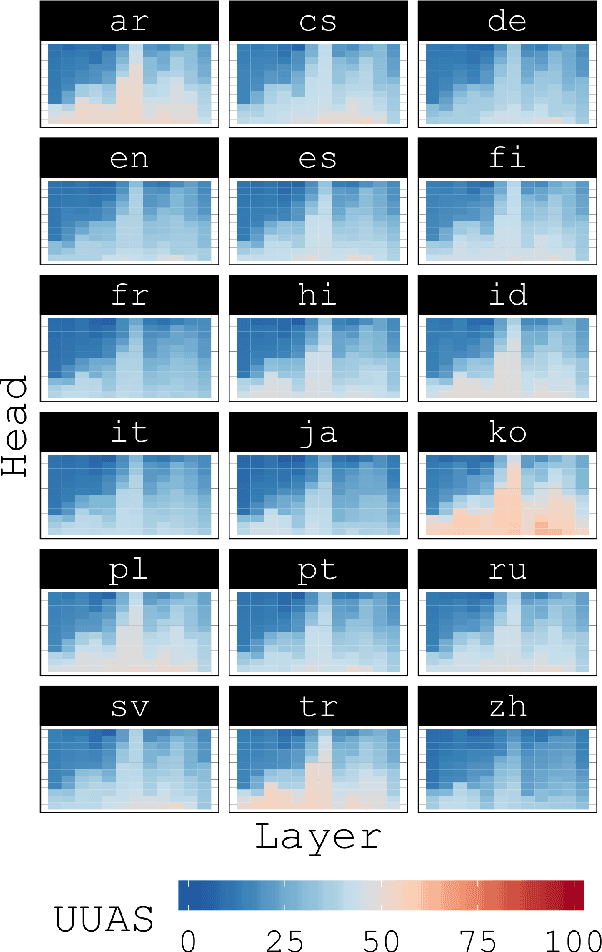
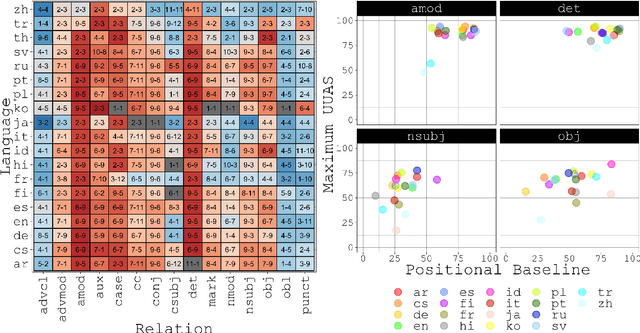
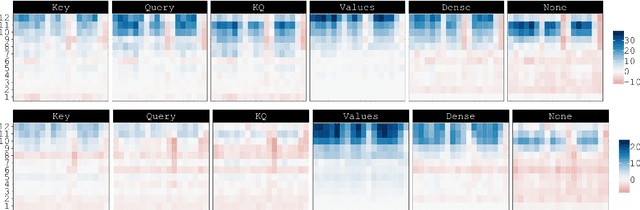
Since the popularization of the Transformer as a general-purpose feature encoder for NLP, many studies have attempted to decode linguistic structure from its novel multi-head attention mechanism. However, much of such work focused almost exclusively on English -- a language with rigid word order and a lack of inflectional morphology. In this study, we present decoding experiments for multilingual BERT across 18 languages in order to test the generalizability of the claim that dependency syntax is reflected in attention patterns. We show that full trees can be decoded above baseline accuracy from single attention heads, and that individual relations are often tracked by the same heads across languages. Furthermore, in an attempt to address recent debates about the status of attention as an explanatory mechanism, we experiment with fine-tuning mBERT on a supervised parsing objective while freezing different series of parameters. Interestingly, in steering the objective to learn explicit linguistic structure, we find much of the same structure represented in the resulting attention patterns, with interesting differences with respect to which parameters are frozen.