 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
Investigating Idiomaticity in Word Representations
Nov 04, 2024



Idiomatic expressions are an integral part of human languages, often used to express complex ideas in compressed or conventional ways (e.g. eager beaver as a keen and enthusiastic person). However, their interpretations may not be straightforwardly linked to the meanings of their individual components in isolation and this may have an impact for compositional approaches. In this paper, we investigate to what extent word representation models are able to go beyond compositional word combinations and capture multiword expression idiomaticity and some of the expected properties related to idiomatic meanings. We focus on noun compounds of varying levels of idiomaticity in two languages (English and Portuguese), presenting a dataset of minimal pairs containing human idiomaticity judgments for each noun compound at both type and token levels, their paraphrases and their occurrences in naturalistic and sense-neutral contexts, totalling 32,200 sentences. We propose this set of minimal pairs for evaluating how well a model captures idiomatic meanings, and define a set of fine-grained metrics of Affinity and Scaled Similarity, to determine how sensitive the models are to perturbations that may lead to changes in idiomaticity. The results obtained with a variety of representative and widely used models indicate that, despite superficial indications to the contrary in the form of high similarities, idiomaticity is not yet accurately represented in current models. Moreover, the performance of models with different levels of contextualisation suggests that their ability to capture context is not yet able to go beyond more superficial lexical clues provided by the words and to actually incorporate the relevant semantic clues needed for idiomaticity.
Open Generative Large Language Models for Galician
Jun 19, 2024Large language models (LLMs) have transformed natural language processing. Yet, their predominantly English-centric training has led to biases and performance disparities across languages. This imbalance marginalizes minoritized languages, making equitable access to NLP technologies more difficult for languages with lower resources, such as Galician. We present the first two generative LLMs focused on Galician to bridge this gap. These models, freely available as open-source resources, were trained using a GPT architecture with 1.3B parameters on a corpus of 2.1B words. Leveraging continual pretraining, we adapt to Galician two existing LLMs trained on larger corpora, thus mitigating the data constraints that would arise if the training were performed from scratch. The models were evaluated using human judgments and task-based datasets from standardized benchmarks. These evaluations reveal a promising performance, underscoring the importance of linguistic diversity in generative models.
A computational psycholinguistic evaluation of the syntactic abilities of Galician BERT models at the interface of dependency resolution and training time
Jun 06, 2022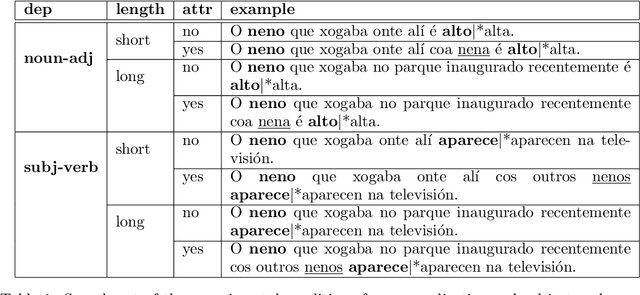
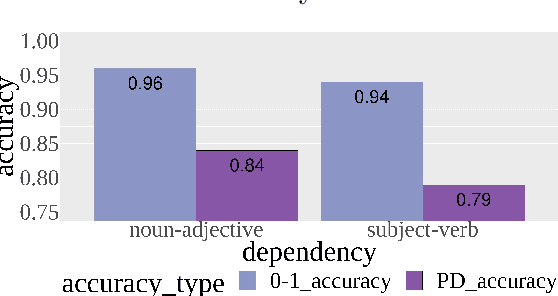

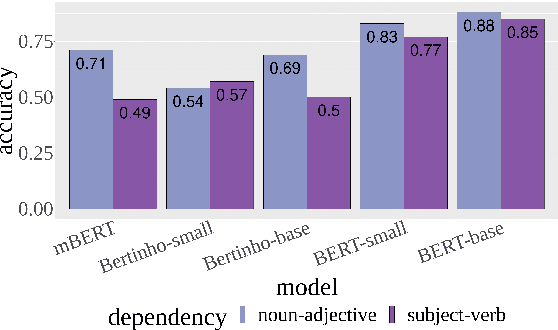
This paper explores the ability of Transformer models to capture subject-verb and noun-adjective agreement dependencies in Galician. We conduct a series of word prediction experiments in which we manipulate dependency length together with the presence of an attractor noun that acts as a lure. First, we evaluate the overall performance of the existing monolingual and multilingual models for Galician. Secondly, to observe the effects of the training process, we compare the different degrees of achievement of two monolingual BERT models at different training points. We also release their checkpoints and propose an alternative evaluation metric. Our results confirm previous findings by similar works that use the agreement prediction task and provide interesting insights into the number of training steps required by a Transformer model to solve long-distance dependencies.
SemEval-2022 Task 2: Multilingual Idiomaticity Detection and Sentence Embedding
Apr 21, 2022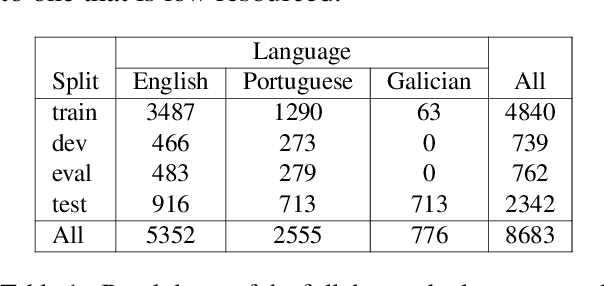
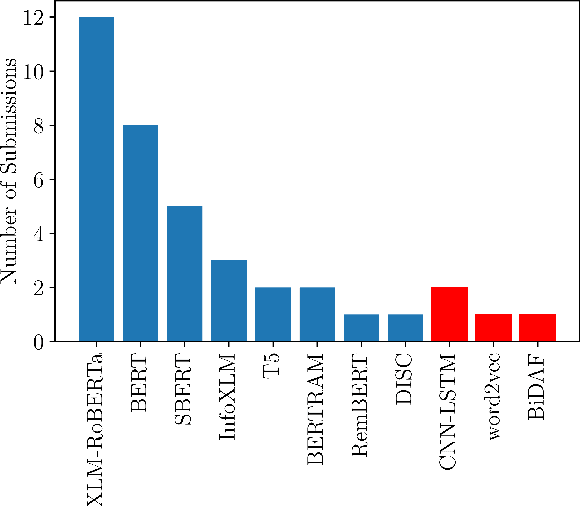

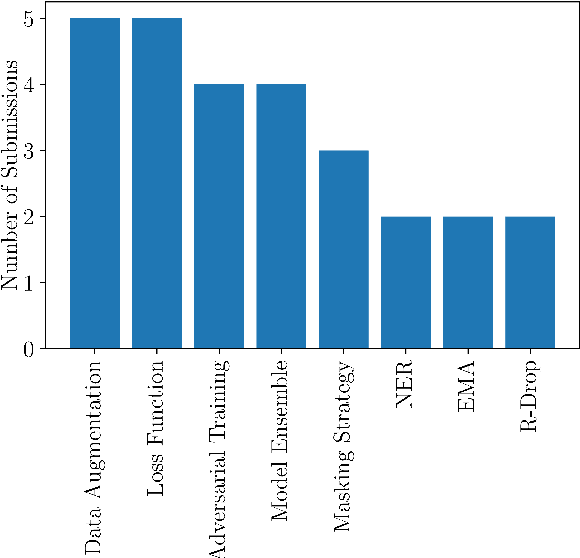
This paper presents the shared task on Multilingual Idiomaticity Detection and Sentence Embedding, which consists of two subtasks: (a) a binary classification one aimed at identifying whether a sentence contains an idiomatic expression, and (b) a task based on semantic text similarity which requires the model to adequately represent potentially idiomatic expressions in context. Each subtask includes different settings regarding the amount of training data. Besides the task description, this paper introduces the datasets in English, Portuguese, and Galician and their annotation procedure, the evaluation metrics, and a summary of the participant systems and their results. The task had close to 100 registered participants organised into twenty five teams making over 650 and 150 submissions in the practice and evaluation phases respectively.
Exploring the Representation of Word Meanings in Context: A Case Study on Homonymy and Synonymy
Jun 29, 2021
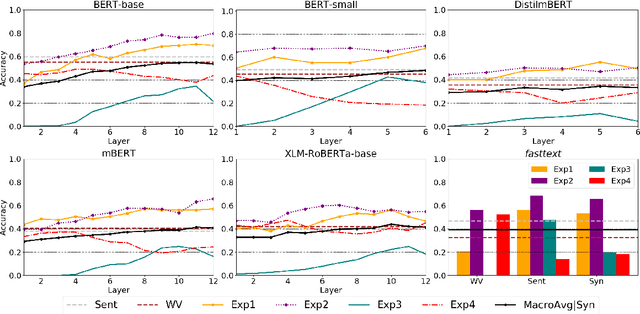
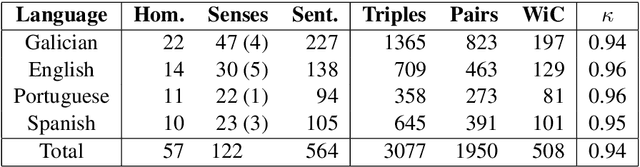
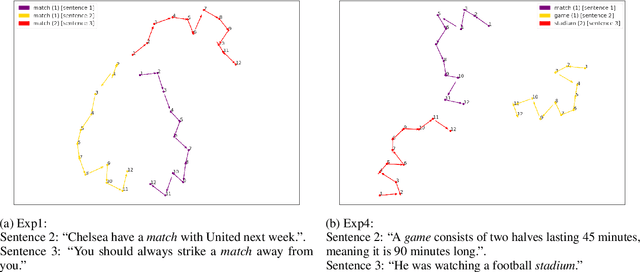
This paper presents a multilingual study of word meaning representations in context. We assess the ability of both static and contextualized models to adequately represent different lexical-semantic relations, such as homonymy and synonymy. To do so, we created a new multilingual dataset that allows us to perform a controlled evaluation of several factors such as the impact of the surrounding context or the overlap between words, conveying the same or different senses. A systematic assessment on four scenarios shows that the best monolingual models based on Transformers can adequately disambiguate homonyms in context. However, as they rely heavily on context, these models fail at representing words with different senses when occurring in similar sentences. Experiments are performed in Galician, Portuguese, English, and Spanish, and both the dataset (with more than 3,000 evaluation items) and new models are freely released with this study.
* 16 pages, 4 figures
Bertinho: Galician BERT Representations
Mar 25, 2021
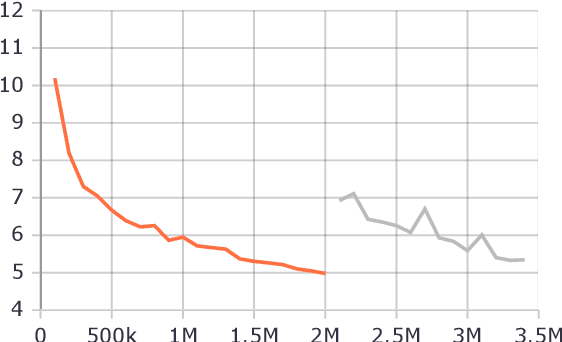
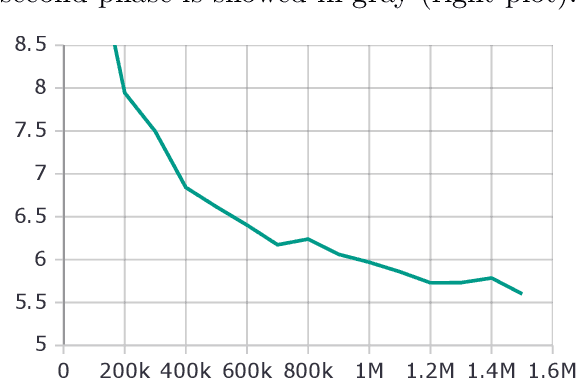
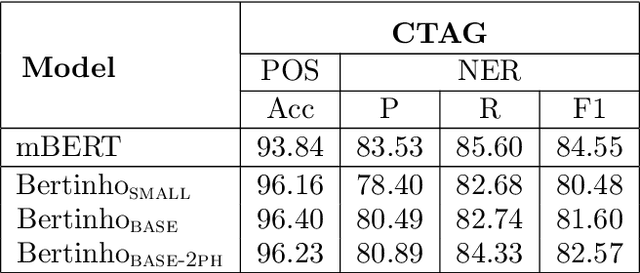
This paper presents a monolingual BERT model for Galician. We follow the recent trend that shows that it is feasible to build robust monolingual BERT models even for relatively low-resource languages, while performing better than the well-known official multilingual BERT (mBERT). More particularly, we release two monolingual Galician BERT models, built using 6 and 12 transformer layers, respectively; trained with limited resources (~45 million tokens on a single GPU of 24GB). We then provide an exhaustive evaluation on a number of tasks such as POS-tagging, dependency parsing and named entity recognition. For this purpose, all these tasks are cast in a pure sequence labeling setup in order to run BERT without the need to include any additional layers on top of it (we only use an output classification layer to map the contextualized representations into the predicted label). The experiments show that our models, especially the 12-layer one, outperform the results of mBERT in most tasks.
Towards Syntactic Iberian Polarity Classification
Aug 17, 2017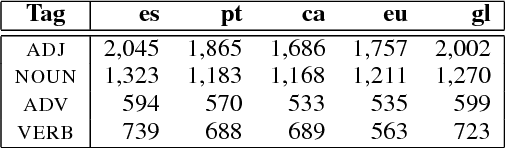
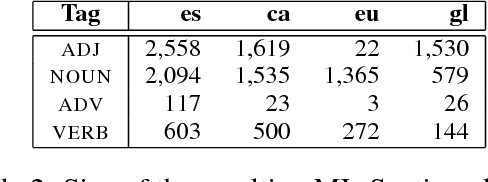
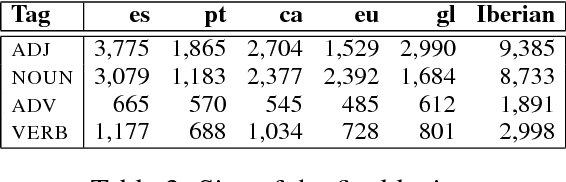
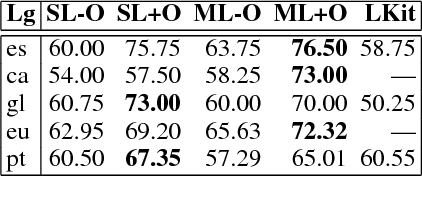
Lexicon-based methods using syntactic rules for polarity classification rely on parsers that are dependent on the language and on treebank guidelines. Thus, rules are also dependent and require adaptation, especially in multilingual scenarios. We tackle this challenge in the context of the Iberian Peninsula, releasing the first symbolic syntax-based Iberian system with rules shared across five official languages: Basque, Catalan, Galician, Portuguese and Spanish. The model is made available.