 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Representation of Word Meanings in Context: A Case Study on Homonymy and Synonymy
Paper and Code

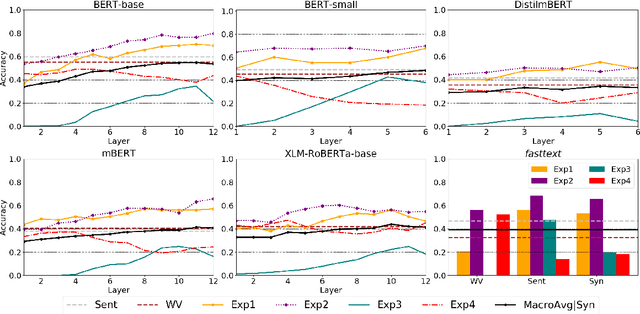
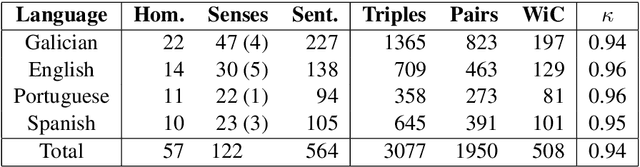
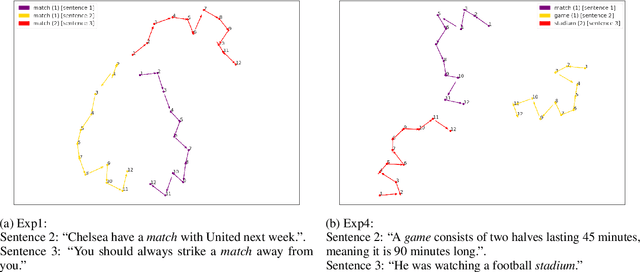
This paper presents a multilingual study of word meaning representations in context. We assess the ability of both static and contextualized models to adequately represent different lexical-semantic relations, such as homonymy and synonymy. To do so, we created a new multilingual dataset that allows us to perform a controlled evaluation of several factors such as the impact of the surrounding context or the overlap between words, conveying the same or different senses. A systematic assessment on four scenarios shows that the best monolingual models based on Transformers can adequately disambiguate homonyms in context. However, as they rely heavily on context, these models fail at representing words with different senses when occurring in similar sentences. Experiments are performed in Galician, Portuguese, English, and Spanish, and both the dataset (with more than 3,000 evaluation items) and new models are freely released with this study.