 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Apr 02, 2024



Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
The Parallel Meaning Bank: Towards a Multilingual Corpus of Translations Annotated with Compositional Meaning Representations
Feb 13, 2017
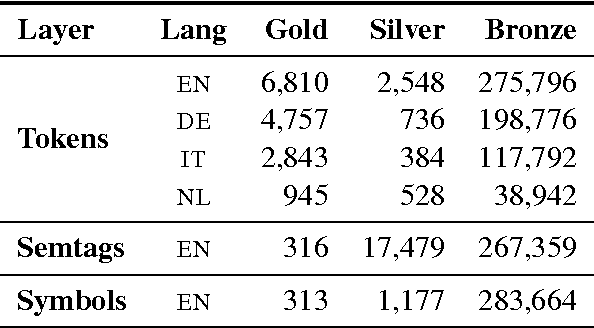
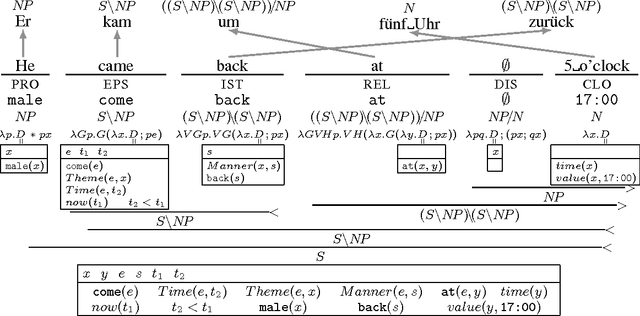
The Parallel Meaning Bank is a corpus of translations annotated with shared, formal meaning representations comprising over 11 million words divided over four languages (English, German, Italian, and Dutch). Our approach is based on cross-lingual projection: automatically produced (and manually corrected) semantic annotations for English sentences are mapped onto their word-aligned translations, assuming that the translations are meaning-preserving. The semantic annotation consists of five main steps: (i) segmentation of the text in sentences and lexical items; (ii) syntactic parsing with Combinatory Categorial Grammar; (iii) universal semantic tagging; (iv) symbolization; and (v) compositional semantic analysis based on Discourse Representation Theory. These steps are performed using statistical models trained in a semi-supervised manner. The employed annotation models are all language-neutral. Our first results are promising.
TuLiPA: Towards a Multi-Formalism Parsing Environment for Grammar Engineering
Jul 23, 2008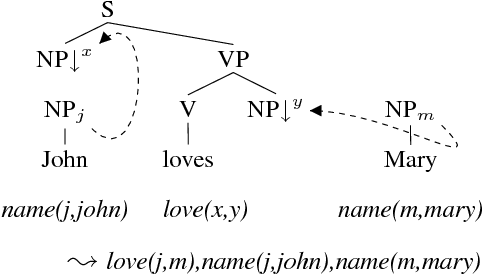
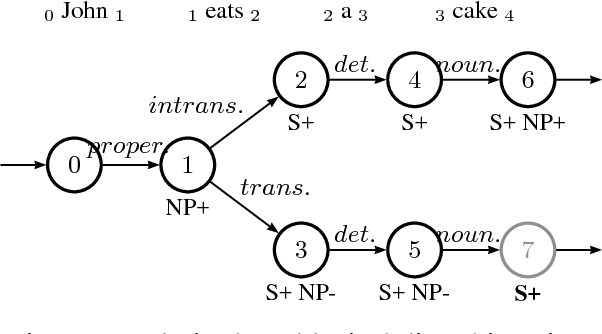
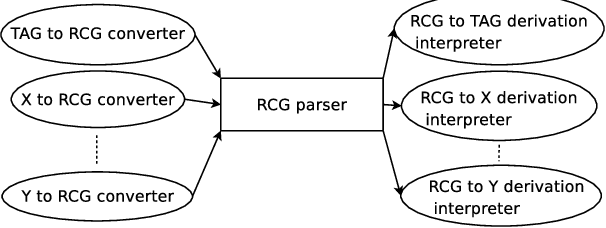

In this paper, we present an open-source parsing environment (Tuebingen Linguistic Parsing Architecture, TuLiPA) which uses Range Concatenation Grammar (RCG) as a pivot formalism, thus opening the way to the parsing of several mildly context-sensitive formalisms. This environment currently supports tree-based grammars (namely Tree-Adjoining Grammars, TAG) and Multi-Component Tree-Adjoining Grammars with Tree Tuples (TT-MCTAG)) and allows computation not only of syntactic structures, but also of the corresponding semantic representations. It is used for the development of a tree-based grammar for German.