 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMI_SU_Yotkova_Kastreva at SemEval-2026 Task 13: Lightweight Detection of LLM-Generated Code via Stylometric Signals
May 05, 2026SemEval-2026 Task 13 investigates machine-generated code detection across multiple programming languages and application scenarios, asking participating systems to generalize to unseen languages and domains. This paper describes our participation in Subtask A (binary classification) and explores both pretrained code encoders and lightweight feature-based methods. We design ratio-based features that are less sensitive to snippet length. To support the extraction of descriptiveness-related signals, we use parsing engines and a programming-language classifier. Additionally, we train a separate code-vs-text line classifier to identify raw natural language segments embedded within samples. We combine a shallow decision tree with heuristic rules derived from data analysis to produce the final predictions. Our approach is computationally efficient, requires only CPU resources for training, and achieves near-instant inference time, offering a lightweight alternative to large pretrained models.
The CLEF-2026 FinMMEval Lab: Multilingual and Multimodal Evaluation of Financial AI Systems
Feb 11, 2026We present the setup and the tasks of the FinMMEval Lab at CLEF 2026, which introduces the first multilingual and multimodal evaluation framework for financial Large Language Models (LLMs). While recent advances in financial natural language processing have enabled automated analysis of market reports, regulatory documents, and investor communications, existing benchmarks remain largely monolingual, text-only, and limited to narrow subtasks. FinMMEval 2026 addresses this gap by offering three interconnected tasks that span financial understanding, reasoning, and decision-making: Financial Exam Question Answering, Multilingual Financial Question Answering (PolyFiQA), and Financial Decision Making. Together, these tasks provide a comprehensive evaluation suite that measures models' ability to reason, generalize, and act across diverse languages and modalities. The lab aims to promote the development of robust, transparent, and globally inclusive financial AI systems, with datasets and evaluation resources publicly released to support reproducible research.
MemeLens: Multilingual Multitask VLMs for Memes
Jan 18, 2026Memes are a dominant medium for online communication and manipulation because meaning emerges from interactions between embedded text, imagery, and cultural context. Existing meme research is distributed across tasks (hate, misogyny, propaganda, sentiment, humour) and languages, which limits cross-domain generalization. To address this gap we propose MemeLens, a unified multilingual and multitask explanation-enhanced Vision Language Model (VLM) for meme understanding. We consolidate 38 public meme datasets, filter and map dataset-specific labels into a shared taxonomy of $20$ tasks spanning harm, targets, figurative/pragmatic intent, and affect. We present a comprehensive empirical analysis across modeling paradigms, task categories, and datasets. Our findings suggest that robust meme understanding requires multimodal training, exhibits substantial variation across semantic categories, and remains sensitive to over-specialization when models are fine-tuned on individual datasets rather than trained in a unified setting. We will make the experimental resources and datasets publicly available for the community.
Atomic Action Slicing: Planner-Aligned Options for Generalist VLA Agents
Dec 12, 2025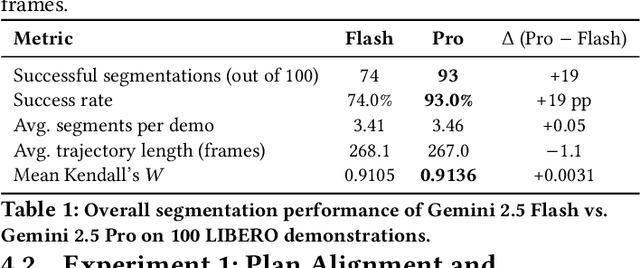

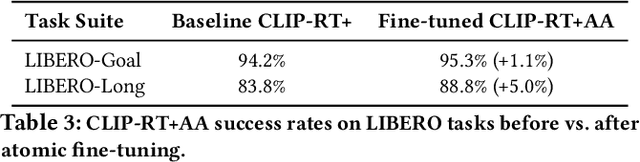
Current vision-language-action (VLA) models generalize poorly, particularly when tasks require new compositions of skills or objects. We introduce Atomic Action Slicing (AAS), a planner-aligned approach that decomposes long-horizon demonstrations into short, typed atomic actions that are easier for planners to use and policies to learn. Using LIBERO demonstrations, AAS produces a validated dataset of 2,124 atomic segments labeled with action type, temporal span, and confidence. A stronger segmenter (Gemini 2.5 Pro) closely matches planner-defined plans and remains robust under keyframe jitter, while smaller models perform worse on multi-object tasks. Fine-tuning CLIP-RT+ on our atomic dataset improves task success from 94.2% to 95.3% on LIBERO-Goal and 83.8% to 88.8% on LIBERO-Long. We publicly release the GATE-VLAP dataset on HuggingFace(https://huggingface.co/datasets/gate-institute/GATE-VLAP-datasets)
FRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
Entity Framing and Role Portrayal in the News
Feb 20, 2025



We introduce a novel multilingual hierarchical corpus annotated for entity framing and role portrayal in news articles. The dataset uses a unique taxonomy inspired by storytelling elements, comprising 22 fine-grained roles, or archetypes, nested within three main categories: protagonist, antagonist, and innocent. Each archetype is carefully defined, capturing nuanced portrayals of entities such as guardian, martyr, and underdog for protagonists; tyrant, deceiver, and bigot for antagonists; and victim, scapegoat, and exploited for innocents. The dataset includes 1,378 recent news articles in five languages (Bulgarian, English, Hindi, European Portuguese, and Russian) focusing on two critical domains of global significance: the Ukraine-Russia War and Climate Change. Over 5,800 entity mentions have been annotated with role labels. This dataset serves as a valuable resource for research into role portrayal and has broader implications for news analysis. We describe the characteristics of the dataset and the annotation process, and we report evaluation results on fine-tuned state-of-the-art multilingual transformers and hierarchical zero-shot learning using LLMs at the level of a document, a paragraph, and a sentence.
Post-OCR Text Correction for Bulgarian Historical Documents
Aug 31, 2024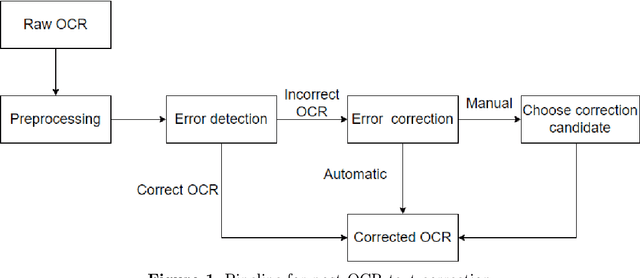



The digitization of historical documents is crucial for preserving the cultural heritage of the society. An important step in this process is converting scanned images to text using Optical Character Recognition (OCR), which can enable further search, information extraction, etc. Unfortunately, this is a hard problem as standard OCR tools are not tailored to deal with historical orthography as well as with challenging layouts. Thus, it is standard to apply an additional text correction step on the OCR output when dealing with such documents. In this work, we focus on Bulgarian, and we create the first benchmark dataset for evaluating the OCR text correction for historical Bulgarian documents written in the first standardized Bulgarian orthography: the Drinov orthography from the 19th century. We further develop a method for automatically generating synthetic data in this orthography, as well as in the subsequent Ivanchev orthography, by leveraging vast amounts of contemporary literature Bulgarian texts. We then use state-of-the-art LLMs and encoder-decoder framework which we augment with diagonal attention loss and copy and coverage mechanisms to improve the post-OCR text correction. The proposed method reduces the errors introduced during recognition and improves the quality of the documents by 25\%, which is an increase of 16\% compared to the state-of-the-art on the ICDAR 2019 Bulgarian dataset. We release our data and code at \url{https://github.com/angelbeshirov/post-ocr-text-correction}.}
Dissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Apr 02, 2024



Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
Gpachov at CheckThat! 2023: A Diverse Multi-Approach Ensemble for Subjectivity Detection in News Articles
Sep 13, 2023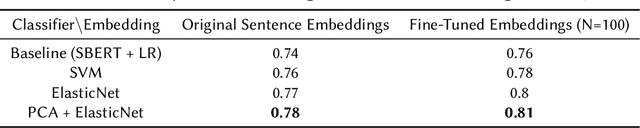
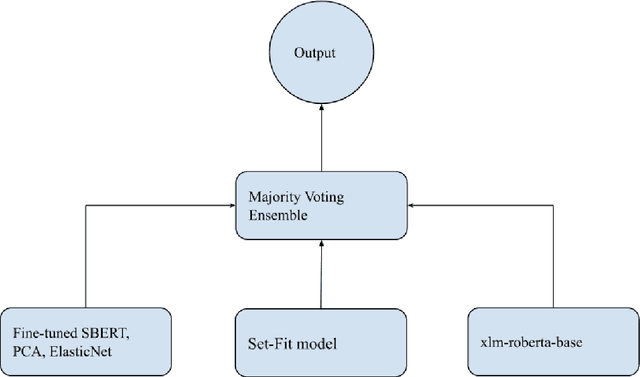
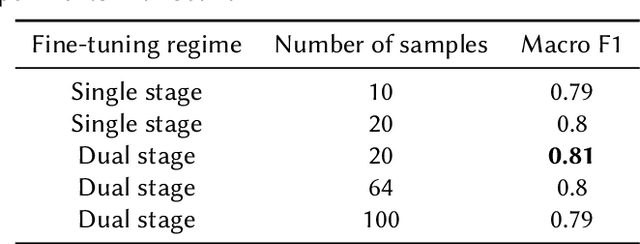
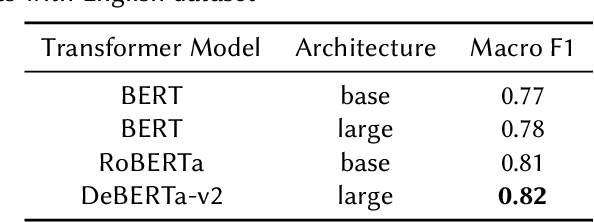
The wide-spread use of social networks has given rise to subjective, misleading, and even false information on the Internet. Thus, subjectivity detection can play an important role in ensuring the objectiveness and the quality of a piece of information. This paper presents the solution built by the Gpachov team for the CLEF-2023 CheckThat! lab Task~2 on subjectivity detection. Three different research directions are explored. The first one is based on fine-tuning a sentence embeddings encoder model and dimensionality reduction. The second one explores a sample-efficient few-shot learning model. The third one evaluates fine-tuning a multilingual transformer on an altered dataset, using data from multiple languages. Finally, the three approaches are combined in a simple majority voting ensemble, resulting in 0.77 macro F1 on the test set and achieving 2nd place on the English subtask.
Detecting and Understanding Harmful Memes: A Survey
May 09, 2022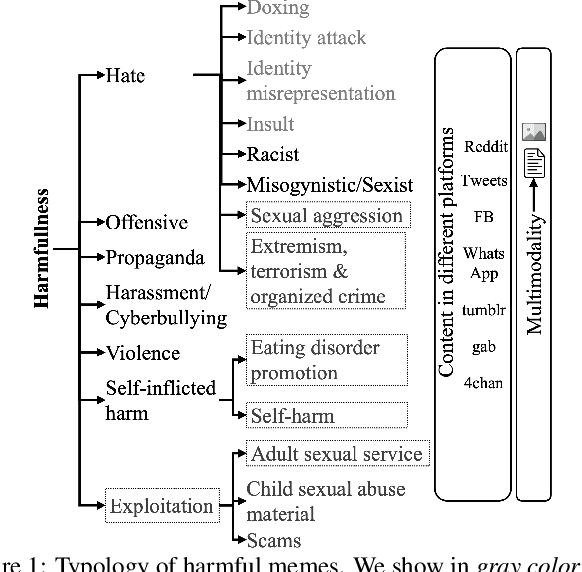
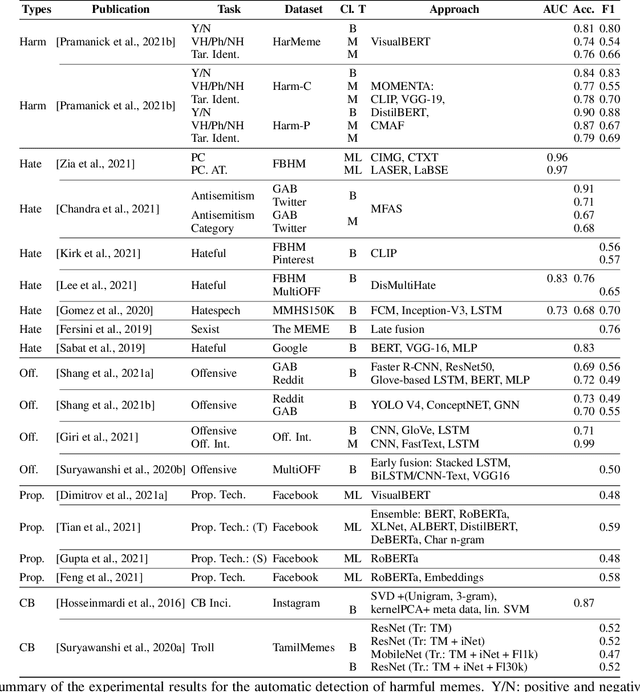

The automatic identification of harmful content online is of major concern for social media platforms, policymakers, and society. Researchers have studied textual, visual, and audio content, but typically in isolation. Yet, harmful content often combines multiple modalities, as in the case of memes, which are of particular interest due to their viral nature. With this in mind, here we offer a comprehensive survey with a focus on harmful memes. Based on a systematic analysis of recent literature, we first propose a new typology of harmful memes, and then we highlight and summarize the relevant state of the art. One interesting finding is that many types of harmful memes are not really studied, e.g., such featuring self-harm and extremism, partly due to the lack of suitable datasets. We further find that existing datasets mostly capture multi-class scenarios, which are not inclusive of the affective spectrum that memes can represent. Another observation is that memes can propagate globally through repackaging in different languages and that they can also be multilingual, blending different cultures. We conclude by highlighting several challenges related to multimodal semiotics, technological constraints and non-trivial social engagement, and we present several open-ended aspects such as delineating online harm and empirically examining related frameworks and assistive interventions, which we believe will motivate and drive future research.