 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fine-Tuning for In-Context Retrieval and Efficient KV-Caching in Long-Context Language Models
Jan 26, 2026With context windows of millions of tokens, Long-Context Language Models (LCLMs) can encode entire document collections, offering a strong alternative to conventional retrieval-augmented generation (RAG). However, it remains unclear whether fine-tuning strategies can improve long-context performance and translate to greater robustness under KV-cache compression techniques. In this work, we investigate which training strategies most effectively enhance LCLMs' ability to identify and use relevant information, as well as enhancing their robustness under KV-cache compression. Our experiments show substantial in-domain improvements, achieving gains of up to +20 points over the base model. However, out-of-domain generalization remains task dependent with large variance -- LCLMs excels on finance questions (+9 points), while RAG shows stronger performance on multiple-choice questions (+6 points) over the baseline models. Finally, we show that our fine-tuning approaches bring moderate improvements in robustness under KV-cache compression, with gains varying across tasks.
Correct, Concise and Complete: Multi-stage Training For Adaptive Reasoning
Jan 06, 2026The reasoning capabilities of large language models (LLMs) have improved substantially through increased test-time computation, typically in the form of intermediate tokens known as chain-of-thought (CoT). However, CoT often becomes unnecessarily long, increasing computation cost without actual accuracy gains or sometimes even degrading performance, a phenomenon known as ``overthinking''. We propose a multi-stage efficient reasoning method that combines supervised fine-tuning -- via rejection sampling or reasoning trace reformatting -- with reinforcement learning using an adaptive length penalty. We introduce a lightweight reward function that penalizes tokens generated after the first correct answer but encouraging self-verification only when beneficial. We conduct a holistic evaluation across seven diverse reasoning tasks, analyzing the accuracy-response length trade-off. Our approach reduces response length by an average of 28\% for 8B models and 40\% for 32B models, while incurring only minor performance drops of 1.6 and 2.5 points, respectively. Despite its conceptual simplicity, it achieves a superior trade-off compared to more complex state-of-the-art efficient reasoning methods, scoring 76.6, in terms of the area under the Overthinking-Adjusted Accuracy curve ($\text{AUC}_{\text{OAA}}$) -- 5 points above the base model and 2.5 points above the second-best approach.
Post-OCR Text Correction for Bulgarian Historical Documents
Aug 31, 2024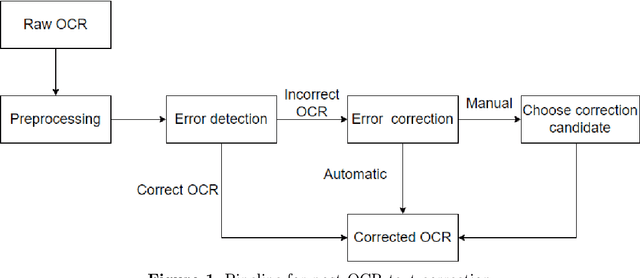



The digitization of historical documents is crucial for preserving the cultural heritage of the society. An important step in this process is converting scanned images to text using Optical Character Recognition (OCR), which can enable further search, information extraction, etc. Unfortunately, this is a hard problem as standard OCR tools are not tailored to deal with historical orthography as well as with challenging layouts. Thus, it is standard to apply an additional text correction step on the OCR output when dealing with such documents. In this work, we focus on Bulgarian, and we create the first benchmark dataset for evaluating the OCR text correction for historical Bulgarian documents written in the first standardized Bulgarian orthography: the Drinov orthography from the 19th century. We further develop a method for automatically generating synthetic data in this orthography, as well as in the subsequent Ivanchev orthography, by leveraging vast amounts of contemporary literature Bulgarian texts. We then use state-of-the-art LLMs and encoder-decoder framework which we augment with diagonal attention loss and copy and coverage mechanisms to improve the post-OCR text correction. The proposed method reduces the errors introduced during recognition and improves the quality of the documents by 25\%, which is an increase of 16\% compared to the state-of-the-art on the ICDAR 2019 Bulgarian dataset. We release our data and code at \url{https://github.com/angelbeshirov/post-ocr-text-correction}.}
DEM: Distribution Edited Model for Training with Mixed Data Distributions
Jun 21, 2024



Training with mixed data distributions is a common and important part of creating multi-task and instruction-following models. The diversity of the data distributions and cost of joint training makes the optimization procedure extremely challenging. Data mixing methods partially address this problem, albeit having a sub-optimal performance across data sources and require multiple expensive training runs. In this paper, we propose a simple and efficient alternative for better optimization of the data sources by combining models individually trained on each data source with the base model using basic element-wise vector operations. The resulting model, namely Distribution Edited Model (DEM), is 11x cheaper than standard data mixing and outperforms strong baselines on a variety of benchmarks, yielding up to 6.2% improvement on MMLU, 11.5% on BBH, 16.1% on DROP, and 9.3% on HELM with models of size 3B to 13B. Notably, DEM does not require full re-training when modifying a single data-source, thus making it very flexible and scalable for training with diverse data sources.
Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Jun 19, 2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023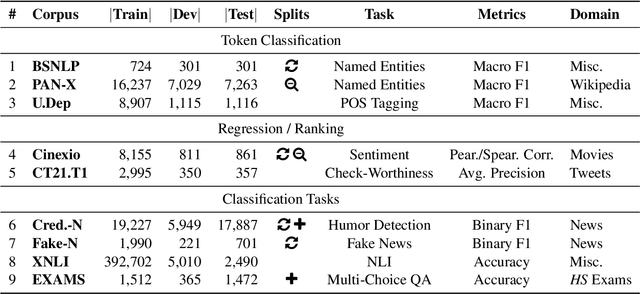
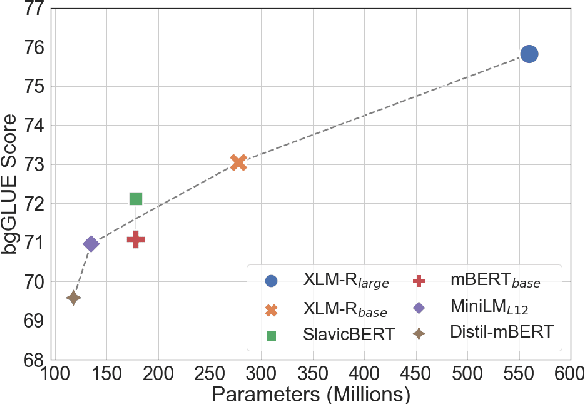

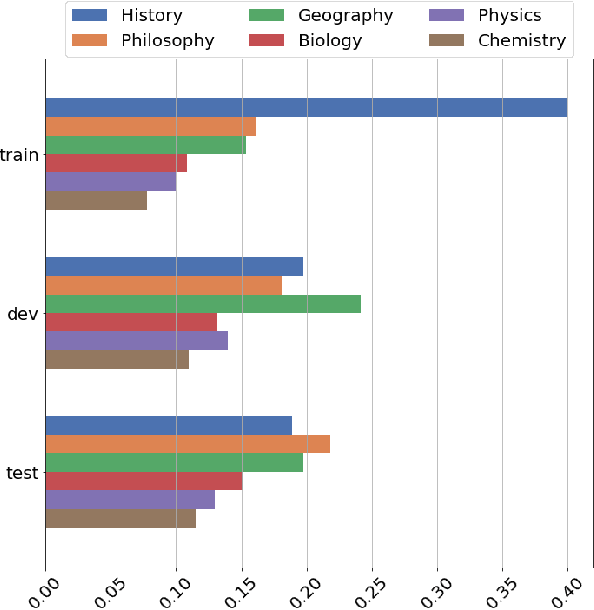
We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Diable: Efficient Dialogue State Tracking as Operations on Tables
May 26, 2023Sequence-to-sequence state-of-the-art systems for dialogue state tracking (DST) use the full dialogue history as input, represent the current state as a list with all the slots, and generate the entire state from scratch at each dialogue turn. This approach is inefficient, especially when the number of slots is large and the conversation is long. In this paper, we propose Diable, a new task formalisation that simplifies the design and implementation of efficient DST systems and allows one to easily plug and play large language models. We represent the dialogue state as a table and formalise DST as a table manipulation task. At each turn, the system updates the previous state by generating table operations based on the dialogue context. Extensive experimentation on the MultiWoz datasets demonstrates that Diable (i) outperforms strong efficient DST baselines, (ii) is 2.4x more time efficient than current state-of-the-art methods while retaining competitive Joint Goal Accuracy, and (iii) is robust to noisy data annotations due to the table operations approach.
CrowdChecked: Detecting Previously Fact-Checked Claims in Social Media
Oct 10, 2022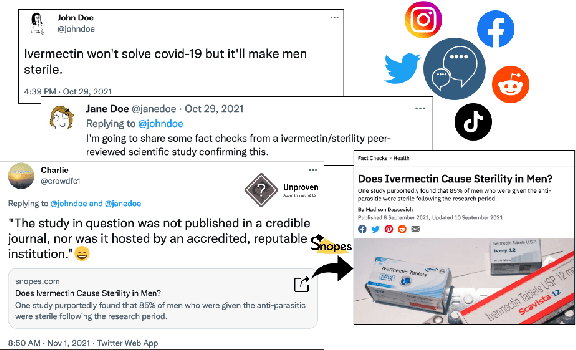
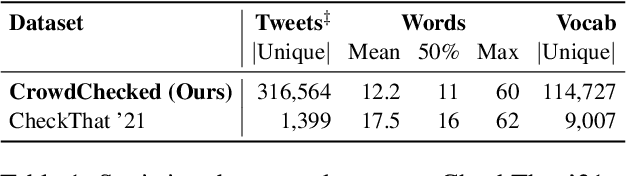
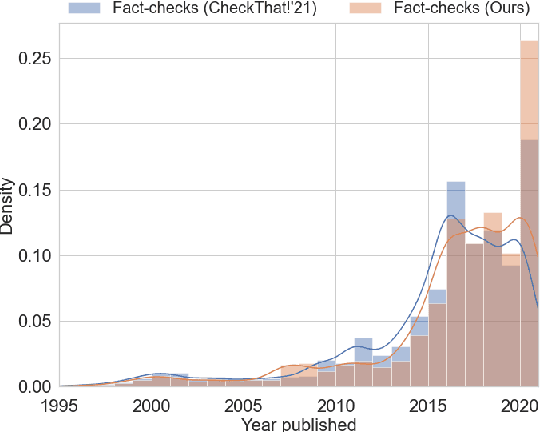
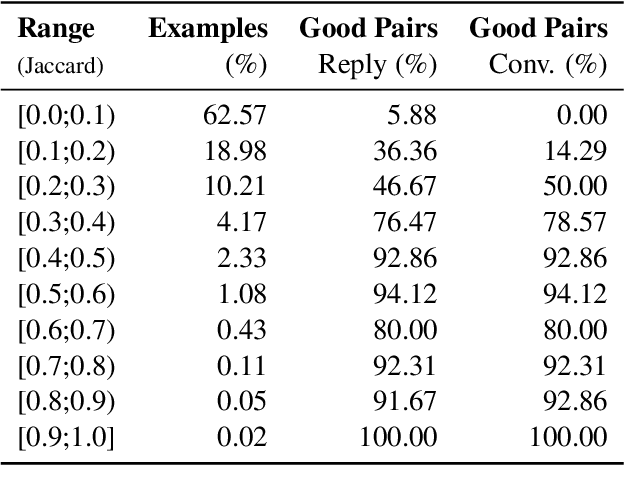
While there has been substantial progress in developing systems to automate fact-checking, they still lack credibility in the eyes of the users. Thus, an interesting approach has emerged: to perform automatic fact-checking by verifying whether an input claim has been previously fact-checked by professional fact-checkers and to return back an article that explains their decision. This is a sensible approach as people trust manual fact-checking, and as many claims are repeated multiple times. Yet, a major issue when building such systems is the small number of known tweet--verifying article pairs available for training. Here, we aim to bridge this gap by making use of crowd fact-checking, i.e., mining claims in social media for which users have responded with a link to a fact-checking article. In particular, we mine a large-scale collection of 330,000 tweets paired with a corresponding fact-checking article. We further propose an end-to-end framework to learn from this noisy data based on modified self-adaptive training, in a distant supervision scenario. Our experiments on the CLEF'21 CheckThat! test set show improvements over the state of the art by two points absolute. Our code and datasets are available at https://github.com/mhardalov/crowdchecked-claims
* Accepted to AACL-IJCNLP 2022 (Main Conference)
Leaf: Multiple-Choice Question Generation
Jan 22, 2022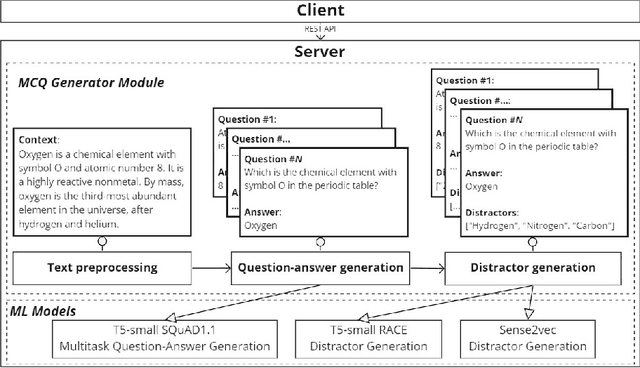
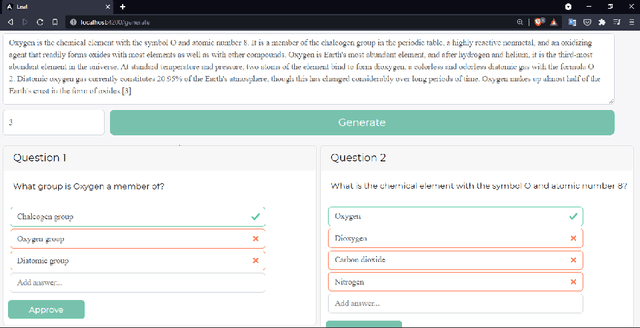
Testing with quiz questions has proven to be an effective way to assess and improve the educational process. However, manually creating quizzes is tedious and time-consuming. To address this challenge, we present Leaf, a system for generating multiple-choice questions from factual text. In addition to being very well suited for the classroom, Leaf could also be used in an industrial setting, e.g., to facilitate onboarding and knowledge sharing, or as a component of chatbots, question answering systems, or Massive Open Online Courses (MOOCs). The code and the demo are available on https://github.com/KristiyanVachev/Leaf-Question-Generation.
SUper Team at SemEval-2016 Task 3: Building a feature-rich system for community question answering
Sep 26, 2021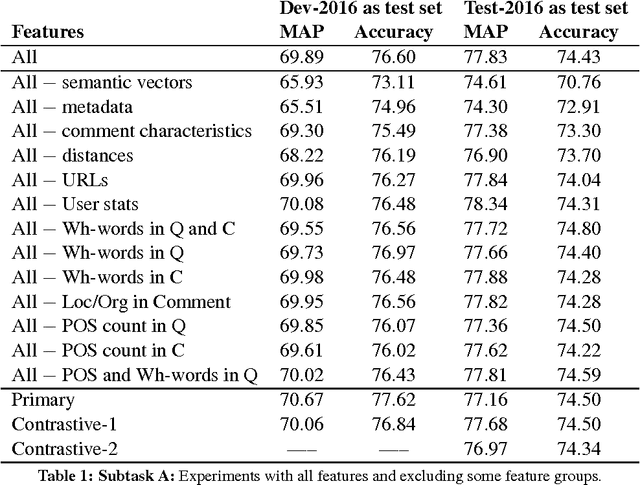
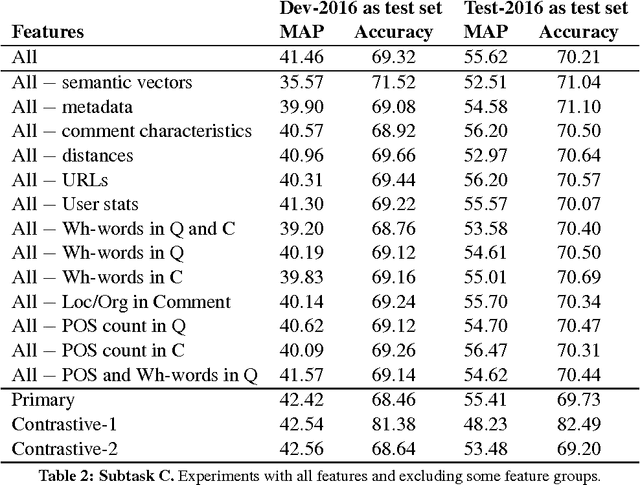
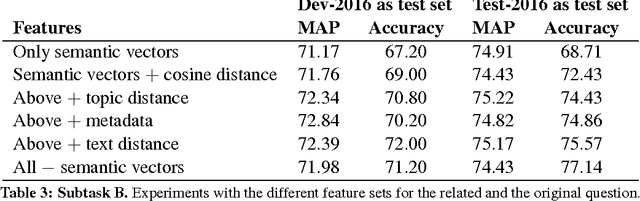
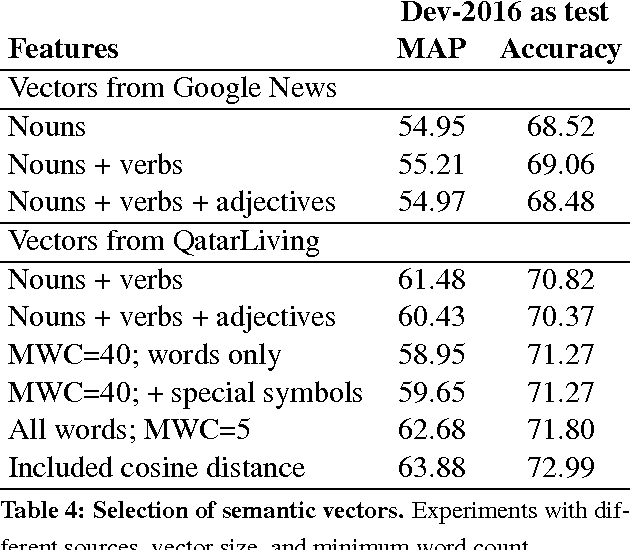
We present the system we built for participating in SemEval-2016 Task 3 on Community Question Answering. We achieved the best results on subtask C, and strong results on subtasks A and B, by combining a rich set of various types of features: semantic, lexical, metadata, and user-related. The most important group turned out to be the metadata for the question and for the comment, semantic vectors trained on QatarLiving data and similarities between the question and the comment for subtasks A and C, and between the original and the related question for Subtask B.
* community question answering, question-question similarity, question-comment similarity, answer reranking