 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Jun 19, 2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
Jun 14, 2022


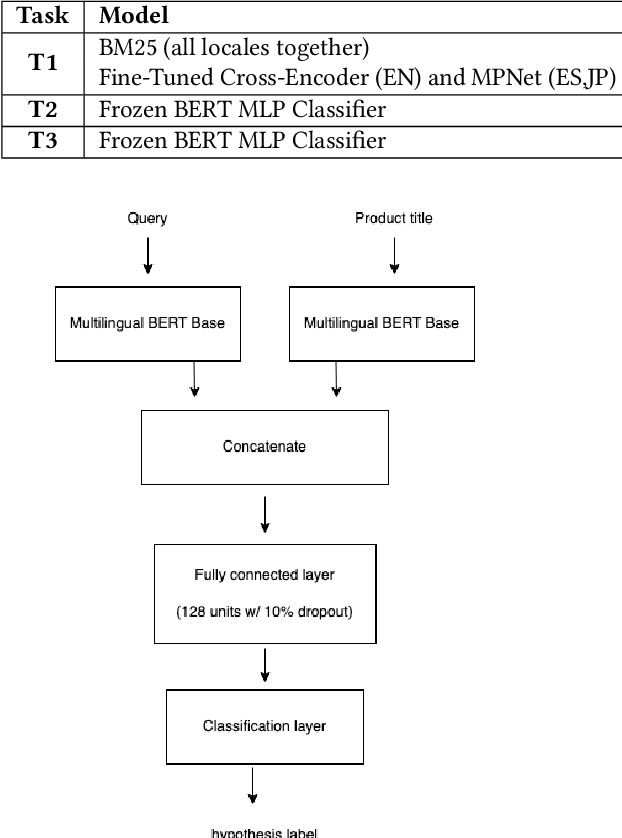
Improving the quality of search results can significantly enhance users experience and engagement with search engines. In spite of several recent advancements in the fields of machine learning and data mining, correctly classifying items for a particular user search query has been a long-standing challenge, which still has a large room for improvement. This paper introduces the "Shopping Queries Dataset", a large dataset of difficult Amazon search queries and results, publicly released with the aim of fostering research in improving the quality of search results. The dataset contains around 130 thousand unique queries and 2.6 million manually labeled (query,product) relevance judgements. The dataset is multilingual with queries in English, Japanese, and Spanish. The Shopping Queries Dataset is being used in one of the KDDCup'22 challenges. In this paper, we describe the dataset and present three evaluation tasks along with baseline results: (i) ranking the results list, (ii) classifying product results into relevance categories, and (iii) identifying substitute products for a given query. We anticipate that this data will become the gold standard for future research in the topic of product search.
Tailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction
May 03, 2020
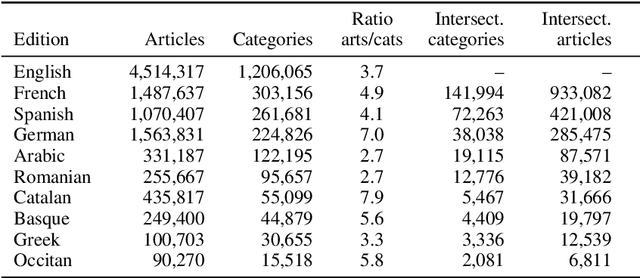
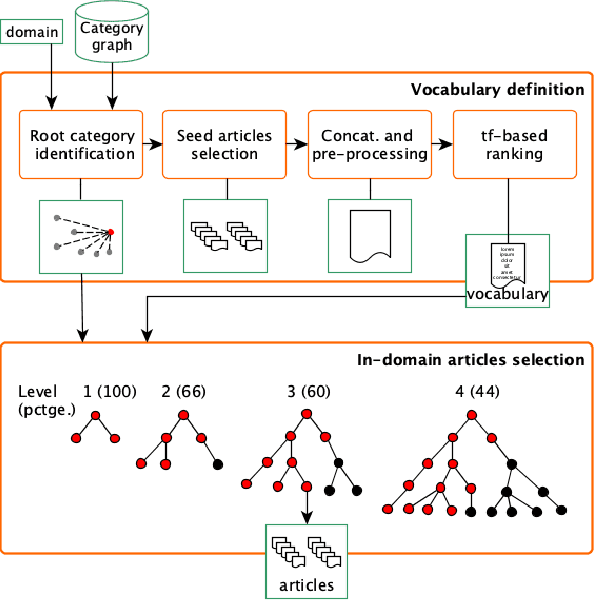
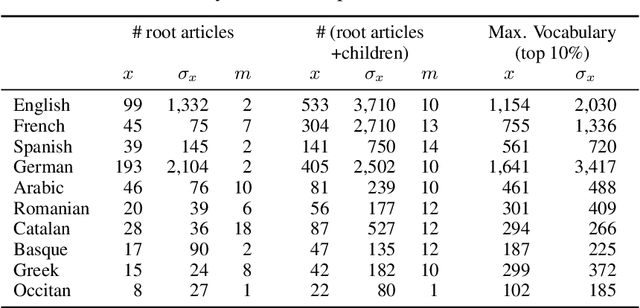
We propose an automatic language-independent graph-based method to build \`a-la-carte article collections on user-defined domains from the Wikipedia. The core model is based on the exploration of the encyclopaedia's category graph and can produce both monolingual and multilingual comparable collections. We run thorough experiments to assess the quality of the obtained corpora in 10 languages and 743 domains. According to an extensive manual evaluation, our graph-based model outperforms a retrieval-based approach and reaches an average precision of 84% on in-domain articles. As manual evaluations are costly, we introduce the concept of "domainness" and design several automatic metrics to account for the quality of the collections. Our best metric for domainness shows a strong correlation with the human-judged precision, representing a reasonable automatic alternative to assess the quality of domain-specific corpora. We release the WikiTailor toolkit with the implementation of the extraction methods, the evaluation measures and several utilities. WikiTailor makes obtaining multilingual in-domain data from the Wikipedia easy.
A Context-Aware Approach for Detecting Check-Worthy Claims in Political Debates
Dec 14, 2019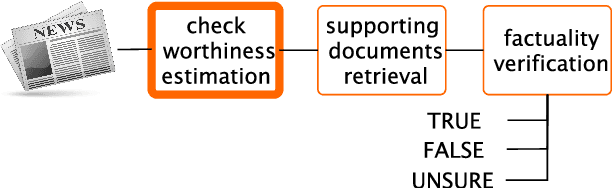
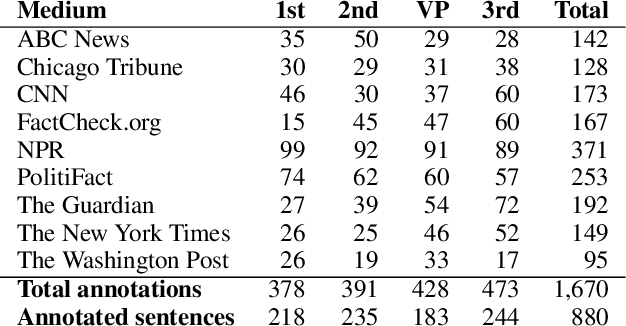
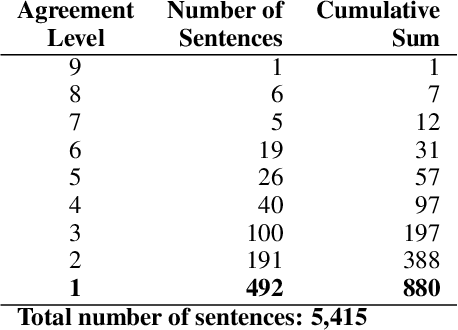

In the context of investigative journalism, we address the problem of automatically identifying which claims in a given document are most worthy and should be prioritized for fact-checking. Despite its importance, this is a relatively understudied problem. Thus, we create a new dataset of political debates, containing statements that have been fact-checked by nine reputable sources, and we train machine learning models to predict which claims should be prioritized for fact-checking, i.e., we model the problem as a ranking task. Unlike previous work, which has looked primarily at sentences in isolation, in this paper we focus on a rich input representation modeling the context: relationship between the target statement and the larger context of the debate, interaction between the opponents, and reaction by the moderator and by the public. Our experiments show state-of-the-art results, outperforming a strong rivaling system by a margin, while also confirming the importance of the contextual information.
* Check-worthiness; Fact-Checking; Veracity; Neural Networks. arXiv admin note: substantial text overlap with arXiv:1908.01328
Machine Translation Evaluation Meets Community Question Answering
Dec 06, 2019



We explore the applicability of machine translation evaluation (MTE) methods to a very different problem: answer ranking in community Question Answering. In particular, we adopt a pairwise neural network (NN) architecture, which incorporates MTE features, as well as rich syntactic and semantic embeddings, and which efficiently models complex non-linear interactions. The evaluation results show state-of-the-art performance, with sizeable contribution from both the MTE features and from the pairwise NN architecture.
* community question answering, machine translation evaluation, pairwise ranking, learning to rank
SemEval-2016 Task 3: Community Question Answering
Dec 03, 2019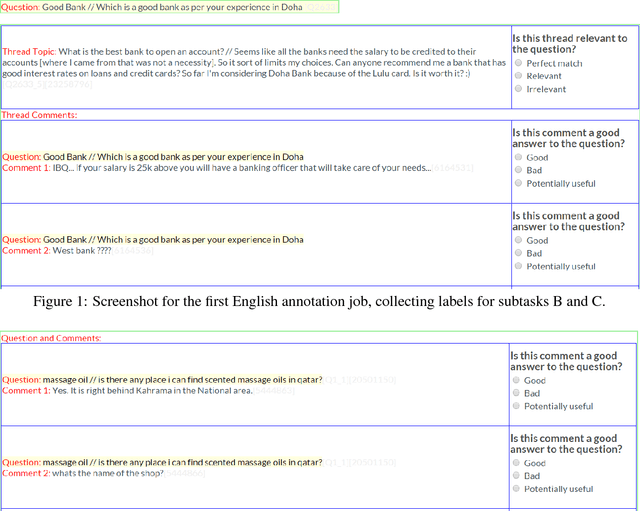
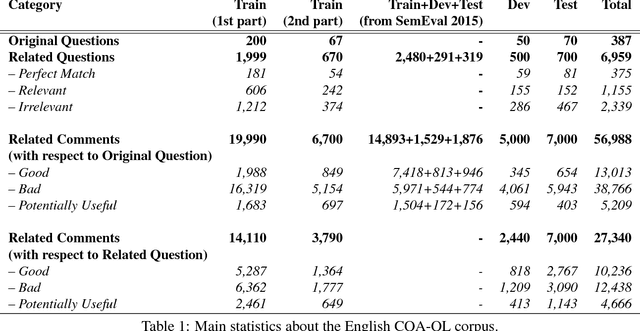
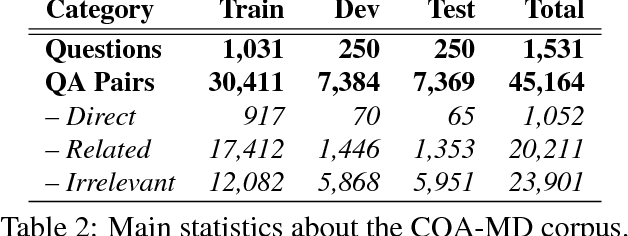
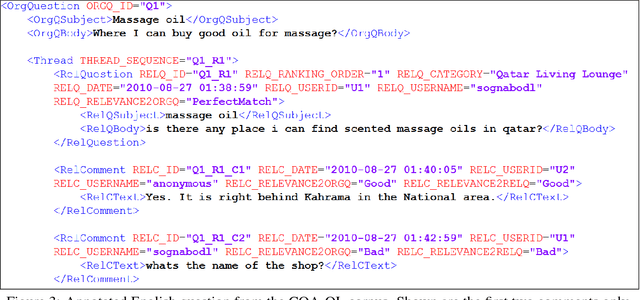
This paper describes the SemEval--2016 Task 3 on Community Question Answering, which we offered in English and Arabic. For English, we had three subtasks: Question--Comment Similarity (subtask A), Question--Question Similarity (B), and Question--External Comment Similarity (C). For Arabic, we had another subtask: Rerank the correct answers for a new question (D). Eighteen teams participated in the task, submitting a total of 95 runs (38 primary and 57 contrastive) for the four subtasks. A variety of approaches and features were used by the participating systems to address the different subtasks, which are summarized in this paper. The best systems achieved an official score (MAP) of 79.19, 76.70, 55.41, and 45.83 in subtasks A, B, C, and D, respectively. These scores are significantly better than those for the baselines that we provided. For subtask A, the best system improved over the 2015 winner by 3 points absolute in terms of Accuracy.
* community question answering, question-question similarity, question-comment similarity, answer reranking, English, Arabic. arXiv admin note: substantial text overlap with arXiv:1912.00730
SemEval-2017 Task 3: Community Question Answering
Dec 02, 2019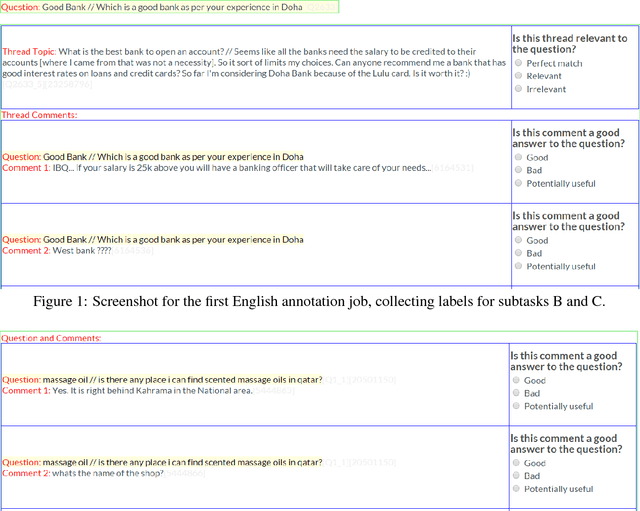
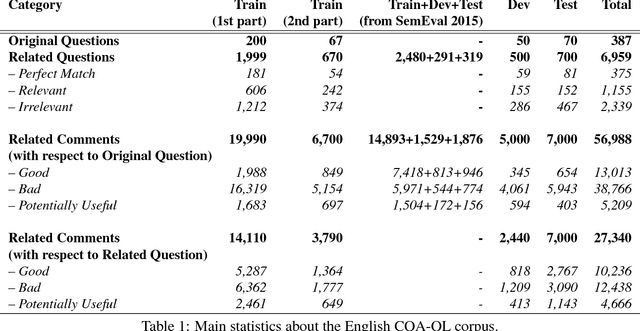

We describe SemEval-2017 Task 3 on Community Question Answering. This year, we reran the four subtasks from SemEval-2016:(A) Question-Comment Similarity,(B) Question-Question Similarity,(C) Question-External Comment Similarity, and (D) Rerank the correct answers for a new question in Arabic, providing all the data from 2015 and 2016 for training, and fresh data for testing. Additionally, we added a new subtask E in order to enable experimentation with Multi-domain Question Duplicate Detection in a larger-scale scenario, using StackExchange subforums. A total of 23 teams participated in the task, and submitted a total of 85 runs (36 primary and 49 contrastive) for subtasks A-D. Unfortunately, no teams participated in subtask E. A variety of approaches and features were used by the participating systems to address the different subtasks. The best systems achieved an official score (MAP) of 88.43, 47.22, 15.46, and 61.16 in subtasks A, B, C, and D, respectively. These scores are better than the baselines, especially for subtasks A-C.
* community question answering, question-question similarity, question-comment similarity, answer reranking, Multi-domain Question Duplicate Detection, StackExchange, English, Arabic
SemEval-2015 Task 3: Answer Selection in Community Question Answering
Nov 26, 2019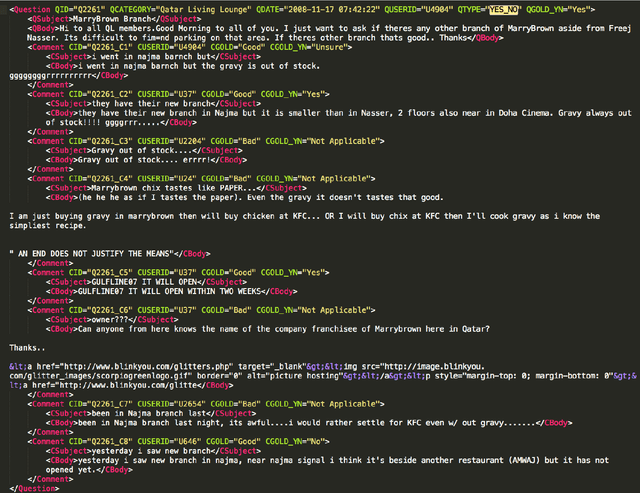
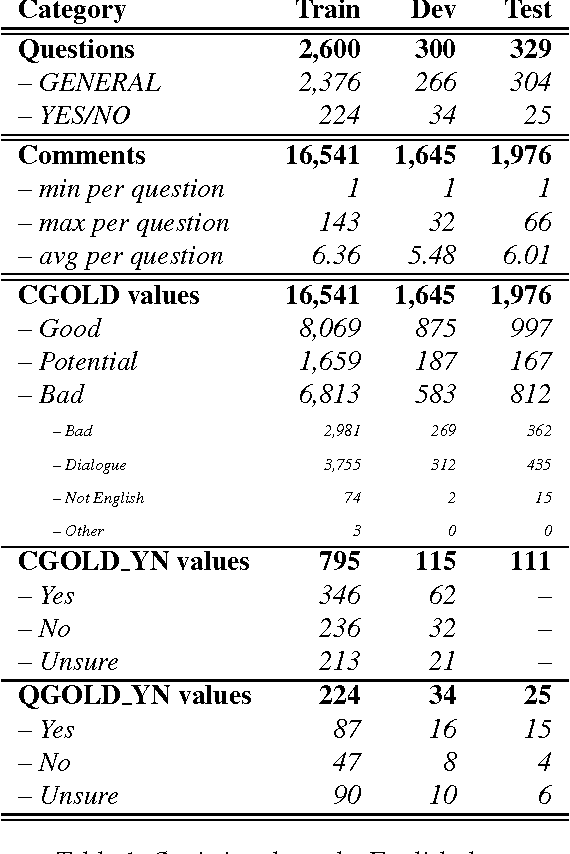
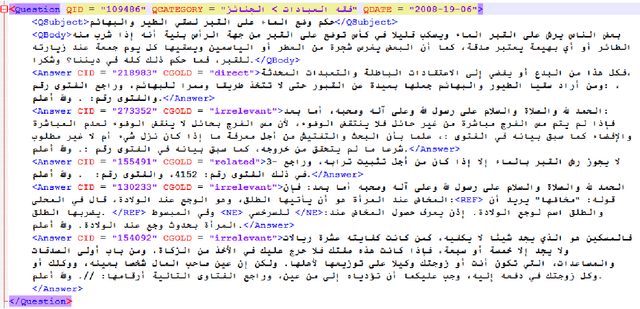
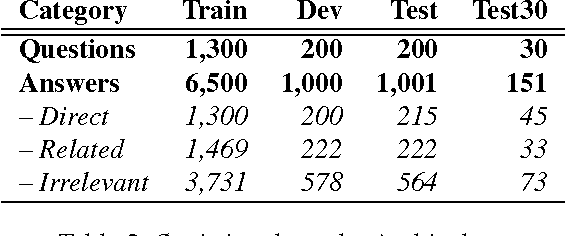
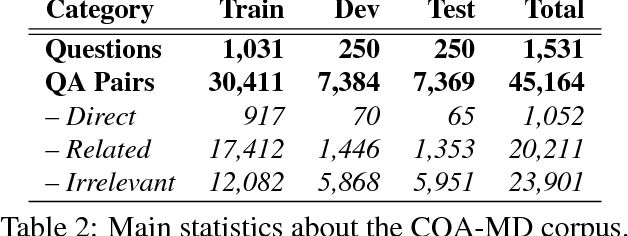
Community Question Answering (cQA) provides new interesting research directions to the traditional Question Answering (QA) field, e.g., the exploitation of the interaction between users and the structure of related posts. In this context, we organized SemEval-2015 Task 3 on "Answer Selection in cQA", which included two subtasks: (a) classifying answers as "good", "bad", or "potentially relevant" with respect to the question, and (b) answering a YES/NO question with "yes", "no", or "unsure", based on the list of all answers. We set subtask A for Arabic and English on two relatively different cQA domains, i.e., the Qatar Living website for English, and a Quran-related website for Arabic. We used crowdsourcing on Amazon Mechanical Turk to label a large English training dataset, which we released to the research community. Thirteen teams participated in the challenge with a total of 61 submissions: 24 primary and 37 contrastive. The best systems achieved an official score (macro-averaged F1) of 57.19 and 63.7 for the English subtasks A and B, and 78.55 for the Arabic subtask A.
* community question answering, answer selection, English, Arabic
Global Thread-Level Inference for Comment Classification in Community Question Answering
Nov 20, 2019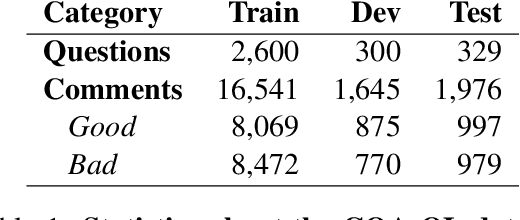

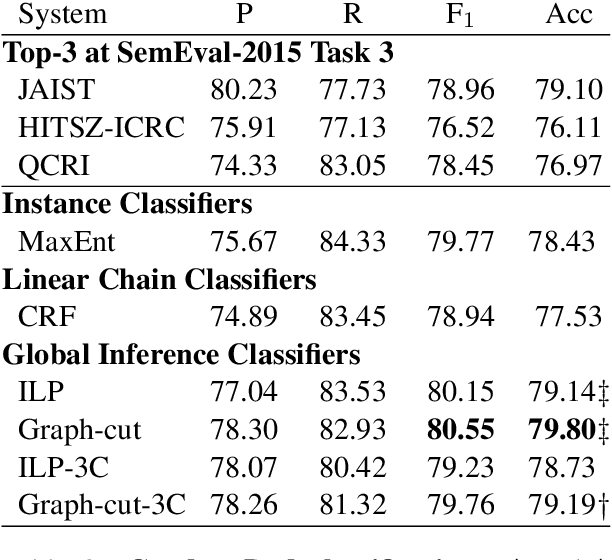
Community question answering, a recent evolution of question answering in the Web context, allows a user to quickly consult the opinion of a number of people on a particular topic, thus taking advantage of the wisdom of the crowd. Here we try to help the user by deciding automatically which answers are good and which are bad for a given question. In particular, we focus on exploiting the output structure at the thread level in order to make more consistent global decisions. More specifically, we exploit the relations between pairs of comments at any distance in the thread, which we incorporate in a graph-cut and in an ILP frameworks. We evaluated our approach on the benchmark dataset of SemEval-2015 Task 3. Results improved over the state of the art, confirming the importance of using thread level information.
* community question answering, thread-level inference, graph-cut, inductive logic programming
BookQA: Stories of Challenges and Opportunities
Oct 02, 2019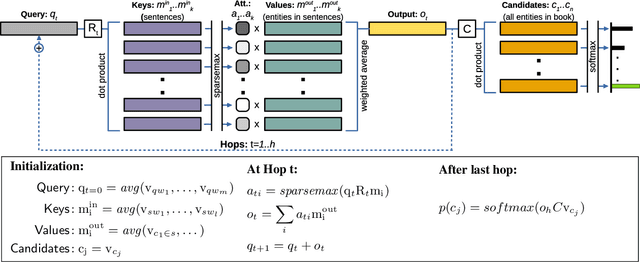
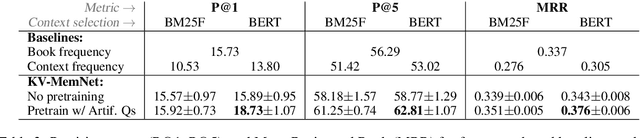
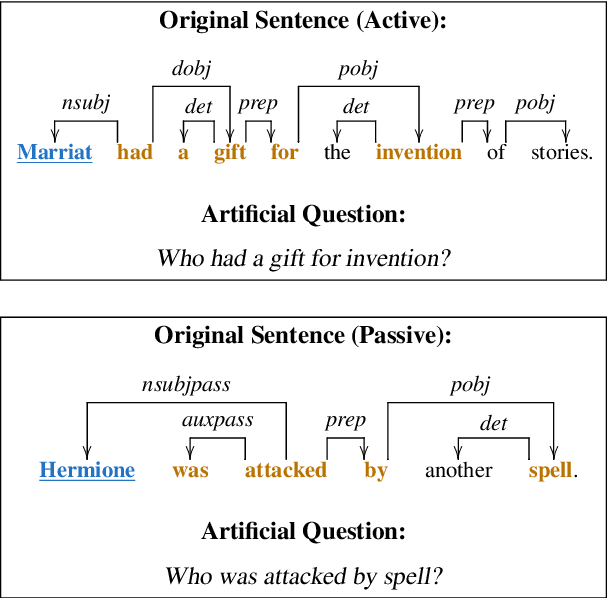
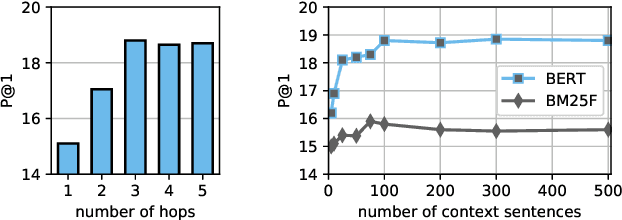
We present a system for answering questions based on the full text of books (BookQA), which first selects book passages given a question at hand, and then uses a memory network to reason and predict an answer. To improve generalization, we pretrain our memory network using artificial questions generated from book sentences. We experiment with the recently published NarrativeQA corpus, on the subset of Who questions, which expect book characters as answers. We experimentally show that BERT-based retrieval and pretraining improve over baseline results significantly. At the same time, we confirm that NarrativeQA is a highly challenging data set, and that there is need for novel research in order to achieve high-precision BookQA results. We analyze some of the bottlenecks of the current approach, and we argue that more research is needed on text representation, retrieval of relevant passages, and reasoning, including commonsense knowledge.