 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing the Arabic WordNet: Elevating Content Quality
Mar 29, 2024



High-quality WordNets are crucial for achieving high-quality results in NLP applications that rely on such resources. However, the wordnets of most languages suffer from serious issues of correctness and completeness with respect to the words and word meanings they define, such as incorrect lemmas, missing glosses and example sentences, or an inadequate, Western-centric representation of the morphology and the semantics of the language. Previous efforts have largely focused on increasing lexical coverage while ignoring other qualitative aspects. In this paper, we focus on the Arabic language and introduce a major revision of the Arabic WordNet that addresses multiple dimensions of lexico-semantic resource quality. As a result, we updated more than 58% of the synsets of the existing Arabic WordNet by adding missing information and correcting errors. In order to address issues of language diversity and untranslatability, we also extended the wordnet structure by new elements: phrasets and lexical gaps.
ArAIEval Shared Task: Persuasion Techniques and Disinformation Detection in Arabic Text
Nov 06, 2023



We present an overview of the ArAIEval shared task, organized as part of the first ArabicNLP 2023 conference co-located with EMNLP 2023. ArAIEval offers two tasks over Arabic text: (i) persuasion technique detection, focusing on identifying persuasion techniques in tweets and news articles, and (ii) disinformation detection in binary and multiclass setups over tweets. A total of 20 teams participated in the final evaluation phase, with 14 and 16 teams participating in Tasks 1 and 2, respectively. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further give a brief overview of the participating systems. All datasets and evaluation scripts from the shared task are released to the research community. (https://araieval.gitlab.io/) We hope this will enable further research on these important tasks in Arabic.
Lexical Diversity in Kinship Across Languages and Dialects
Aug 24, 2023



Languages are known to describe the world in diverse ways. Across lexicons, diversity is pervasive, appearing through phenomena such as lexical gaps and untranslatability. However, in computational resources, such as multilingual lexical databases, diversity is hardly ever represented. In this paper, we introduce a method to enrich computational lexicons with content relating to linguistic diversity. The method is verified through two large-scale case studies on kinship terminology, a domain known to be diverse across languages and cultures: one case study deals with seven Arabic dialects, while the other one with three Indonesian languages. Our results, made available as browseable and downloadable computational resources, extend prior linguistics research on kinship terminology, and provide insight into the extent of diversity even within linguistically and culturally close communities.
Using Linguistic Typology to Enrich Multilingual Lexicons: the Case of Lexical Gaps in Kinship
Apr 11, 2022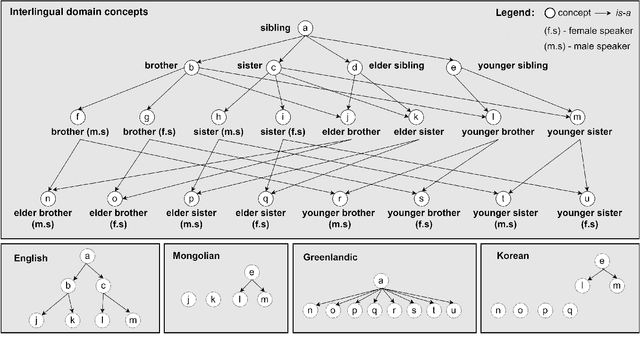
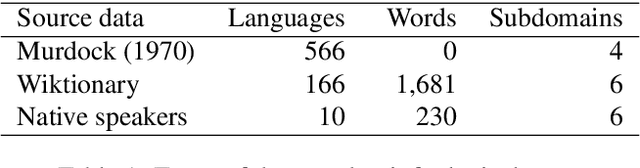
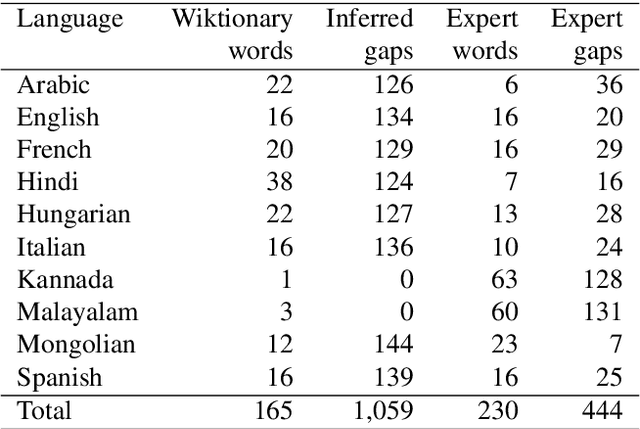

This paper describes a method to enrich lexical resources with content relating to linguistic diversity, based on knowledge from the field of lexical typology. We capture the phenomenon of diversity through the notions of lexical gap and language-specific word and use a systematic method to infer gaps semi-automatically on a large scale. As a first result obtained for the domain of kinship terminology, known to be very diverse throughout the world, we publish a lexico-semantic resource consisting of 198 domain concepts, 1,911 words, and 37,370 gaps covering 699 languages. We see potential in the use of resources such as ours for the improvement of a variety of cross-lingual NLP tasks, which we demonstrate through a downstream application for the evaluation of machine translation systems.
SemEval-2016 Task 3: Community Question Answering
Dec 03, 2019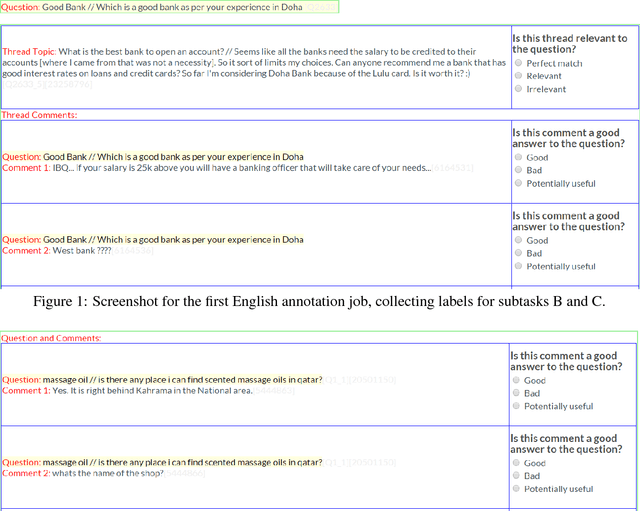
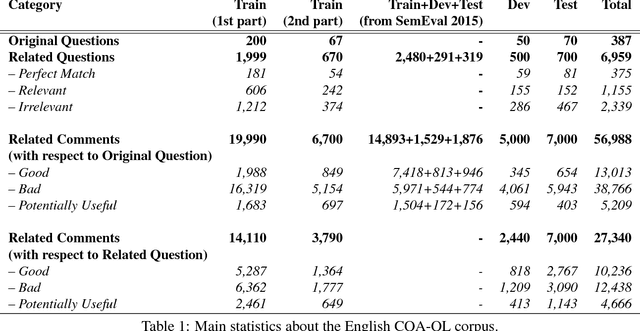
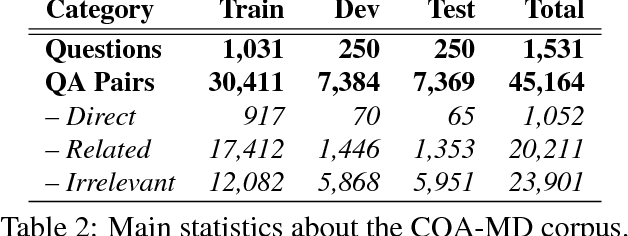
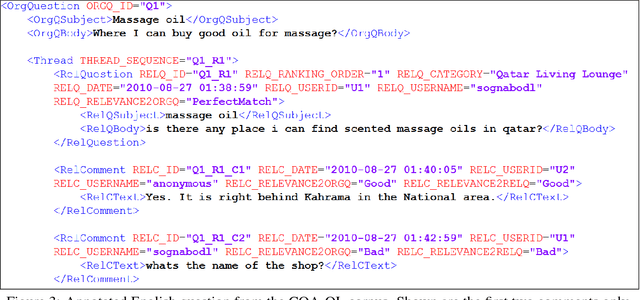
This paper describes the SemEval--2016 Task 3 on Community Question Answering, which we offered in English and Arabic. For English, we had three subtasks: Question--Comment Similarity (subtask A), Question--Question Similarity (B), and Question--External Comment Similarity (C). For Arabic, we had another subtask: Rerank the correct answers for a new question (D). Eighteen teams participated in the task, submitting a total of 95 runs (38 primary and 57 contrastive) for the four subtasks. A variety of approaches and features were used by the participating systems to address the different subtasks, which are summarized in this paper. The best systems achieved an official score (MAP) of 79.19, 76.70, 55.41, and 45.83 in subtasks A, B, C, and D, respectively. These scores are significantly better than those for the baselines that we provided. For subtask A, the best system improved over the 2015 winner by 3 points absolute in terms of Accuracy.
* community question answering, question-question similarity, question-comment similarity, answer reranking, English, Arabic. arXiv admin note: substantial text overlap with arXiv:1912.00730