 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayers of technology in pluriversal design. Decolonising language technology with the LiveLanguage initiative
May 02, 2024Language technology has the potential to facilitate intercultural communication through meaningful translations. However, the current state of language technology is deeply entangled with colonial knowledge due to path dependencies and neo-colonial tendencies in the global governance of artificial intelligence (AI). Language technology is a complex and emerging field that presents challenges for co-design interventions due to enfolding in assemblages of global scale and diverse sites and its knowledge intensity. This paper uses LiveLanguage, a lexical database, a set of services with particular emphasis on modelling language diversity and integrating small and minority languages, as an example to discuss and close the gap from pluriversal design theory to practice. By diversifying the concept of emerging technology, we can better approach language technology in global contexts. The paper presents a model comprising of five layers of technological activity. Each layer consists of specific practices and stakeholders, thus provides distinctive spaces for co-design interventions as mode of inquiry for de-linking, re-thinking and re-building language technology towards pluriversality. In that way, the paper contributes to reflecting the position of co-design in decolonising emergent technologies, and to integrating complex theoretical knowledge towards decoloniality into language technology design.
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
Apr 20, 2024



The popular subword tokenizers of current language models, such as Byte-Pair Encoding (BPE), are known not to respect morpheme boundaries, which affects the downstream performance of the models. While many improved tokenization algorithms have been proposed, their evaluation and cross-comparison is still an open problem. As a solution, we propose a combined intrinsic-extrinsic evaluation framework for subword tokenization. Intrinsic evaluation is based on our new UniMorph Labeller tool that classifies subword tokenization as either morphological or alien. Extrinsic evaluation, in turn, is performed via the Out-of-Vocabulary Generalization Challenge 1.0 benchmark, which consists of three newly specified downstream text classification tasks. Our empirical findings show that the accuracy of UniMorph Labeller is 98%, and that, in all language models studied (including ALBERT, BERT, RoBERTa, and DeBERTa), alien tokenization leads to poorer generalizations compared to morphological tokenization for semantic compositionality of word meanings.
Advancing the Arabic WordNet: Elevating Content Quality
Mar 29, 2024



High-quality WordNets are crucial for achieving high-quality results in NLP applications that rely on such resources. However, the wordnets of most languages suffer from serious issues of correctness and completeness with respect to the words and word meanings they define, such as incorrect lemmas, missing glosses and example sentences, or an inadequate, Western-centric representation of the morphology and the semantics of the language. Previous efforts have largely focused on increasing lexical coverage while ignoring other qualitative aspects. In this paper, we focus on the Arabic language and introduce a major revision of the Arabic WordNet that addresses multiple dimensions of lexico-semantic resource quality. As a result, we updated more than 58% of the synsets of the existing Arabic WordNet by adding missing information and correcting errors. In order to address issues of language diversity and untranslatability, we also extended the wordnet structure by new elements: phrasets and lexical gaps.
Lexical Diversity in Kinship Across Languages and Dialects
Aug 24, 2023



Languages are known to describe the world in diverse ways. Across lexicons, diversity is pervasive, appearing through phenomena such as lexical gaps and untranslatability. However, in computational resources, such as multilingual lexical databases, diversity is hardly ever represented. In this paper, we introduce a method to enrich computational lexicons with content relating to linguistic diversity. The method is verified through two large-scale case studies on kinship terminology, a domain known to be diverse across languages and cultures: one case study deals with seven Arabic dialects, while the other one with three Indonesian languages. Our results, made available as browseable and downloadable computational resources, extend prior linguistics research on kinship terminology, and provide insight into the extent of diversity even within linguistically and culturally close communities.
Diversity and Language Technology: How Techno-Linguistic Bias Can Cause Epistemic Injustice
Jul 25, 2023


It is well known that AI-based language technology -- large language models, machine translation systems, multilingual dictionaries, and corpora -- is currently limited to 2 to 3 percent of the world's most widely spoken and/or financially and politically best supported languages. In response, recent research efforts have sought to extend the reach of AI technology to ``underserved languages.'' In this paper, we show that many of these attempts produce flawed solutions that adhere to a hard-wired representational preference for certain languages, which we call techno-linguistic bias. Techno-linguistic bias is distinct from the well-established phenomenon of linguistic bias as it does not concern the languages represented but rather the design of the technologies. As we show through the paper, techno-linguistic bias can result in systems that can only express concepts that are part of the language and culture of dominant powers, unable to correctly represent concepts from other communities. We argue that at the root of this problem lies a systematic tendency of technology developer communities to apply a simplistic understanding of diversity which does not do justice to the more profound differences that languages, and ultimately the communities that speak them, embody. Drawing on the concept of epistemic injustice, we point to the broader sociopolitical consequences of the bias we identify and show how it can lead not only to a disregard for valuable aspects of diversity but also to an under-representation of the needs and diverse worldviews of marginalized language communities.
Towards Bridging the Digital Language Divide
Jul 25, 2023
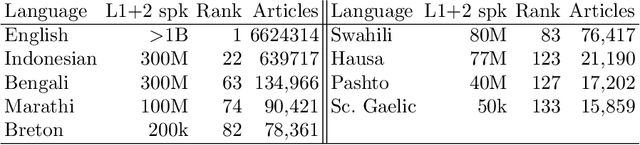


It is a well-known fact that current AI-based language technology -- language models, machine translation systems, multilingual dictionaries and corpora -- focuses on the world's 2-3% most widely spoken languages. Recent research efforts have attempted to expand the coverage of AI technology to `under-resourced languages.' The goal of our paper is to bring attention to a phenomenon that we call linguistic bias: multilingual language processing systems often exhibit a hardwired, yet usually involuntary and hidden representational preference towards certain languages. Linguistic bias is manifested in uneven per-language performance even in the case of similar test conditions. We show that biased technology is often the result of research and development methodologies that do not do justice to the complexity of the languages being represented, and that can even become ethically problematic as they disregard valuable aspects of diversity as well as the needs of the language communities themselves. As our attempt at building diversity-aware language resources, we present a new initiative that aims at reducing linguistic bias through both technological design and methodology, based on an eye-level collaboration with local communities.
The SIGMORPHON 2022 Shared Task on Morpheme Segmentation
Jun 15, 2022
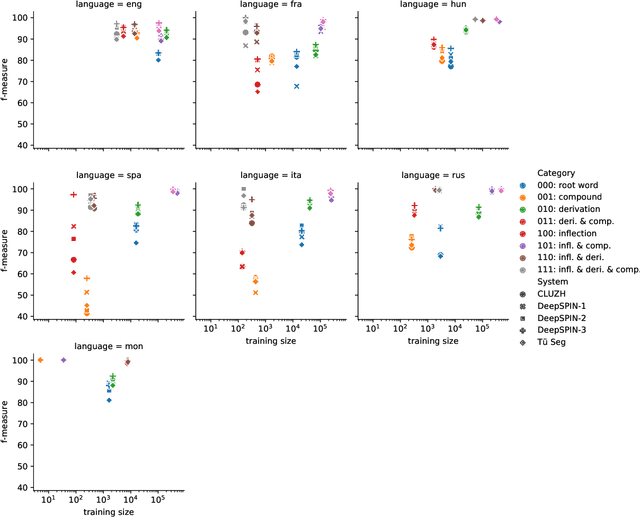
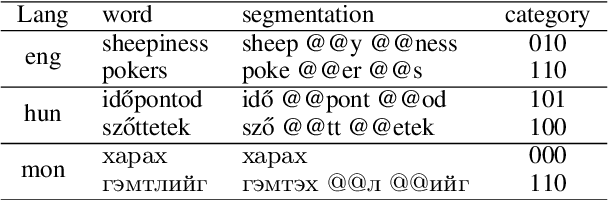
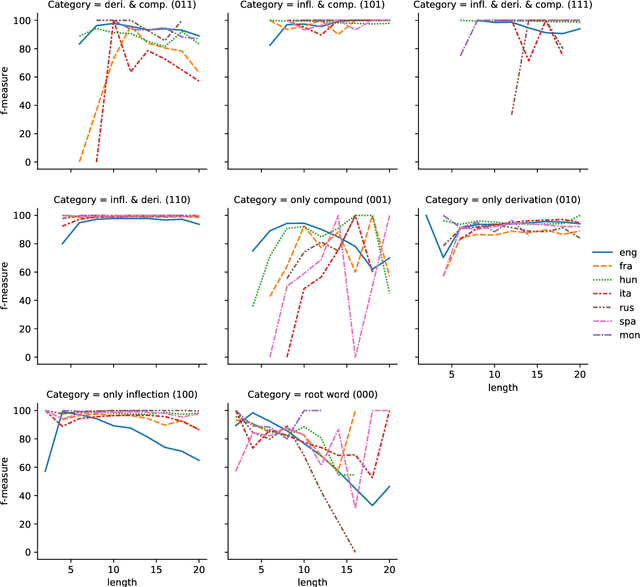
The SIGMORPHON 2022 shared task on morpheme segmentation challenged systems to decompose a word into a sequence of morphemes and covered most types of morphology: compounds, derivations, and inflections. Subtask 1, word-level morpheme segmentation, covered 5 million words in 9 languages (Czech, English, Spanish, Hungarian, French, Italian, Russian, Latin, Mongolian) and received 13 system submissions from 7 teams and the best system averaged 97.29% F1 score across all languages, ranging English (93.84%) to Latin (99.38%). Subtask 2, sentence-level morpheme segmentation, covered 18,735 sentences in 3 languages (Czech, English, Mongolian), received 10 system submissions from 3 teams, and the best systems outperformed all three state-of-the-art subword tokenization methods (BPE, ULM, Morfessor2) by 30.71% absolute. To facilitate error analysis and support any type of future studies, we released all system predictions, the evaluation script, and all gold standard datasets.
UniMorph 4.0: Universal Morphology
May 10, 2022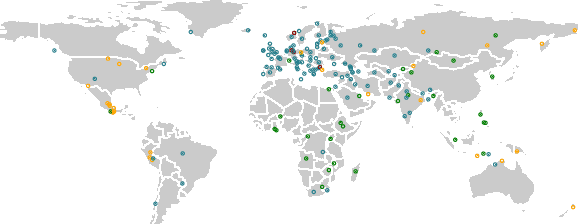

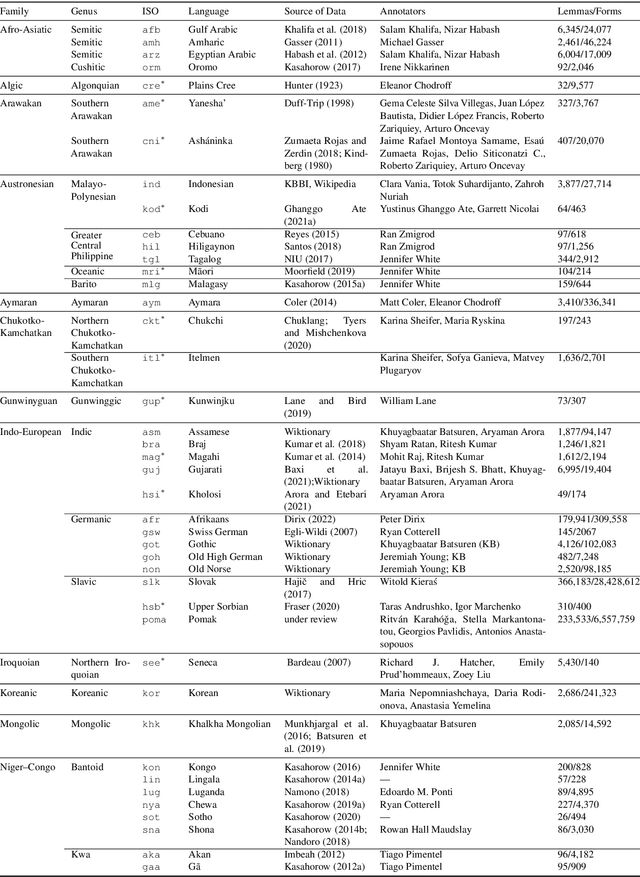
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Using Linguistic Typology to Enrich Multilingual Lexicons: the Case of Lexical Gaps in Kinship
Apr 11, 2022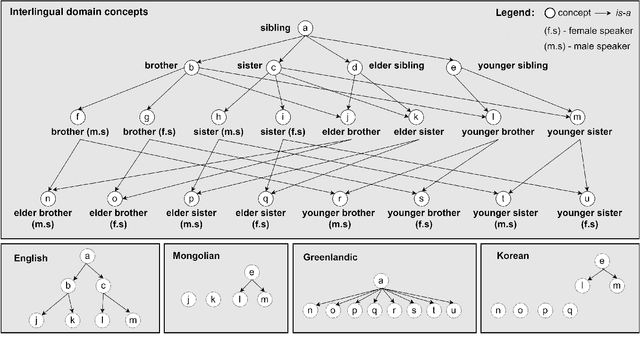
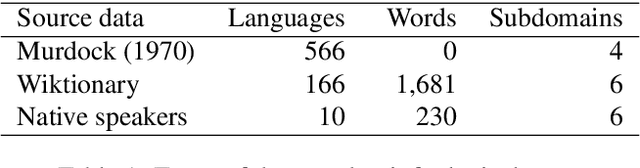
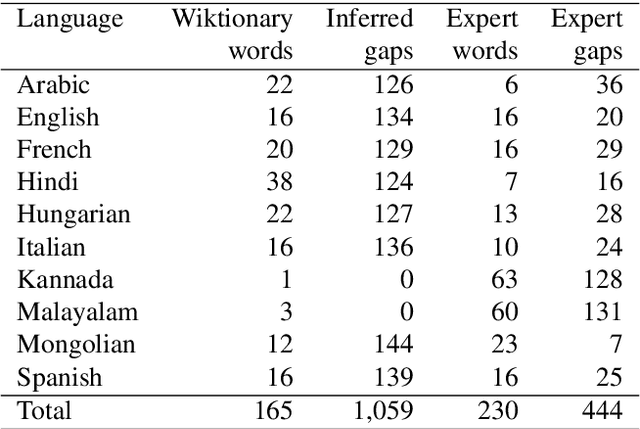

This paper describes a method to enrich lexical resources with content relating to linguistic diversity, based on knowledge from the field of lexical typology. We capture the phenomenon of diversity through the notions of lexical gap and language-specific word and use a systematic method to infer gaps semi-automatically on a large scale. As a first result obtained for the domain of kinship terminology, known to be very diverse throughout the world, we publish a lexico-semantic resource consisting of 198 domain concepts, 1,911 words, and 37,370 gaps covering 699 languages. We see potential in the use of resources such as ours for the improvement of a variety of cross-lingual NLP tasks, which we demonstrate through a downstream application for the evaluation of machine translation systems.
Language Diversity: Visible to Humans, Exploitable by Machines
Mar 09, 2022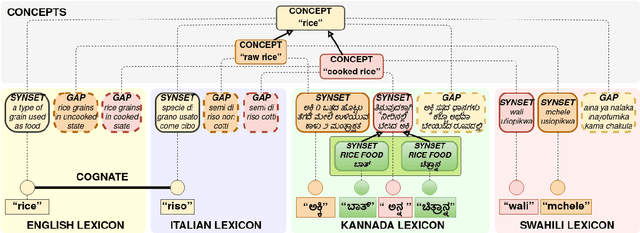

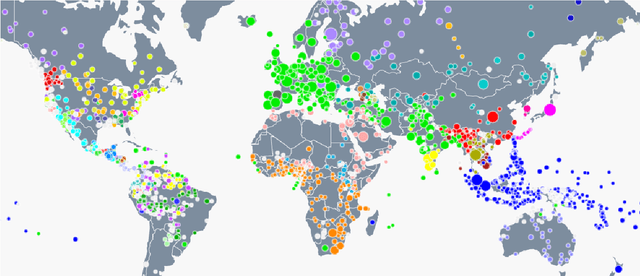
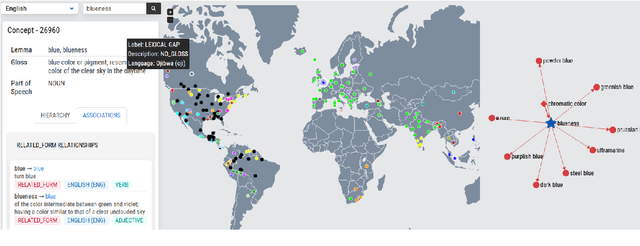
The Universal Knowledge Core (UKC) is a large multilingual lexical database with a focus on language diversity and covering over a thousand languages. The aim of the database, as well as its tools and data catalogue, is to make the somewhat abstract notion of diversity visually understandable for humans and formally exploitable by machines. The UKC website lets users explore millions of individual words and their meanings, but also phenomena of cross-lingual convergence and divergence, such as shared interlingual meanings, lexicon similarities, cognate clusters, or lexical gaps. The UKC LiveLanguage Catalogue, in turn, provides access to the underlying lexical data in a computer-processable form, ready to be reused in cross-lingual applications.