 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Interoperable Electronic Health Records as Purpose-Driven Knowledge Graphs
May 10, 2023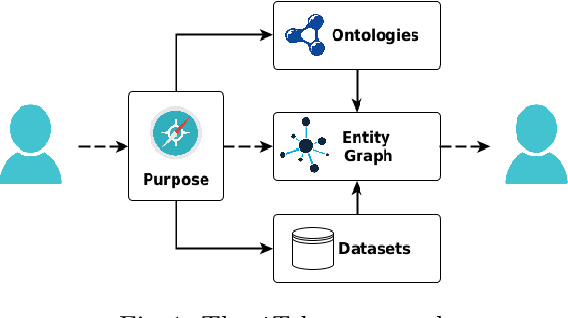

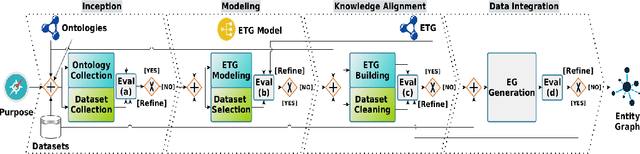

When building a new application we are increasingly confronted with the need of reusing and integrating pre-existing knowledge. Nevertheless, it is a fact that this prior knowledge is virtually impossible to reuse as-is. This is true also in domains, e.g., eHealth, where a lot of effort has been put into developing high-quality standards and reference ontologies, e.g. FHIR1. In this paper, we propose an integrated methodology, called iTelos, which enables data and knowledge reuse towards the construction of Interoperable Electronic Health Records (iEHR). The key intuition is that the data level and the schema level of an application should be developed independently, thus allowing for maximum flexibility in the reuse of the prior knowledge, but under the overall guidance of the needs to be satisfied, formalized as competence queries. This intuition is implemented by codifying all the requirements, including those concerning reuse, as part of a purpose defined a priori, which is then used to drive a middle-out development process where the application schema and data are continuously aligned. The proposed methodology is validated through its application to a large-scale case study.
* DSAI SPRINGER BOOK. arXiv admin note: text overlap with arXiv:2105.09418
Using Linguistic Typology to Enrich Multilingual Lexicons: the Case of Lexical Gaps in Kinship
Apr 11, 2022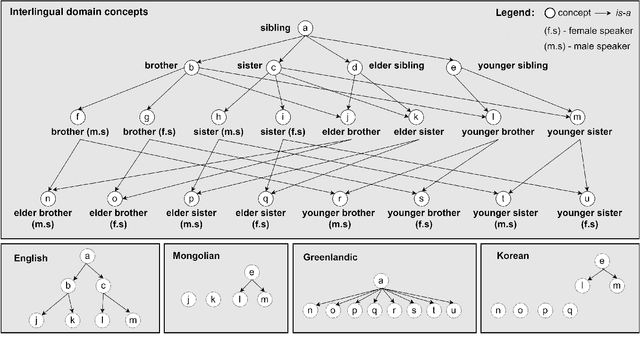
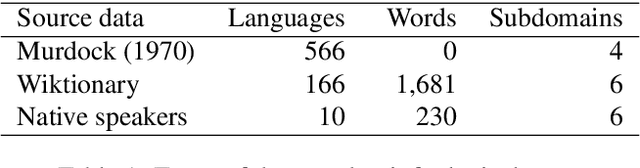
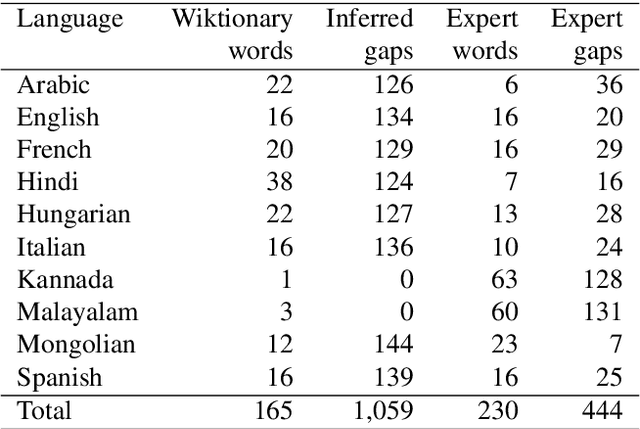

This paper describes a method to enrich lexical resources with content relating to linguistic diversity, based on knowledge from the field of lexical typology. We capture the phenomenon of diversity through the notions of lexical gap and language-specific word and use a systematic method to infer gaps semi-automatically on a large scale. As a first result obtained for the domain of kinship terminology, known to be very diverse throughout the world, we publish a lexico-semantic resource consisting of 198 domain concepts, 1,911 words, and 37,370 gaps covering 699 languages. We see potential in the use of resources such as ours for the improvement of a variety of cross-lingual NLP tasks, which we demonstrate through a downstream application for the evaluation of machine translation systems.
Language Diversity: Visible to Humans, Exploitable by Machines
Mar 09, 2022

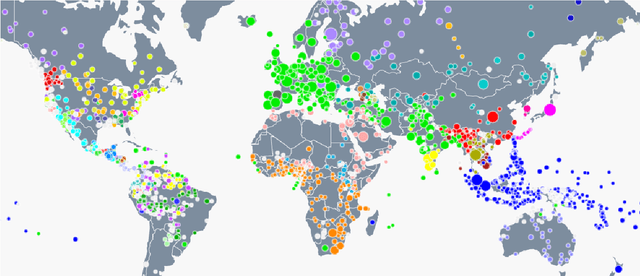
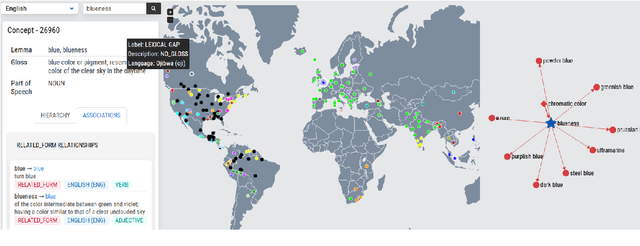
The Universal Knowledge Core (UKC) is a large multilingual lexical database with a focus on language diversity and covering over a thousand languages. The aim of the database, as well as its tools and data catalogue, is to make the somewhat abstract notion of diversity visually understandable for humans and formally exploitable by machines. The UKC website lets users explore millions of individual words and their meanings, but also phenomena of cross-lingual convergence and divergence, such as shared interlingual meanings, lexicon similarities, cognate clusters, or lexical gaps. The UKC LiveLanguage Catalogue, in turn, provides access to the underlying lexical data in a computer-processable form, ready to be reused in cross-lingual applications.