 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Interlingual Meaning in Lexical Databases
Jan 22, 2023In today's multilingual lexical databases, the majority of the world's languages are under-represented. Beyond a mere issue of resource incompleteness, we show that existing lexical databases have structural limitations that result in a reduced expressivity on culturally-specific words and in mapping them across languages. In particular, the lexical meaning space of dominant languages, such as English, is represented more accurately while linguistically or culturally diverse languages are mapped in an approximate manner. Our paper assesses state-of-the-art multilingual lexical databases and evaluates their strengths and limitations with respect to their expressivity on lexical phenomena of linguistic diversity.
Using Linguistic Typology to Enrich Multilingual Lexicons: the Case of Lexical Gaps in Kinship
Apr 11, 2022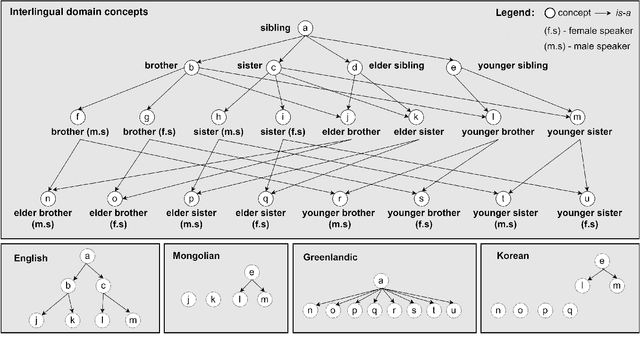
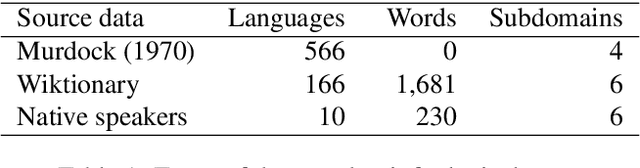
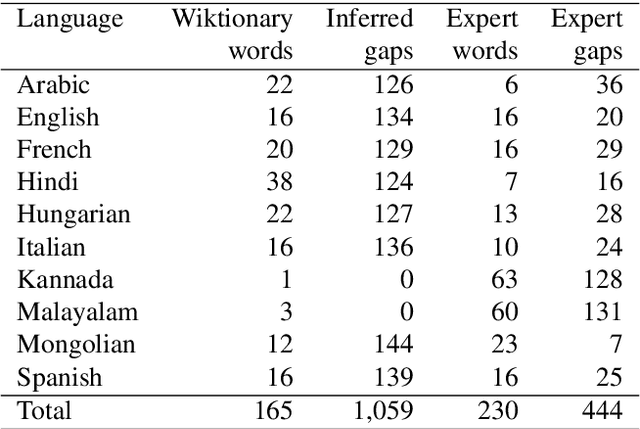

This paper describes a method to enrich lexical resources with content relating to linguistic diversity, based on knowledge from the field of lexical typology. We capture the phenomenon of diversity through the notions of lexical gap and language-specific word and use a systematic method to infer gaps semi-automatically on a large scale. As a first result obtained for the domain of kinship terminology, known to be very diverse throughout the world, we publish a lexico-semantic resource consisting of 198 domain concepts, 1,911 words, and 37,370 gaps covering 699 languages. We see potential in the use of resources such as ours for the improvement of a variety of cross-lingual NLP tasks, which we demonstrate through a downstream application for the evaluation of machine translation systems.