 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing of Real-world Image Annotation via Visual Properties
Apr 15, 2026Recent advances in data-centric artificial intelligence highlight inherent limitations in object recognition datasets. One of the primary issues stems from the semantic gap problem, which results in complex many-to-many mappings between visual data and linguistic descriptions. This bias adversely affects performance in computer vision tasks. This paper proposes an image annotation methodology that integrates knowledge representation, natural language processing, and computer vision techniques, aiming to reduce annotator subjectivity by applying visual property constraints. We introduce an interactive crowdsourcing framework that dynamically asks questions based on a predefined object category hierarchy and annotator feedback, guiding image annotation by visual properties. Experiments demonstrate the effectiveness of this methodology, and annotator feedback is discussed to optimize the crowdsourcing setup.
What can Computer Vision learn from Ranganathan?
Jan 30, 2026The Semantic Gap Problem (SGP) in Computer Vision (CV) arises from the misalignment between visual and lexical semantics leading to flawed CV dataset design and CV benchmarks. This paper proposes that classification principles of S.R. Ranganathan can offer a principled starting point to address SGP and design high-quality CV datasets. We elucidate how these principles, suitably adapted, underpin the vTelos CV annotation methodology. The paper also briefly presents experimental evidence showing improvements in CV annotation and accuracy, thereby, validating vTelos.
Understanding Gen Alpha Digital Language: Evaluation of LLM Safety Systems for Content Moderation
May 14, 2025This research offers a unique evaluation of how AI systems interpret the digital language of Generation Alpha (Gen Alpha, born 2010-2024). As the first cohort raised alongside AI, Gen Alpha faces new forms of online risk due to immersive digital engagement and a growing mismatch between their evolving communication and existing safety tools. Their distinct language, shaped by gaming, memes, and AI-driven trends, often conceals harmful interactions from both human moderators and automated systems. We assess four leading AI models (GPT-4, Claude, Gemini, and Llama 3) on their ability to detect masked harassment and manipulation within Gen Alpha discourse. Using a dataset of 100 recent expressions from gaming platforms, social media, and video content, the study reveals critical comprehension failures with direct implications for online safety. This work contributes: (1) a first-of-its-kind dataset capturing Gen Alpha expressions; (2) a framework to improve AI moderation systems for youth protection; (3) a multi-perspective evaluation including AI systems, human moderators, and parents, with direct input from Gen Alpha co-researchers; and (4) an analysis of how linguistic divergence increases youth vulnerability. Findings highlight the urgent need to redesign safety systems attuned to youth communication, especially given Gen Alpha reluctance to seek help when adults fail to understand their digital world. This study combines the insight of a Gen Alpha researcher with systematic academic analysis to address critical digital safety challenges.
Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks
Feb 19, 2025



Graph neural networks have been demonstrated as a powerful paradigm for effectively learning graph-structured data on the web and mining content from it.Current leading graph models require a large number of labeled samples for training, which unavoidably leads to overfitting in few-shot scenarios. Recent research has sought to alleviate this issue by simultaneously leveraging graph learning and meta-learning paradigms. However, these graph meta-learning models assume the availability of numerous meta-training tasks to learn transferable meta-knowledge. Such assumption may not be feasible in the real world due to the difficulty of constructing tasks and the substantial costs involved. Therefore, we propose a SiMple yet effectIve approach for graph few-shot Learning with fEwer tasks, named SMILE. We introduce a dual-level mixup strategy, encompassing both within-task and across-task mixup, to simultaneously enrich the available nodes and tasks in meta-learning. Moreover, we explicitly leverage the prior information provided by the node degrees in the graph to encode expressive node representations. Theoretically, we demonstrate that SMILE can enhance the model generalization ability. Empirically, SMILE consistently outperforms other competitive models by a large margin across all evaluated datasets with in-domain and cross-domain settings. Our anonymous code can be found here.
Boosting Short Text Classification with Multi-Source Information Exploration and Dual-Level Contrastive Learning
Jan 16, 2025



Short text classification, as a research subtopic in natural language processing, is more challenging due to its semantic sparsity and insufficient labeled samples in practical scenarios. We propose a novel model named MI-DELIGHT for short text classification in this work. Specifically, it first performs multi-source information (i.e., statistical information, linguistic information, and factual information) exploration to alleviate the sparsity issues. Then, the graph learning approach is adopted to learn the representation of short texts, which are presented in graph forms. Moreover, we introduce a dual-level (i.e., instance-level and cluster-level) contrastive learning auxiliary task to effectively capture different-grained contrastive information within massive unlabeled data. Meanwhile, previous models merely perform the main task and auxiliary tasks in parallel, without considering the relationship among tasks. Therefore, we introduce a hierarchical architecture to explicitly model the correlations between tasks. We conduct extensive experiments across various benchmark datasets, demonstrating that MI-DELIGHT significantly surpasses previous competitive models. It even outperforms popular large language models on several datasets.
A Simple Graph Contrastive Learning Framework for Short Text Classification
Jan 16, 2025



Short text classification has gained significant attention in the information age due to its prevalence and real-world applications. Recent advancements in graph learning combined with contrastive learning have shown promising results in addressing the challenges of semantic sparsity and limited labeled data in short text classification. However, existing models have certain limitations. They rely on explicit data augmentation techniques to generate contrastive views, resulting in semantic corruption and noise. Additionally, these models only focus on learning the intrinsic consistency between the generated views, neglecting valuable discriminative information from other potential views. To address these issues, we propose a Simple graph contrastive learning framework for Short Text Classification (SimSTC). Our approach involves performing graph learning on multiple text-related component graphs to obtain multi-view text embeddings. Subsequently, we directly apply contrastive learning on these embeddings. Notably, our method eliminates the need for data augmentation operations to generate contrastive views while still leveraging the benefits of multi-view contrastive learning. Despite its simplicity, our model achieves outstanding performance, surpassing large language models on various datasets.
Enhancing Unsupervised Graph Few-shot Learning via Set Functions and Optimal Transport
Jan 10, 2025



Graph few-shot learning has garnered significant attention for its ability to rapidly adapt to downstream tasks with limited labeled data, sparking considerable interest among researchers. Recent advancements in graph few-shot learning models have exhibited superior performance across diverse applications. Despite their successes, several limitations still exist. First, existing models in the meta-training phase predominantly focus on instance-level features within tasks, neglecting crucial set-level features essential for distinguishing between different categories. Second, these models often utilize query sets directly on classifiers trained with support sets containing only a few labeled examples, overlooking potential distribution shifts between these sets and leading to suboptimal performance. Finally, previous models typically require necessitate abundant labeled data from base classes to extract transferable knowledge, which is typically infeasible in real-world scenarios. To address these issues, we propose a novel model named STAR, which leverages Set funcTions and optimAl tRansport for enhancing unsupervised graph few-shot learning. Specifically, STAR utilizes expressive set functions to obtain set-level features in an unsupervised manner and employs optimal transport principles to align the distributions of support and query sets, thereby mitigating distribution shift effects. Theoretical analysis demonstrates that STAR can capture more task-relevant information and enhance generalization capabilities. Empirically, extensive experiments across multiple datasets validate the effectiveness of STAR. Our code can be found here.
Shortcut Learning in In-Context Learning: A Survey
Nov 04, 2024
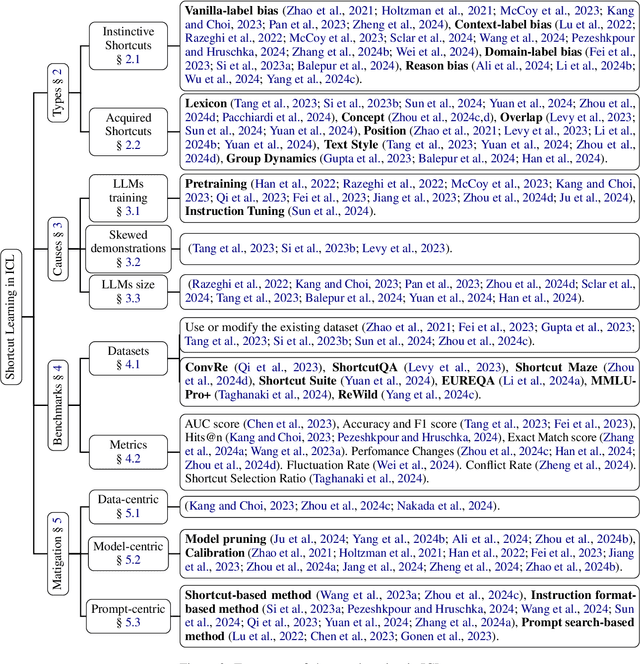
Shortcut learning refers to the phenomenon where models employ simple, non-robust decision rules in practical tasks, which hinders their generalization and robustness. With the rapid development of large language models (LLMs) in recent years, an increasing number of studies have shown the impact of shortcut learning on LLMs. This paper provides a novel perspective to review relevant research on shortcut learning in In-Context Learning (ICL). It conducts a detailed exploration of the types of shortcuts in ICL tasks, their causes, available benchmarks, and strategies for mitigating shortcuts. Based on corresponding observations, it summarizes the unresolved issues in existing research and attempts to outline the future research landscape of shortcut learning.
Crowdsourcing Lexical Diversity
Oct 30, 2024



Lexical-semantic resources (LSRs), such as online lexicons or wordnets, are fundamental for natural language processing applications. In many languages, however, such resources suffer from quality issues: incorrect entries, incompleteness, but also, the rarely addressed issue of bias towards the English language and Anglo-Saxon culture. Such bias manifests itself in the absence of concepts specific to the language or culture at hand, the presence of foreign (Anglo-Saxon) concepts, as well as in the lack of an explicit indication of untranslatability, also known as cross-lingual \emph{lexical gaps}, when a term has no equivalent in another language. This paper proposes a novel crowdsourcing methodology for reducing bias in LSRs. Crowd workers compare lexemes from two languages, focusing on domains rich in lexical diversity, such as kinship or food. Our LingoGap crowdsourcing tool facilitates comparisons through microtasks identifying equivalent terms, language-specific terms, and lexical gaps across languages. We validated our method by applying it to two case studies focused on food-related terminology: (1) English and Arabic, and (2) Standard Indonesian and Banjarese. These experiments identified 2,140 lexical gaps in the first case study and 951 in the second. The success of these experiments confirmed the usability of our method and tool for future large-scale lexicon enrichment tasks.
Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training
Jul 20, 2024



Node classification is an essential problem in graph learning. However, many models typically obtain unsatisfactory performance when applied to few-shot scenarios. Some studies have attempted to combine meta-learning with graph neural networks to solve few-shot node classification on graphs. Despite their promising performance, some limitations remain. First, they employ the node encoding mechanism of homophilic graphs to learn node embeddings, even in heterophilic graphs. Second, existing models based on meta-learning ignore the interference of randomness in the learning process. Third, they are trained using only limited labeled nodes within the specific task, without explicitly utilizing numerous unlabeled nodes. Finally, they treat almost all sampled tasks equally without customizing them for their uniqueness. To address these issues, we propose a novel framework for few-shot node classification called Meta-GPS++. Specifically, we first adopt an efficient method to learn discriminative node representations on homophilic and heterophilic graphs. Then, we leverage a prototype-based approach to initialize parameters and contrastive learning for regularizing the distribution of node embeddings. Moreover, we apply self-training to extract valuable information from unlabeled nodes. Additionally, we adopt S$^2$ (scaling & shifting) transformation to learn transferable knowledge from diverse tasks. The results on real-world datasets show the superiority of Meta-GPS++. Our code is available here.